 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Deep Learning with Bayesian Privacy
Sep 27, 2021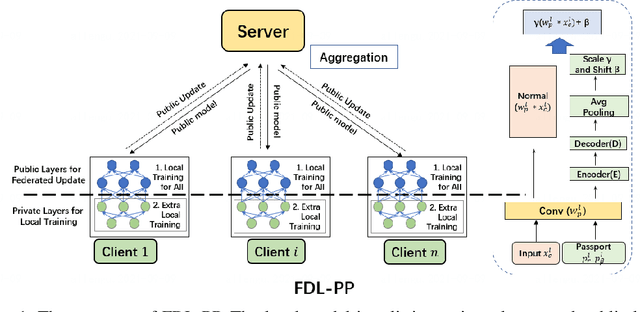
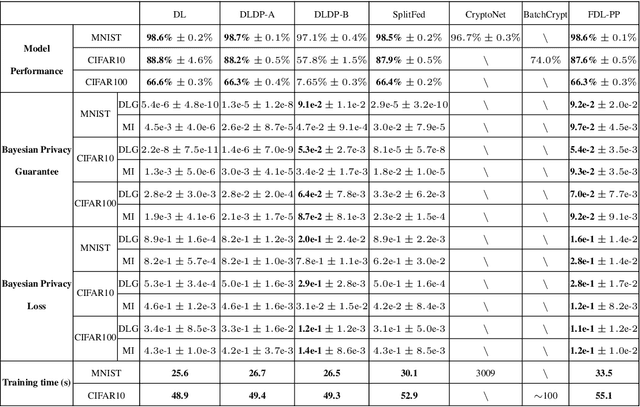
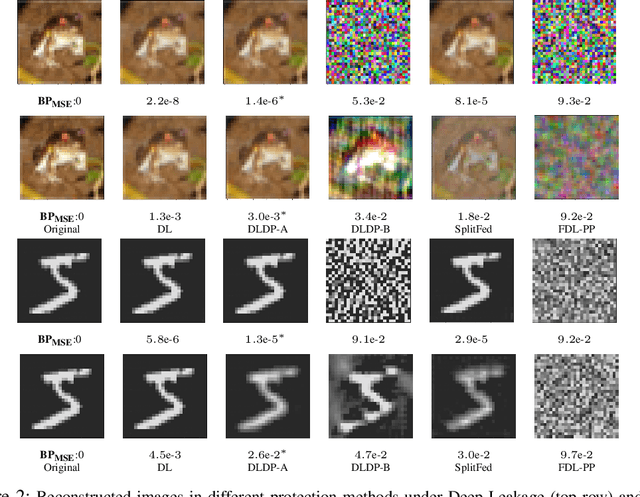
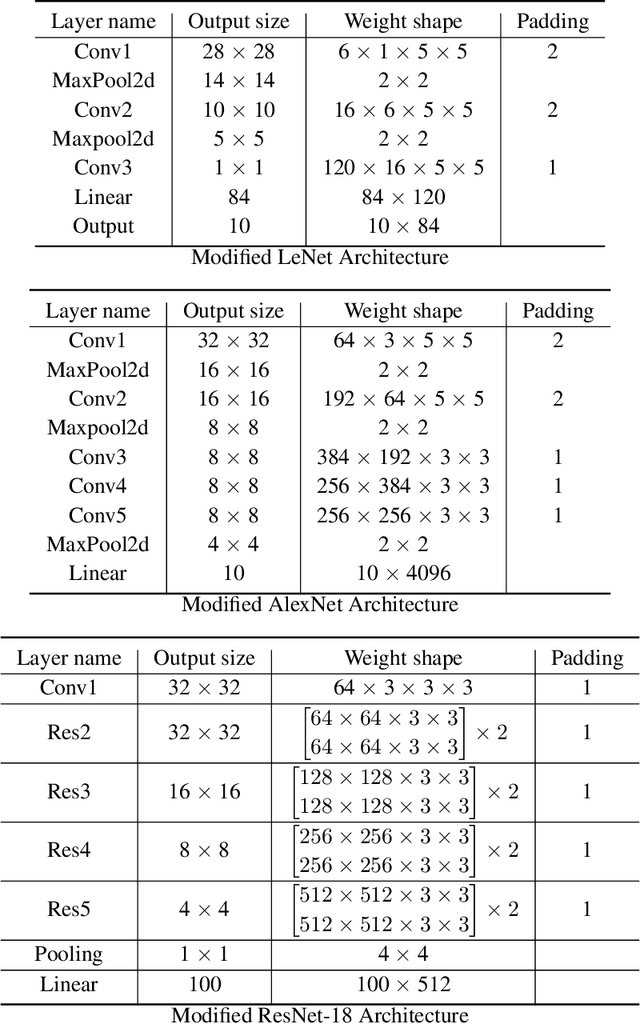
Federated learning (FL) aims to protect data privacy by cooperatively learning a model without sharing private data among users. For Federated Learning of Deep Neural Network with billions of model parameters, existing privacy-preserving solutions are unsatisfactory. Homomorphic encryption (HE) based methods provide secure privacy protections but suffer from extremely high computational and communication overheads rendering it almost useless in practice . Deep learning with Differential Privacy (DP) was implemented as a practical learning algorithm at a manageable cost in complexity. However, DP is vulnerable to aggressive Bayesian restoration attacks as disclosed in the literature and demonstrated in experimental results of this work. To address the aforementioned perplexity, we propose a novel Bayesian Privacy (BP) framework which enables Bayesian restoration attacks to be formulated as the probability of reconstructing private data from observed public information. Specifically, the proposed BP framework accurately quantifies privacy loss by Kullback-Leibler (KL) Divergence between the prior distribution about the privacy data and the posterior distribution of restoration private data conditioning on exposed information}. To our best knowledge, this Bayesian Privacy analysis is the first to provides theoretical justification of secure privacy-preserving capabilities against Bayesian restoration attacks. As a