 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
MoMu-Diffusion: On Learning Long-Term Motion-Music Synchronization and Correspondence
Nov 04, 2024



Motion-to-music and music-to-motion have been studied separately, each attracting substantial research interest within their respective domains. The interaction between human motion and music is a reflection of advanced human intelligence, and establishing a unified relationship between them is particularly important. However, to date, there has been no work that considers them jointly to explore the modality alignment within. To bridge this gap, we propose a novel framework, termed MoMu-Diffusion, for long-term and synchronous motion-music generation. Firstly, to mitigate the huge computational costs raised by long sequences, we propose a novel Bidirectional Contrastive Rhythmic Variational Auto-Encoder (BiCoR-VAE) that extracts the modality-aligned latent representations for both motion and music inputs. Subsequently, leveraging the aligned latent spaces, we introduce a multi-modal Transformer-based diffusion model and a cross-guidance sampling strategy to enable various generation tasks, including cross-modal, multi-modal, and variable-length generation. Extensive experiments demonstrate that MoMu-Diffusion surpasses recent state-of-the-art methods both qualitatively and quantitatively, and can synthesize realistic, diverse, long-term, and beat-matched music or motion sequences. The generated samples and codes are available at https://momu-diffusion.github.io/
Frieren: Efficient Video-to-Audio Generation with Rectified Flow Matching
Jun 01, 2024



Video-to-audio (V2A) generation aims to synthesize content-matching audio from silent video, and it remains challenging to build V2A models with high generation quality, efficiency, and visual-audio temporal synchrony. We propose Frieren, a V2A model based on rectified flow matching. Frieren regresses the conditional transport vector field from noise to spectrogram latent with straight paths and conducts sampling by solving ODE, outperforming autoregressive and score-based models in terms of audio quality. By employing a non-autoregressive vector field estimator based on a feed-forward transformer and channel-level cross-modal feature fusion with strong temporal alignment, our model generates audio that is highly synchronized with the input video. Furthermore, through reflow and one-step distillation with guided vector field, our model can generate decent audio in a few, or even only one sampling step. Experiments indicate that Frieren achieves state-of-the-art performance in both generation quality and temporal alignment on VGGSound, with alignment accuracy reaching 97.22%, and 6.2% improvement in inception score over the strong diffusion-based baseline. Audio samples are available at http://frieren-v2a.github.io .
Text-to-Song: Towards Controllable Music Generation Incorporating Vocals and Accompaniment
Apr 16, 2024A song is a combination of singing voice and accompaniment. However, existing works focus on singing voice synthesis and music generation independently. Little attention was paid to explore song synthesis. In this work, we propose a novel task called text-to-song synthesis which incorporating both vocals and accompaniments generation. We develop Melodist, a two-stage text-to-song method that consists of singing voice synthesis (SVS) and vocal-to-accompaniment (V2A) synthesis. Melodist leverages tri-tower contrastive pretraining to learn more effective text representation for controllable V2A synthesis. A Chinese song dataset mined from a music website is built up to alleviate data scarcity for our research. The evaluation results on our dataset demonstrate that Melodist can synthesize songs with comparable quality and style consistency. Audio samples can be found in https://text2songMelodist.github.io/Sample/.
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
Mar 18, 2024



