 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes VLA Even Know the Basics? Measuring Commonsense and World Knowledge Retention in Vision-Language-Action Models
Jun 17, 2026Embodied Vision-Language-Action (VLA) models are typically obtained by fine-tuning powerful pretrained VLMs on robotics data, yet it is unclear how much commonsense and factual knowledge they retain after adaptation. Failures on knowledge-sensitive tasks are ambiguous, conflating missing knowledge with poor generalization of low-level control. We introduce Act2Answer, a lightweight protocol that adapts VLM knowledge benchmarks to VLA evaluation by requiring agents to answer through action. Each question becomes a short tabletop episode where the agent performs a single object-placement action to select among candidate answers, yielding an action-grounded success rate with reduced control confounds. We curate a test suite of such environments across diverse commonsense and world-knowledge categories and introduce layerwise intent probing to localize answer-relevant information across the VLM backbone and action head. In a large-scale study of 7 VLA models and 9 VLM baselines, we systematically rank models across categories, finding that VLAs show solid performance on simple concepts while exhibiting larger gaps on richer semantic categories relative to their source VLMs, that VQA co-training is associated with better knowledge retention, and that answer-relevant signals peak in middle VLA layers but attenuate in upper layers. Act2Answer is available at https://tttonyalpha.github.io/act2answer/.
NTIRE 2026 Challenge on Video Saliency Prediction: Methods and Results
Apr 16, 2026This paper presents an overview of the NTIRE 2026 Challenge on Video Saliency Prediction. The goal of the challenge participants was to develop automatic saliency map prediction methods for the provided video sequences. The novel dataset of 2,000 diverse videos with an open license was prepared for this challenge. The fixations and corresponding saliency maps were collected using crowdsourced mouse tracking and contain viewing data from over 5,000 assessors. Evaluation was performed on a subset of 800 test videos using generally accepted quality metrics. The challenge attracted over 20 teams making submissions, and 7 teams passed the final phase with code review. All data used in this challenge is made publicly available - https://github.com/msu-video-group/NTIRE26_Saliency_Prediction.
BREPS: Bounding-Box Robustness Evaluation of Promptable Segmentation
Jan 21, 2026Promptable segmentation models such as SAM have established a powerful paradigm, enabling strong generalization to unseen objects and domains with minimal user input, including points, bounding boxes, and text prompts. Among these, bounding boxes stand out as particularly effective, often outperforming points while significantly reducing annotation costs. However, current training and evaluation protocols typically rely on synthetic prompts generated through simple heuristics, offering limited insight into real-world robustness. In this paper, we investigate the robustness of promptable segmentation models to natural variations in bounding box prompts. First, we conduct a controlled user study and collect thousands of real bounding box annotations. Our analysis reveals substantial variability in segmentation quality across users for the same model and instance, indicating that SAM-like models are highly sensitive to natural prompt noise. Then, since exhaustive testing of all possible user inputs is computationally prohibitive, we reformulate robustness evaluation as a white-box optimization problem over the bounding box prompt space. We introduce BREPS, a method for generating adversarial bounding boxes that minimize or maximize segmentation error while adhering to naturalness constraints. Finally, we benchmark state-of-the-art models across 10 datasets, spanning everyday scenes to medical imaging. Code - https://github.com/emb-ai/BREPS.
Bring the Apple, Not the Sofa: Impact of Irrelevant Context in Embodied AI Commands on VLA Models
Oct 08, 2025Vision Language Action (VLA) models are widely used in Embodied AI, enabling robots to interpret and execute language instructions. However, their robustness to natural language variability in real-world scenarios has not been thoroughly investigated. In this work, we present a novel systematic study of the robustness of state-of-the-art VLA models under linguistic perturbations. Specifically, we evaluate model performance under two types of instruction noise: (1) human-generated paraphrasing and (2) the addition of irrelevant context. We further categorize irrelevant contexts into two groups according to their length and their semantic and lexical proximity to robot commands. In this study, we observe consistent performance degradation as context size expands. We also demonstrate that the model can exhibit relative robustness to random context, with a performance drop within 10%, while semantically and lexically similar context of the same length can trigger a quality decline of around 50%. Human paraphrases of instructions lead to a drop of nearly 20%. To mitigate this, we propose an LLM-based filtering framework that extracts core commands from noisy inputs. Incorporating our filtering step allows models to recover up to 98.5% of their original performance under noisy conditions.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
RClicks: Realistic Click Simulation for Benchmarking Interactive Segmentation
Oct 15, 2024The emergence of Segment Anything (SAM) sparked research interest in the field of interactive segmentation, especially in the context of image editing tasks and speeding up data annotation. Unlike common semantic segmentation, interactive segmentation methods allow users to directly influence their output through prompts (e.g. clicks). However, click patterns in real-world interactive segmentation scenarios remain largely unexplored. Most methods rely on the assumption that users would click in the center of the largest erroneous area. Nevertheless, recent studies show that this is not always the case. Thus, methods may have poor performance in real-world deployment despite high metrics in a baseline benchmark. To accurately simulate real-user clicks, we conducted a large crowdsourcing study of click patterns in an interactive segmentation scenario and collected 475K real-user clicks. Drawing on ideas from saliency tasks, we develop a clickability model that enables sampling clicks, which closely resemble actual user inputs. Using our model and dataset, we propose RClicks benchmark for a comprehensive comparison of existing interactive segmentation methods on realistic clicks. Specifically, we evaluate not only the average quality of methods, but also the robustness w.r.t. click patterns. According to our benchmark, in real-world usage interactive segmentation models may perform worse than it has been reported in the baseline benchmark, and most of the methods are not robust. We believe that RClicks is a significant step towards creating interactive segmentation methods that provide the best user experience in real-world cases.