concrete use case, we demonstrate that a novel federated deep learning method using private passport layers is able to simultaneously achieve high model performance, privacy-preserving capability and low computational complexity. Theoretical analysis is in accordance with empirical measurements of information leakage extensively experimented with a variety of DNN networks on image classification MNIST, CIFAR10, and CIFAR100 datasets.
Multi-Task Learning in Natural Language Processing: An Overview
Sep 19, 2021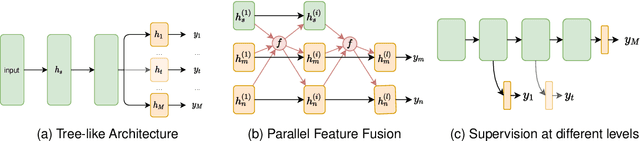
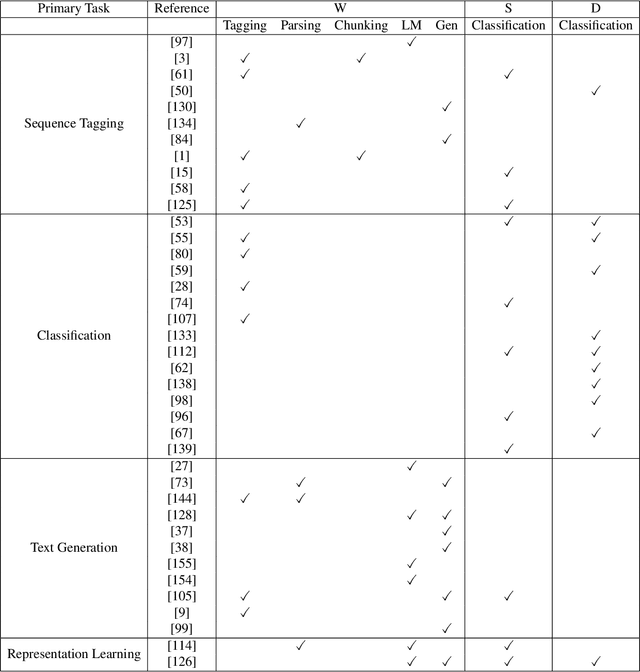
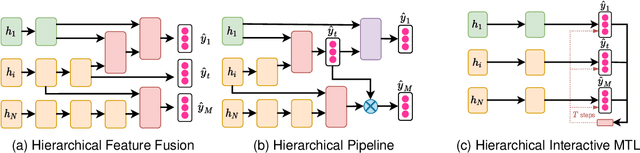
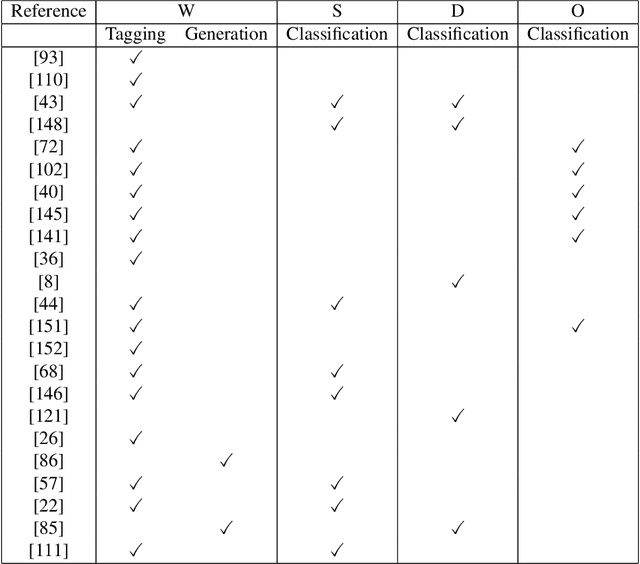
Deep learning approaches have achieved great success in the field of Natural Language Processing (NLP). However, deep neural models often suffer from overfitting and data scarcity problems that are pervasive in NLP tasks. In recent years, Multi-Task Learning (MTL), which can leverage useful information of related tasks to achieve simultaneous performance improvement on multiple related tasks, has been used to handle these problems. In this paper, we give an overview of the use of MTL in NLP tasks. We first review MTL architectures used in NLP tasks and categorize them into four classes, including the parallel architecture, hierarchical architecture, modular architecture, and generative adversarial architecture. Then we present optimization techniques on loss construction, data sampling, and task scheduling to properly train a multi-task model. After presenting applications of MTL in a variety of NLP tasks, we introduce some benchmark datasets. Finally, we make a conclusion and discuss several possible research directions in this field.
