 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErased, but Not Gone: Output Forgetting Is Not True Forgetting
Jun 23, 2026Machine unlearning (MU) is commonly judged by output forgetting, such as low forget-set accuracy or reduced logit-level membership inference. But if output-level success can coexist with retraining-inconsistent residuals in representation space, what kind of forgetting are current evaluations actually certifying? We study this question through retraining-consistent representation forgetting, using the retrained model (i.e., trained from scratch without the forget data) as an operational reference for correct forgetting. Across multiple unlearning methods, datasets, and models, our theoretical analysis and empirical results show that standard output-level evaluation can systematically overestimate the success of unlearning. Under this stronger lens, current methods often appear forgotten at the output layer while exhibiting a structured mismatch relative to retraining. They partially align with retraining on forget samples, remain more inconsistent on retain samples, and leave residual discrepancy concentrated along retraining-related directions rather than diffuse in representation space. This structured mismatch is characterized by forget/retain asymmetry, directional mismatch, and concentrated residuals along retraining-related directions. These results suggest that current MU is often evaluated for apparent forgetting rather than retraining-consistent forgetting. More broadly, retraining reveals what output forgetting hides.
Hidden Consensus:Preference-Validity Compression in Human Feedback
Jun 09, 2026Standard RLHF pipelines often reduce heterogeneous human judgments into a single scalar reward target. We argue that this reduction can mis-measure alignment in structurally plural societies, where disagreement may reflect culturally, historically, linguistically, regionally, or normatively grounded interpretations rather than annotation noise. We call this failure Preference-Validity Compression, the collapse of multiple plural-valid response options into a single optimization target. Using Malaysia as a diagnostic setting, we analyze RLHF-style feedback aggregation through preference events linking prompts, responses, and acceptability judgments across interpretive frames. Across 321 preference events from 20 participants and 107 trio-annotated prompts, 79% of prompts contain more than one majority-supported response that single-winner aggregation would discard, and apparent dominance gaps between top responses diminish when all majority-supported options are considered. Participants frequently select multiple acceptable responses, and discarded responses demonstrably reflect coherent local, practical, or cultural frames. These findings show that majority aggregation in this corpus measures argmax acceptability rather than plural alignment. We treat this as a measurement-validity issue and argue that future alignment methods should satisfy Validity-Preserving Consistency, remaining stable across plural-valid interpretive frames rather than collapsing them into a single reward target.
They Are Not the Same: Direct Causes Are Not Grounded Emotion Explanations
May 24, 2026Emotion-Cause Pair Extraction (ECPE) was introduced to explain why an emotion occurs, but this goal is now often reduced to binary pair/non-pair prediction. This proxy is useful for direct-cause extraction, yet easy to over-read as evidence grounded emotion explanation. We show that this interpretation is only partially valid. In IEMO-MECP, 90.9% of original positives remain emo-cause and 95.0% of original negatives remain non-pair, confirming that the binary ECPE task is largely preserved. The problem is that direct triggers alone do not constitute a grounded explanation. Emo-context, an utterance that helps interpret a target emotion without directly causing it, appears on both sides of the original boundary and is enriched near binary uncertainty, showing that the binary boundary has no stable place for such discourse evidence. Across evaluated ECPE models, direct triggers are recovered more reliably than contextual support. Under shortcut pressure, this imbalance becomes consequential. Binary-trained models assign higher pair scores to nearby lexically similar non-pair candidates than to evidence supported but structurally harder emo-cause and emo-context pairs. Thus, pair scores can reward convenient attributions over grounded explanations. High binary ECPE performance indicates that a model can identify direct triggers; it does not indicate that the model has explained the emotion. Code is publicly available at https://github.com/panzhzh/ECPExsame.
