 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Decoder Scaling Strategy for Neural Routing Solvers
Feb 28, 2026Construction-based neural routing solvers, typically composed of an encoder and a decoder, have emerged as a promising approach for solving vehicle routing problems. While recent studies suggest that shifting parameters from the encoder to the decoder enhances performance, most works restrict the decoder size to 1-3M parameters, leaving the effects of scaling largely unexplored. To address this gap, we conduct a systematic study comparing two distinct strategies: scaling depth versus scaling width. We synthesize these strategies to construct a suite of 12 model configurations, spanning a parameter range from 1M to ~150M, and extensively evaluate their scaling behaviors across three critical dimensions: parameter efficiency, data efficiency, and compute efficiency. Our empirical results reveal that parameter count is insufficient to accurately predict the model performance, highlighting the critical and distinct roles of model depth (layer count) and width (embedding dimension). Crucially, we demonstrate that scaling depth yields superior performance gains to scaling width. Based on these findings, we provide and experimentally validate a set of design principles for the efficient allocation of parameters and compute resources to enhance the model performance.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024



Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Binary stochasticity enabled highly efficient neuromorphic deep learning achieves better-than-software accuracy
Apr 25, 2023Deep learning needs high-precision handling of forwarding signals, backpropagating errors, and updating weights. This is inherently required by the learning algorithm since the gradient descent learning rule relies on the chain product of partial derivatives. However, it is challenging to implement deep learning in hardware systems that use noisy analog memristors as artificial synapses, as well as not being biologically plausible. Memristor-based implementations generally result in an excessive cost of neuronal circuits and stringent demands for idealized synaptic devices. Here, we demonstrate that the requirement for high precision is not necessary and that more efficient deep learning can be achieved when this requirement is lifted. We propose a binary stochastic learning algorithm that modifies all elementary neural network operations, by introducing (i) stochastic binarization of both the forwarding signals and the activation function derivatives, (ii) signed binarization of the backpropagating errors, and (iii) step-wised weight updates. Through an extensive hybrid approach of software simulation and hardware experiments, we find that binary stochastic deep learning systems can provide better performance than the software-based benchmarks using the high-precision learning algorithm. Also, the binary stochastic algorithm strongly simplifies the neural network operations in hardware, resulting in an improvement of the energy efficiency for the multiply-and-accumulate operations by more than three orders of magnitudes.
Multi-UAV Coverage Planning with Limited Endurance in Disaster Environment
Jan 25, 2022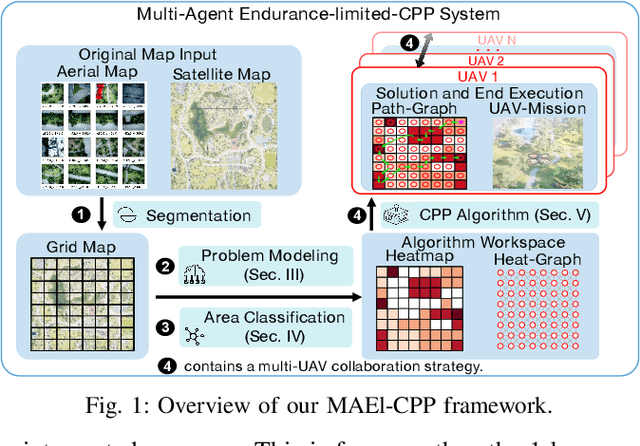
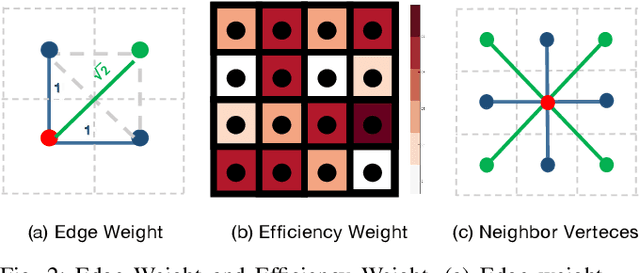
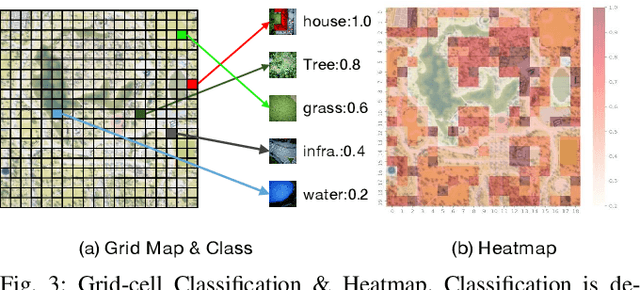

For scenes such as floods and earthquakes, the disaster area is large, and rescue time is tight. Multi-UAV exploration is more efficient than a single UAV. Existing UAV exploration work is modeled as a Coverage Path Planning (CPP) task to achieve full coverage of the area in the presence of obstacles. However, the endurance capability of UAV is limited, and the rescue time is urgent. Thus, even using multiple UAVs cannot achieve complete disaster area coverage in time. Therefore, in this paper we propose a multi-Agent Endurance-limited CPP (MAEl-CPP) problem based on a priori heatmap of the disaster area, which requires the exploration of more valuable areas under limited energy. Furthermore, we propose a path planning algorithm for the MAEl-CPP problem, by ranking the possible disaster areas according to their importance through satellite or remote aerial images and completing path planning according to the importance level. Experimental results show that our proposed algorithm is at least twice as effective as the existing method in terms of search efficiency.