QUEACO: Borrowing Treasures from Weakly-labeled Behavior Data for Query Attribute Value Extraction
Sep 05, 2021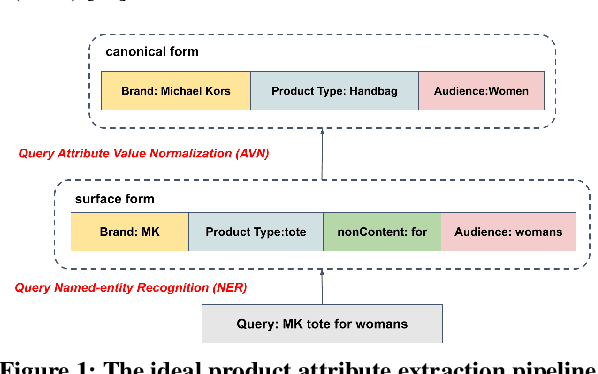

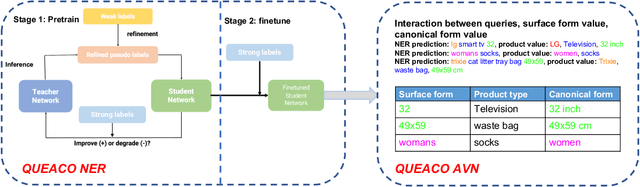
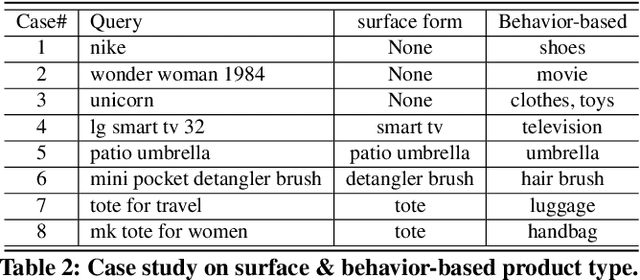
We study the problem of query attribute value extraction, which aims to identify named entities from user queries as diverse surface form attribute values and afterward transform them into formally canonical forms. Such a problem consists of two phases: {named entity recognition (NER)} and {attribute value normalization (AVN)}. However, existing works only focus on the NER phase but neglect equally important AVN. To bridge this gap, this paper proposes a unified query attribute value extraction system in e-commerce search named QUEACO, which involves both two phases. Moreover, by leveraging large-scale weakly-labeled behavior data, we further improve the extraction performance with less supervision cost. Specifically, for the NER phase, QUEACO adopts a novel teacher-student network, where a teacher network that is trained on the strongly-labeled data generates pseudo-labels to refine the weakly-labeled data for training a student network. Meanwhile, the teacher network can be dynamically adapted by the feedback of the student's performance on strongly-labeled data to maximally denoise the noisy supervisions from the weak labels. For the AVN phase, we also leverage the weakly-labeled query-to-attribute behavior data to normalize surface form attribute values from queries into canonical forms from products. Extensive experiments on a real-world large-scale E-commerce dataset demonstrate the effectiveness of QUEACO.