Single-Pass, Depth-Selective Reading for Multi-Aspect Sentiment Analysis
May 20, 2026Aspect-Term Sentiment Analysis (ATSA) in multi-aspect sentences faces a fundamental tradeoff between efficiency and expressiveness. Existing models either re-encode the sentence for each aspect or rely on static use of deep representations, leading to redundant computation and limited adaptivity. We argue that Transformer depth is a costly, queryable resource, and propose DABS, a single-pass inference framework that encodes each sentence once to construct a reusable, depth-ordered substrate. Each aspect then queries this shared representation to selectively read relevant tokens and abstraction levels, without re-encoding. This decouples shared sentence encoding from lightweight, aspect-conditioned readout. Experiments on four ATSA benchmarks show that DABS achieves competitive performance while reducing end-to-end computation by up to 60% in multi-aspect settings (M >= 2). Further analyses indicate that adaptive depth querying is most beneficial for linguistically complex cases such as negation and contrast. Code is publicly available at https://github.com/panzhzh/acl-dabs
OneHOI: Unifying Human-Object Interaction Generation and Editing
Apr 15, 2026Human-Object Interaction (HOI) modelling captures how humans act upon and relate to objects, typically expressed as <person, action, object> triplets. Existing approaches split into two disjoint families: HOI generation synthesises scenes from structured triplets and layout, but fails to integrate mixed conditions like HOI and object-only entities; and HOI editing modifies interactions via text, yet struggles to decouple pose from physical contact and scale to multiple interactions. We introduce OneHOI, a unified diffusion transformer framework that consolidates HOI generation and editing into a single conditional denoising process driven by shared structured interaction representations. At its core, the Relational Diffusion Transformer (R-DiT) models verb-mediated relations through role- and instance-aware HOI tokens, layout-based spatial Action Grounding, a Structured HOI Attention to enforce interaction topology, and HOI RoPE to disentangle multi-HOI scenes. Trained jointly with modality dropout on our HOI-Edit-44K, along with HOI and object-centric datasets, OneHOI supports layout-guided, layout-free, arbitrary-mask, and mixed-condition control, achieving state-of-the-art results across both HOI generation and editing. Code is available at https://jiuntian.github.io/OneHOI/.
VAGNet: Grounding 3D Affordance from Human-Object Interactions in Videos
Feb 24, 20263D object affordance grounding aims to identify regions on 3D objects that support human-object interaction (HOI), a capability essential to embodied visual reasoning. However, most existing approaches rely on static visual or textual cues, neglecting that affordances are inherently defined by dynamic actions. As a result, they often struggle to localize the true contact regions involved in real interactions. We take a different perspective. Humans learn how to use objects by observing and imitating actions, not just by examining shapes. Motivated by this intuition, we introduce video-guided 3D affordance grounding, which leverages dynamic interaction sequences to provide functional supervision. To achieve this, we propose VAGNet, a framework that aligns video-derived interaction cues with 3D structure to resolve ambiguities that static cues cannot address. To support this new setting, we introduce PVAD, the first HOI video-3D pairing affordance dataset, providing functional supervision unavailable in prior works. Extensive experiments on PVAD show that VAGNet achieves state-of-the-art performance, significantly outperforming static-based baselines. The code and dataset will be open publicly.
Stratify: Rethinking Federated Learning for Non-IID Data through Balanced Sampling
Apr 18, 2025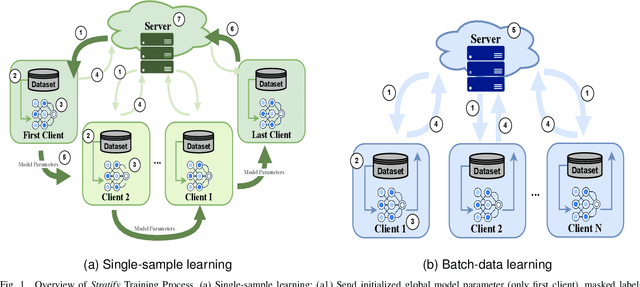
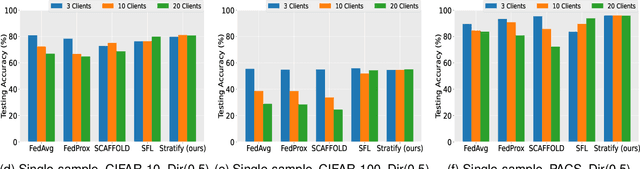