Bridging the Gap Between Saliency Prediction and Image Quality Assessment
May 08, 2024Over the past few years, deep neural models have made considerable advances in image quality assessment (IQA). However, the underlying reasons for their success remain unclear, owing to the complex nature of deep neural networks. IQA aims to describe how the human visual system (HVS) works and to create its efficient approximations. On the other hand, Saliency Prediction task aims to emulate HVS via determining areas of visual interest. Thus, we believe that saliency plays a crucial role in human perception. In this work, we conduct an empirical study that reveals the relation between IQA and Saliency Prediction tasks, demonstrating that the former incorporates knowledge of the latter. Moreover, we introduce a novel SACID dataset of saliency-aware compressed images and conduct a large-scale comparison of classic and neural-based IQA methods. All supplementary code and data will be available at the time of publication.
TETRIS: Towards Exploring the Robustness of Interactive Segmentation
Feb 09, 2024Interactive segmentation methods rely on user inputs to iteratively update the selection mask. A click specifying the object of interest is arguably the most simple and intuitive interaction type, and thereby the most common choice for interactive segmentation. However, user clicking patterns in the interactive segmentation context remain unexplored. Accordingly, interactive segmentation evaluation strategies rely more on intuition and common sense rather than empirical studies (e.g., assuming that users tend to click in the center of the area with the largest error). In this work, we conduct a real user study to investigate real user clicking patterns. This study reveals that the intuitive assumption made in the common evaluation strategy may not hold. As a result, interactive segmentation models may show high scores in the standard benchmarks, but it does not imply that they would perform well in a real world scenario. To assess the applicability of interactive segmentation methods, we propose a novel evaluation strategy providing a more comprehensive analysis of a model's performance. To this end, we propose a methodology for finding extreme user inputs by a direct optimization in a white-box adversarial attack on the interactive segmentation model. Based on the performance with such adversarial user inputs, we assess the robustness of interactive segmentation models w.r.t click positions. Besides, we introduce a novel benchmark for measuring the robustness of interactive segmentation, and report the results of an extensive evaluation of dozens of models.
Temporally Coherent Person Matting Trained on Fake-Motion Dataset
Sep 10, 2021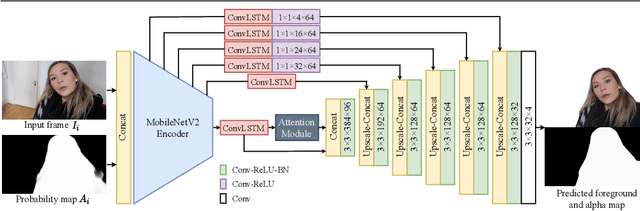
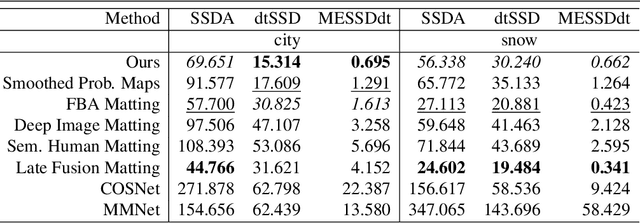
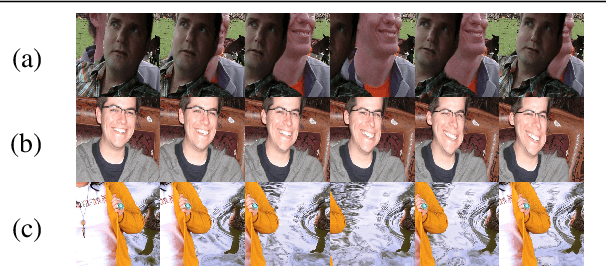
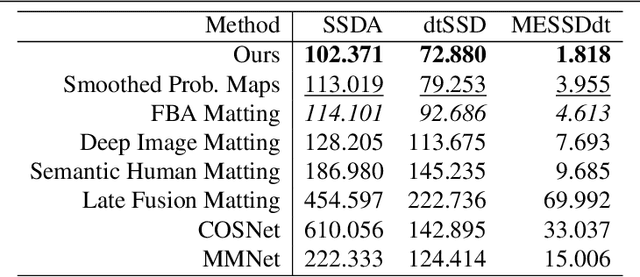
We propose a novel neural-network-based method to perform matting of videos depicting people that does not require additional user input such as trimaps. Our architecture achieves temporal stability of the resulting alpha mattes by using motion-estimation-based smoothing of image-segmentation algorithm outputs, combined with convolutional-LSTM modules on U-Net skip connections. We also propose a fake-motion algorithm that generates training clips for the video-matting network given photos with ground-truth alpha mattes and background videos. We apply random motion to photos and their mattes to simulate movement one would find in real videos and composite the result with the background clips. It lets us train a deep neural network operating on videos in an absence of a large annotated video dataset and provides ground-truth training-clip foreground optical flow for use in loss functions.