* The 30th ACM International Conference on Information and Knowledge Management (CIKM 2021, Applied Research Track)
Practical and Secure Federated Recommendation with Personalized Masks
Aug 18, 2021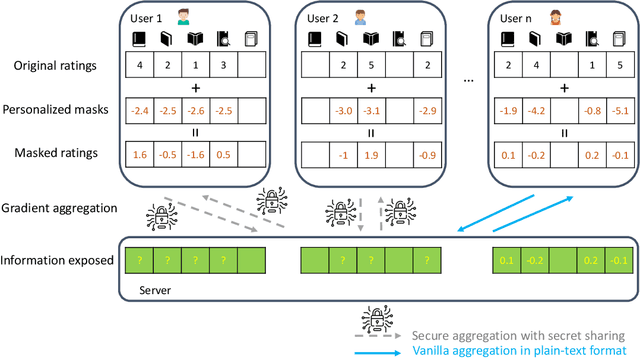
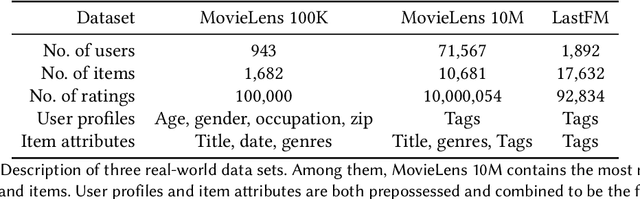


Federated recommendation is a new notion of private distributed recommender systems. It aims to address the data silo and privacy problems altogether. Current federated recommender systems mainly utilize homomorphic encryption and differential privacy methods to protect the intermediate computational results. However, the former comes with extra communication and computation costs, the latter damages model accuracy. Neither of them could simultaneously satisfy the real-time feedback and accurate personalization requirements of recommender systems. In this paper, we proposed a new federated recommendation framework, named federated masked matrix factorization. Federated masked matrix factorization could protect the data privacy in federated recommender systems without sacrificing efficiency or efficacy. Instead of using homomorphic encryption and differential privacy, we utilize the secret sharing technique to incorporate the secure aggregation process of federated matrix factorization. Compared with homomorphic encryption, secret sharing largely speeds up the whole training process. In addition, we introduce a new idea of personalized masks and apply it in the proposed federated masked matrix factorization framework. On the one hand, personalized masks could further improve efficiency. On the other hand, personalized masks also benefit efficacy. Empirically, we show the superiority of the designed model on different real-world data sets. Besides, we also provide the privacy guarantee and discuss the extension of the personalized mask method to the general federated learning tasks.
Transferring Knowledge Distillation for Multilingual Social Event Detection
Aug 10, 2021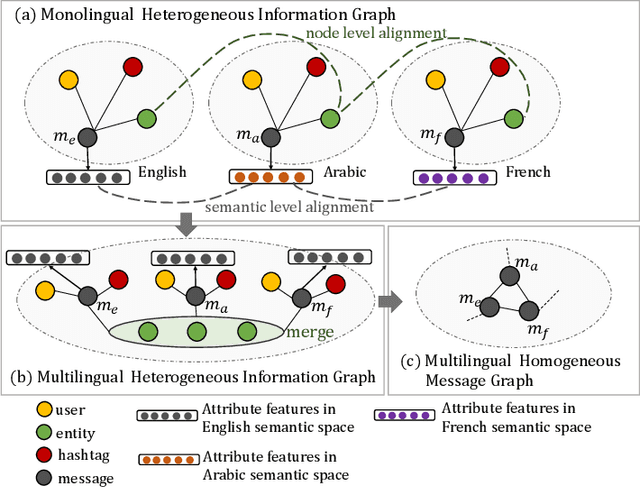
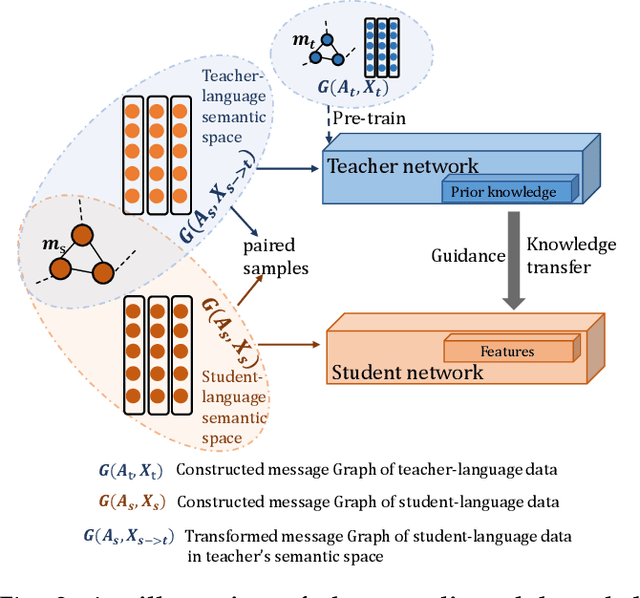
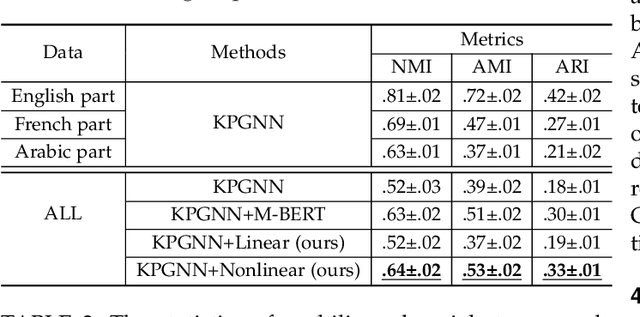
Recently published graph neural networks (GNNs) show promising performance at social event detection tasks. However, most studies are oriented toward monolingual data in languages with abundant training samples. This has left the more common multilingual settings and lesser-spoken languages relatively unexplored. Thus, we present a GNN that incorporates cross-lingual word