 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJRM: Joint Reconstruction Model for Multiple Objects without Alignment
Mar 27, 2026Object-centric reconstruction seeks to recover the 3D structure of a scene through composition of independent objects. While this independence can simplify modeling, it discards strong signals that could improve reconstruction, notably repetition where the same object model is seen multiple times in a scene, or across scans. We propose the Joint Reconstruction Model (JRM) to leverage repetition by framing object reconstruction as one of personalized generation: multiple observations share a common subject that should be consistent for all observations, while still adhering to the specific pose and state from each. Prior methods in this direction rely on explicit matching and rigid alignment across observations, making them sensitive to errors and difficult to extend to non-rigid transformations. In contrast, JRM is a 3D flow-matching generative model that implicitly aggregates unaligned observations in its latent space, learning to produce consistent and faithful reconstructions in a data-driven manner without explicit constraints. Evaluations on synthetic and real-world data show that JRM's implicit aggregation removes the need for explicit alignment, improves robustness to incorrect associations, and naturally handles non-rigid changes such as articulation. Overall, JRM outperforms both independent and alignment-based baselines in reconstruction quality.
ShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
VertexRegen: Mesh Generation with Continuous Level of Detail
Aug 12, 2025We introduce VertexRegen, a novel mesh generation framework that enables generation at a continuous level of detail. Existing autoregressive methods generate meshes in a partial-to-complete manner and thus intermediate steps of generation represent incomplete structures. VertexRegen takes inspiration from progressive meshes and reformulates the process as the reversal of edge collapse, i.e. vertex split, learned through a generative model. Experimental results demonstrate that VertexRegen produces meshes of comparable quality to state-of-the-art methods while uniquely offering anytime generation with the flexibility to halt at any step to yield valid meshes with varying levels of detail.
Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling
Mar 14, 2025We present a novel human-in-the-loop approach to estimate 3D scene layout that uses human feedback from an egocentric standpoint. We study this approach through introduction of a novel local correction task, where users identify local errors and prompt a model to automatically correct them. Building on SceneScript, a state-of-the-art framework for 3D scene layout estimation that leverages structured language, we propose a solution that structures this problem as "infilling", a task studied in natural language processing. We train a multi-task version of SceneScript that maintains performance on global predictions while significantly improving its local correction ability. We integrate this into a human-in-the-loop system, enabling a user to iteratively refine scene layout estimates via a low-friction "one-click fix'' workflow. Our system enables the final refined layout to diverge from the training distribution, allowing for more accurate modelling of complex layouts.
SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024



We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
ReplaceAnything3D:Text-Guided 3D Scene Editing with Compositional Neural Radiance Fields
Jan 31, 2024We introduce ReplaceAnything3D model (RAM3D), a novel text-guided 3D scene editing method that enables the replacement of specific objects within a scene. Given multi-view images of a scene, a text prompt describing the object to replace, and a text prompt describing the new object, our Erase-and-Replace approach can effectively swap objects in the scene with newly generated content while maintaining 3D consistency across multiple viewpoints. We demonstrate the versatility of ReplaceAnything3D by applying it to various realistic 3D scenes, showcasing results of modified foreground objects that are well-integrated with the rest of the scene without affecting its overall integrity.
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.
SceneCAD: Predicting Object Alignments and Layouts in RGB-D Scans
Mar 27, 2020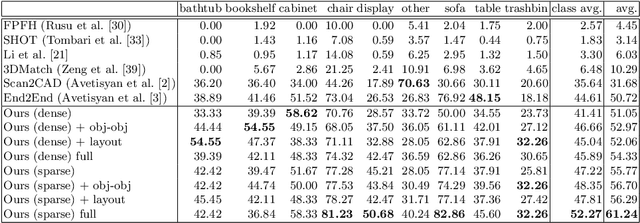
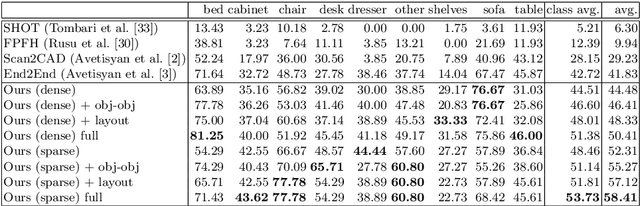
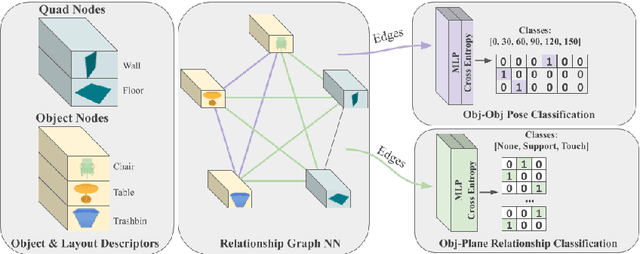
We present a novel approach to reconstructing lightweight, CAD-based representations of scanned 3D environments from commodity RGB-D sensors. Our key idea is to jointly optimize for both CAD model alignments as well as layout estimations of the scanned scene, explicitly modeling inter-relationships between objects-to-objects and objects-to-layout. Since object arrangement and scene layout are intrinsically coupled, we show that treating the problem jointly significantly helps to produce globally-consistent representations of a scene. Object CAD models are aligned to the scene by establishing dense correspondences between geometry, and we introduce a hierarchical layout prediction approach to estimate layout planes from corners and edges of the scene.To this end, we propose a message-passing graph neural network to model the inter-relationships between objects and layout, guiding generation of a globally object alignment in a scene. By considering the global scene layout, we achieve significantly improved CAD alignments compared to state-of-the-art methods, improving from 41.83% to 58.41% alignment accuracy on SUNCG and from 50.05% to 61.24% on ScanNet, respectively. The resulting CAD-based representations makes our method well-suited for applications in content creation such as augmented- or virtual reality.
RIO: 3D Object Instance Re-Localization in Changing Indoor Environments
Aug 16, 2019
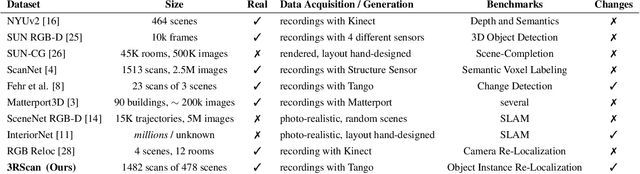