Deep Two-Stage High-Resolution Image Inpainting
Apr 27, 2021
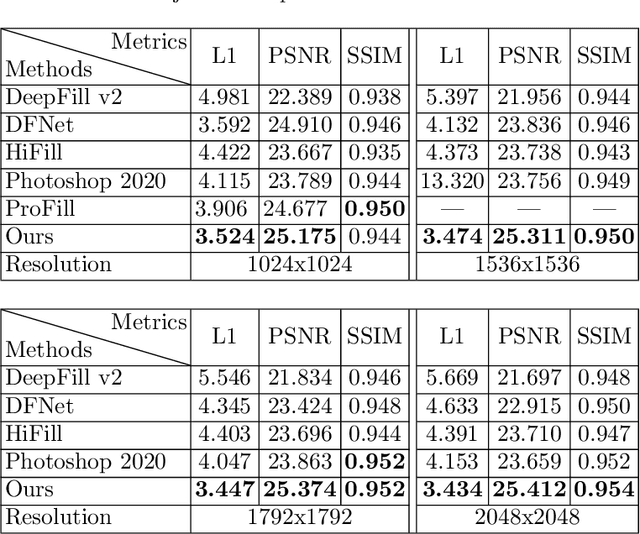
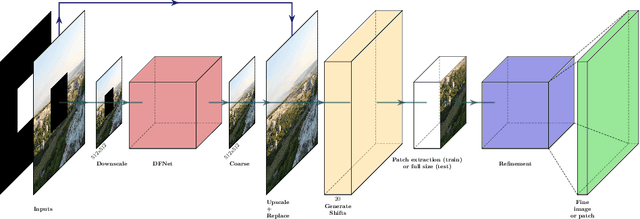
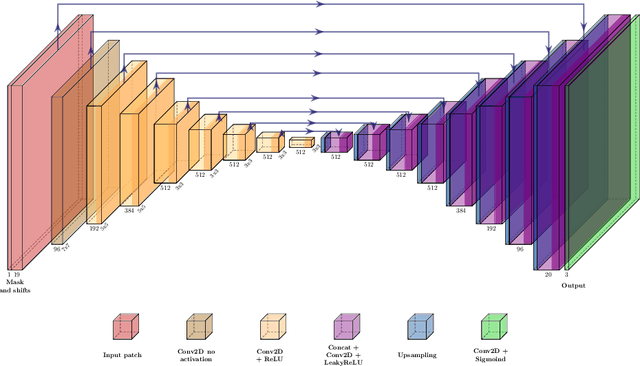
In recent years, the field of image inpainting has developed rapidly, learning based approaches show impressive results in the task of filling missing parts in an image. But most deep methods are strongly tied to the resolution of the images on which they were trained. A slight resolution increase leads to serious artifacts and unsatisfactory filling quality. These methods are therefore unsuitable for interactive image processing. In this article, we propose a method that solves the problem of inpainting arbitrary-size images. We also describe a way to better restore texture fragments in the filled area. For this, we propose to use information from neighboring pixels by shifting the original image in four directions. Moreover, this approach can work with existing inpainting models, making them almost resolution independent without the need for retraining. We also created a GIMP plugin that implements our technique. The plugin, code, and model weights are available at https://github.com/a-mos/High_Resolution_Image_Inpainting.