embeddings for detecting events in multilingual data streams. The first exploit is to make the GNN work with multilingual data. For this, we outline a construction strategy that aligns messages in different languages at both the node and semantic levels. Relationships between messages are established by merging entities that are the same but are referred to in different languages. Non-English message representations are converted into English semantic space via the cross-lingual word embeddings. The resulting message graph is then uniformly encoded by a GNN model. In special cases where a lesser-spoken language needs to be detected, a novel cross-lingual knowledge distillation framework, called CLKD, exploits prior knowledge learned from similar threads in English to make up for the paucity of annotated data. Experiments on both synthetic and real-world datasets show the framework to be highly effective at detection in both multilingual data and in languages where training samples are scarce.
CityNet: A Multi-city Multi-modal Dataset for Smart City Applications
Jun 30, 2021
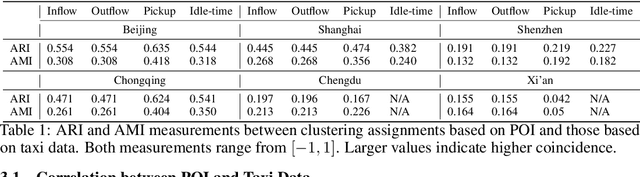
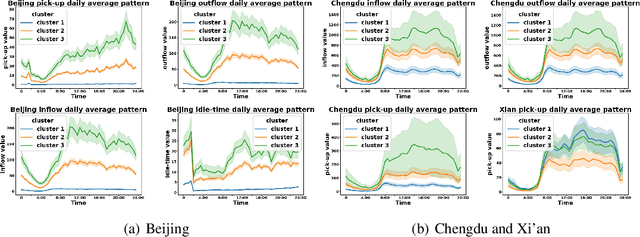
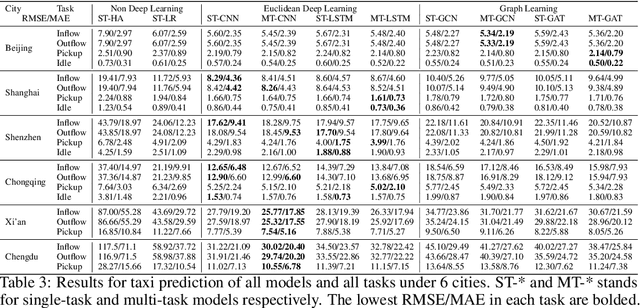
Data-driven approaches have been applied to many problems in urban computing. However, in the research community, such approaches are commonly studied under data from limited sources, and are thus unable to characterize the complexity of urban data coming from multiple entities and the correlations among them. Consequently, an inclusive and multifaceted dataset is necessary to facilitate more extensive studies on urban computing. In this paper, we present CityNet, a multi-modal urban dataset containing data from 7 cities, each of which coming from 3 data sources. We first present the generation process of CityNet as well as its basic properties. In addition, to facilitate the use of CityNet, we carry out extensive machine learning experiments, including spatio-temporal predictions, transfer learning, and reinforcement learning. The experimental results not only provide benchmarks for a wide range of tasks and methods, but also uncover internal correlations among cities and tasks within CityNet that, with adequate leverage, can improve performances on various tasks. With the benchmarking results and the correlations uncovered, we believe that CityNet can contribute to the field of urban computing by supporting research on many advanced topics.