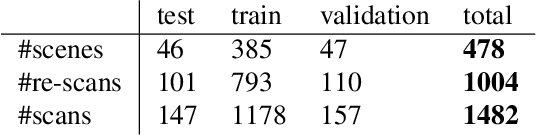
In this work, we introduce the task of 3D object instance re-localization (RIO): given one or multiple objects in an RGB-D scan, we want to estimate their corresponding 6DoF poses in another 3D scan of the same environment taken at a later point in time. We consider RIO a particularly important task in 3D vision since it enables a wide range of practical applications, including AI-assistants or robots that are asked to find a specific object in a 3D scene. To address this problem, we first introduce 3RScan, a novel dataset and benchmark, which features 1482 RGB-D scans of 478 environments across multiple time steps. Each scene includes several objects whose positions change over time, together with ground truth annotations of object instances and their respective 6DoF mappings among re-scans. Automatically finding 6DoF object poses leads to a particular challenging feature matching task due to varying partial observations and changes in the surrounding context. To this end, we introduce a new data-driven approach that efficiently finds matching features using a fully-convolutional 3D correspondence network operating on multiple spatial scales. Combined with a 6DoF pose optimization, our method outperforms state-of-the-art baselines on our newly-established benchmark, achieving an accuracy of 30.58%.
End-to-End CAD Model Retrieval and 9DoF Alignment in 3D Scans
Jun 10, 2019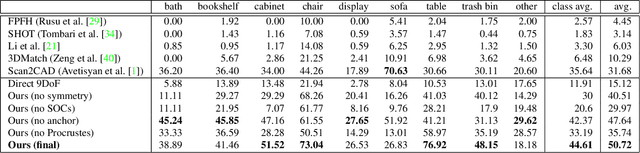
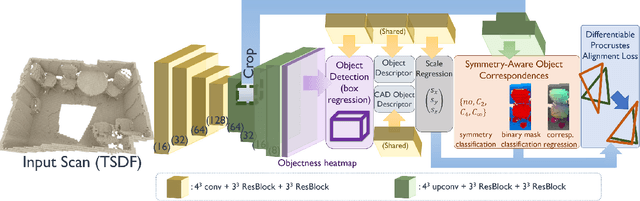


We present a novel, end-to-end approach to align CAD models to an 3D scan of a scene, enabling transformation of a noisy, incomplete 3D scan to a compact, CAD reconstruction with clean, complete object geometry. Our main contribution lies in formulating a differentiable Procrustes alignment that is paired with a symmetry-aware dense object correspondence prediction. To simultaneously align CAD models to all the objects of a scanned scene, our approach detects object locations, then predicts symmetry-aware dense object correspondences between scan and CAD geometry in a unified object space, as well as a nearest neighbor CAD model, both of which are then used to inform a differentiable Procrustes alignment. Our approach operates in a fully-convolutional fashion, enabling alignment of CAD models to the objects of a scan in a single forward pass. This enables our method to outperform state-of-the-art approaches by $19.04\%$ for CAD model alignment to scans, with $\approx 250\times$ faster runtime than previous data-driven approaches.