Recent singing-voice-synthesis (SVS) methods have achieved remarkable audio quality and naturalness, yet they lack the capability to control the style attributes of the synthesized singing explicitly. We propose Prompt-Singer, the first SVS method that enables attribute controlling on singer gender, vocal range and volume with natural language. We adopt a model architecture based on a decoder-only transformer with a multi-scale hierarchy, and design a range-melody decoupled pitch representation that enables text-conditioned vocal range control while keeping melodic accuracy. Furthermore, we explore various experiment settings, including different types of text representations, text encoder fine-tuning, and introducing speech data to alleviate data scarcity, aiming to facilitate further research. Experiments show that our model achieves favorable controlling ability and audio quality. Audio samples are available at http://prompt-singer.github.io .
Domain Adaptive Semantic Segmentation without Source Data
Oct 13, 2021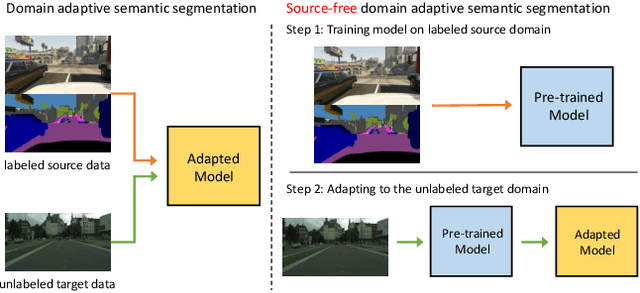
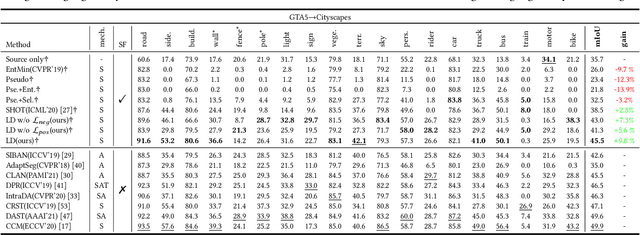
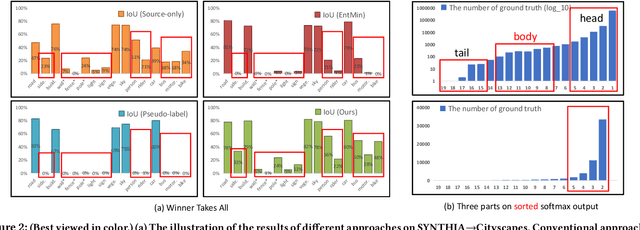
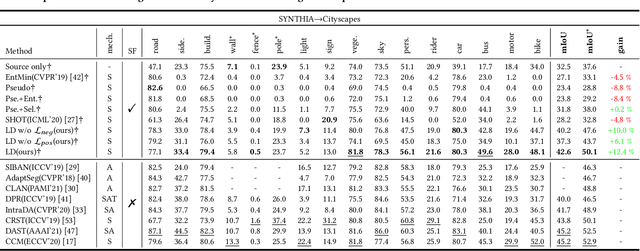
Domain adaptive semantic segmentation is recognized as a promising technique to alleviate the domain shift between the labeled source domain and the unlabeled target domain in many real-world applications, such as automatic pilot. However, large amounts of source domain data often introduce significant costs in storage and training, and sometimes the source data is inaccessible due to privacy policies. To address these problems, we investigate domain adaptive semantic segmentation without source data, which assumes that the model is pre-trained on the source domain, and then adapting to the target domain without accessing source data anymore. Since there is no supervision from the source domain data, many self-training methods tend to fall into the ``winner-takes-all'' dilemma, where the {\it majority} classes totally dominate the segmentation networks and the networks fail to classify the {\it minority} classes. Consequently, we propose an effective framework for this challenging problem with two components: positive learning and negative learning. In positive learning, we select the class-balanced pseudo-labeled pixels with intra-class threshold, while in negative learning, for each pixel, we investigate which category the pixel does not belong to with the proposed heuristic complementary label selection. Notably, our framework can be easily implemented and incorporated with other methods to further enhance the performance. Extensive experiments on two widely-used synthetic-to-real benchmarks demonstrate our claims and the effectiveness of our framework, which outperforms the baseline with a large margin. Code is available at \url{https://github.com/fumyou13/LDBE}.
Test-time Batch Statistics Calibration for Covariate Shift
Oct 06, 2021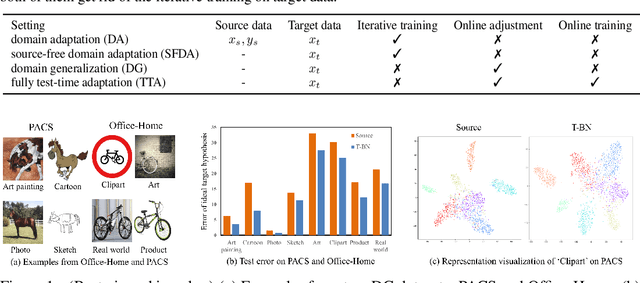

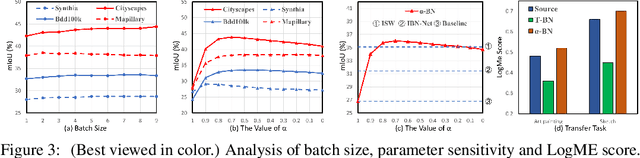
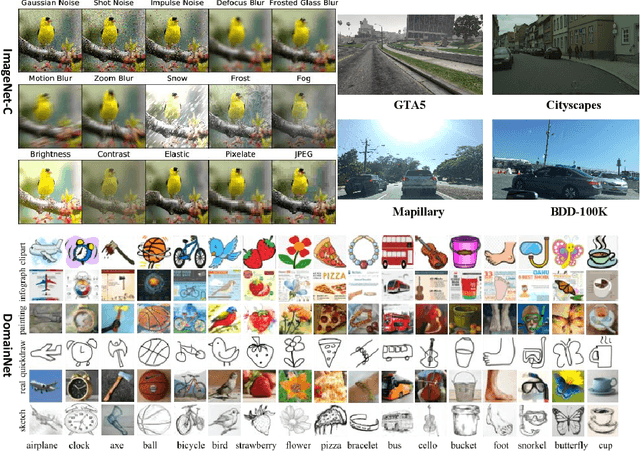
Deep neural networks have a clear degradation when applying to the unseen environment due to the covariate shift. Conventional approaches like domain adaptation requires the pre-collected target data for iterative training, which is impractical in real-world applications. In this paper, we propose to adapt the deep models to the novel environment during inference. An previous solution is test time normalization, which substitutes the source statistics in BN layers with the target batch statistics. However, we show that test time normalization may potentially deteriorate the discriminative structures due to the mismatch between target batch statistics and source parameters. To this end, we present a general formulation $\alpha$-BN to calibrate the batch statistics by mixing up the source and target statistics for both alleviating the domain shift and preserving the discriminative structures. Based on $\alpha$-BN, we further present a novel loss function to form a unified test time adaptation framework Core, which performs the pairwise class correlation online optimization. Extensive experiments show that our approaches achieve the state-of-the-art performance on total twelve datasets from three topics, including model robustness to corruptions, domain generalization on image classification and semantic segmentation. Particularly, our $\alpha$-BN improves 28.4\% to 43.9\% on GTA5 $\rightarrow$ Cityscapes without any training, even outperforms the latest source-free domain adaptation method.