Frustratingly Easy Transferability Estimation
Jun 17, 2021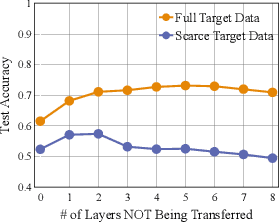
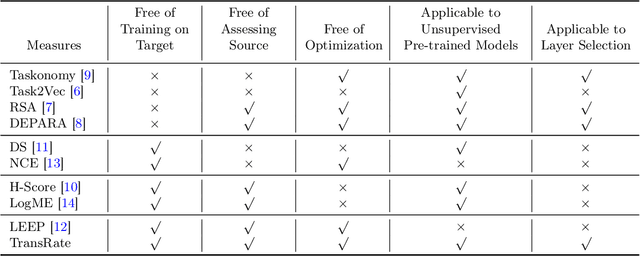
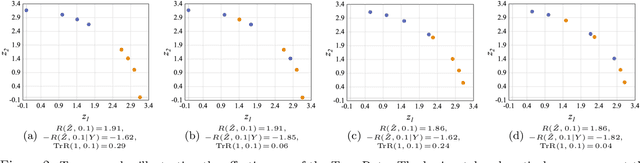
Transferability estimation has been an essential tool in selecting a pre-trained model and the layers of it to transfer, so as to maximize the performance on a target task and prevent negative transfer. Existing estimation algorithms either require intensive training on target tasks or have difficulties in evaluating the transferability between layers. We propose a simple, efficient, and effective transferability measure named TransRate. With single pass through the target data, TransRate measures the transferability as the mutual information between the features of target examples extracted by a pre-trained model and labels of them. We overcome the challenge of efficient mutual information estimation by resorting to coding rate that serves as an effective alternative to entropy. TransRate is theoretically analyzed to be closely related to the performance after transfer learning. Despite its extraordinary simplicity in 10 lines of codes, TransRate performs remarkably well in extensive evaluations on 22 pre-trained models and 16 downstream tasks.
Ternary Hashing
Mar 19, 2021
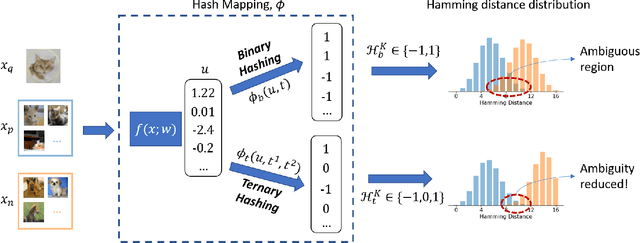
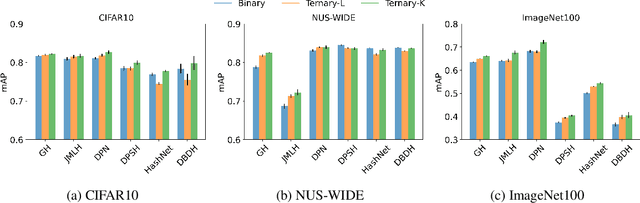
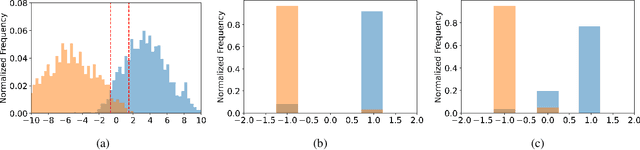
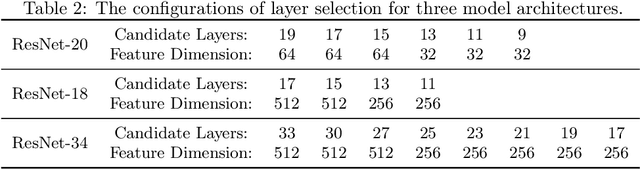
This paper proposes a novel ternary hash encoding for learning to hash methods, which provides a principled more efficient coding scheme with performances better than those of the state-of-the-art binary hashing counterparts. Two kinds of axiomatic ternary logic, Kleene logic and {\L}ukasiewicz logic are adopted to calculate the Ternary Hamming Distance (THD) for both the learning/encoding and testing/querying phases. Our work demonstrates that, with an efficient implementation of ternary logic on standard binary machines, the proposed ternary hashing is compared favorably to the binary hashing methods with consistent improvements of retrieval mean average precision (mAP) ranging from 1\% to 5.9\% as shown in CIFAR10, NUS-WIDE and ImageNet100 datasets.
Protecting Intellectual Property of Generative Adversarial Networks from Ambiguity Attack
Mar 01, 2021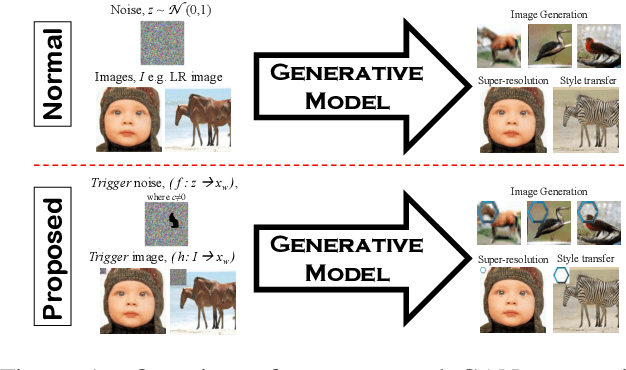



Ever since Machine Learning as a Service (MLaaS) emerges as a viable business that utilizes deep learning models to generate lucrative revenue, Intellectual Property Right (IPR) has become a major concern because these deep learning models can easily be replicated, shared, and re-distributed by any unauthorized third parties. To the best of our knowledge, one of the prominent deep learning models - Generative Adversarial Networks (GANs) which has been widely used to create photorealistic image are totally unprotected despite the existence of pioneering IPR protection methodology for Convolutional Neural Networks (CNNs). This paper therefore presents a complete protection framework in both black-box and white-box settings to enforce IPR protection on GANs. Empirically, we show that the proposed method does not compromise the original GANs performance (i.e. image generation, image super-resolution, style transfer), and at the same time, it is able to withstand both removal and ambiguity attacks against embedded watermarks.
Towards Personalized Federated Learning
Mar 01, 2021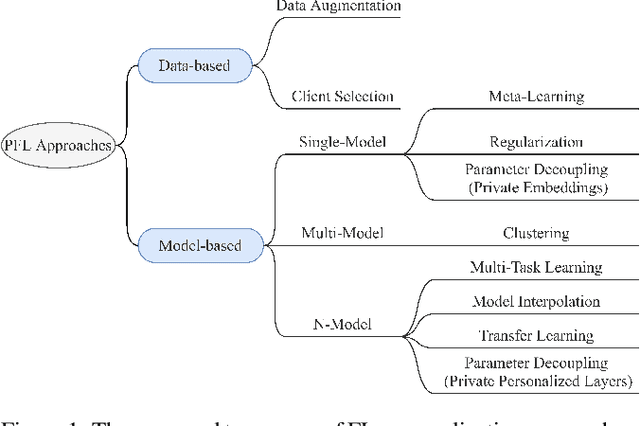
As artificial intelligence (AI)-empowered applications become widespread, there is growing awareness and concern for user privacy and data confidentiality. This has contributed to the popularity of federated learning (FL). FL applications often face data distribution and device capability heterogeneity across data owners. This has stimulated the rapid development of Personalized FL (PFL). In this paper, we complement existing surveys, which largely focus on the methods and applications of FL, with a review of recent advances in PFL. We discuss hurdles to PFL under the current FL settings, and present a unique taxonomy dividing PFL techniques into data-based and model-based approaches. We highlight their key ideas, and envision promising future trajectories of research towards new PFL architectural design, realistic PFL benchmarking, and trustworthy PFL approaches.