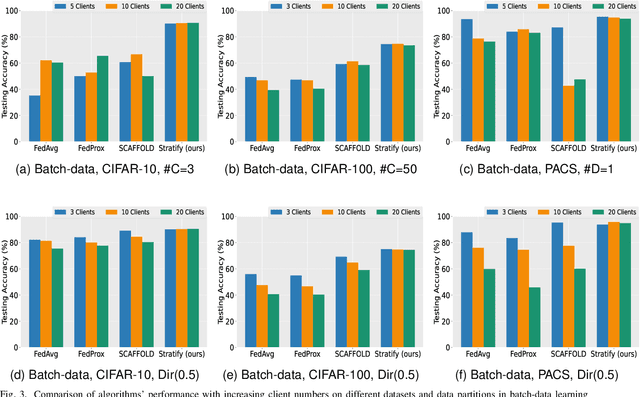
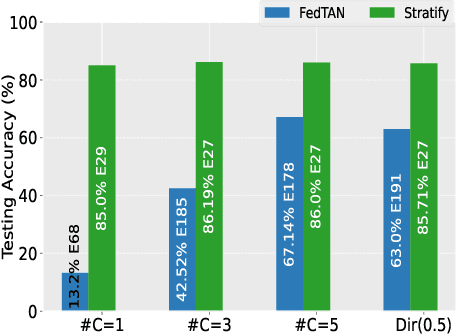
Federated Learning (FL) on non-independently and identically distributed (non-IID) data remains a critical challenge, as existing approaches struggle with severe data heterogeneity. Current methods primarily address symptoms of non-IID by applying incremental adjustments to Federated Averaging (FedAvg), rather than directly resolving its inherent design limitations. Consequently, performance significantly deteriorates under highly heterogeneous conditions, as the fundamental issue of imbalanced exposure to diverse class and feature distributions remains unresolved. This paper introduces Stratify, a novel FL framework designed to systematically manage class and feature distributions throughout training, effectively tackling the root cause of non-IID challenges. Inspired by classical stratified sampling, our approach employs a Stratified Label Schedule (SLS) to ensure balanced exposure across labels, significantly reducing bias and variance in aggregated gradients. Complementing SLS, we propose a label-aware client selection strategy, restricting participation exclusively to clients possessing data relevant to scheduled labels. Additionally, Stratify incorporates a fine-grained, high-frequency update scheme, accelerating convergence and further mitigating data heterogeneity. To uphold privacy, we implement a secure client selection protocol leveraging homomorphic encryption, enabling precise global label statistics without disclosing sensitive client information. Extensive evaluations on MNIST, CIFAR-10, CIFAR-100, Tiny-ImageNet, COVTYPE, PACS, and Digits-DG demonstrate that Stratify attains performance comparable to IID baselines, accelerates convergence, and reduces client-side computation compared to state-of-the-art methods, underscoring its practical effectiveness in realistic federated learning scenarios.
InteractEdit: Zero-Shot Editing of Human-Object Interactions in Images
Mar 12, 2025



This paper presents InteractEdit, a novel framework for zero-shot Human-Object Interaction (HOI) editing, addressing the challenging task of transforming an existing interaction in an image into a new, desired interaction while preserving the identities of the subject and object. Unlike simpler image editing scenarios such as attribute manipulation, object replacement or style transfer, HOI editing involves complex spatial, contextual, and relational dependencies inherent in humans-objects interactions. Existing methods often overfit to the source image structure, limiting their ability to adapt to the substantial structural modifications demanded by new interactions. To address this, InteractEdit decomposes each scene into subject, object, and background components, then employs Low-Rank Adaptation (LoRA) and selective fine-tuning to preserve pretrained interaction priors while learning the visual identity of the source image. This regularization strategy effectively balances interaction edits with identity consistency. We further introduce IEBench, the most comprehensive benchmark for HOI editing, which evaluates both interaction editing and identity preservation. Our extensive experiments show that InteractEdit significantly outperforms existing methods, establishing a strong baseline for future HOI editing research and unlocking new possibilities for creative and practical applications. Code will be released upon publication.
Yuan: Yielding Unblemished Aesthetics Through A Unified Network for Visual Imperfections Removal in Generated Images
Jan 15, 2025



Generative AI presents transformative potential across various domains, from creative arts to scientific visualization. However, the utility of AI-generated imagery is often compromised by visual flaws, including anatomical inaccuracies, improper object placements, and misplaced textual elements. These imperfections pose significant challenges for practical applications. To overcome these limitations, we introduce \textit{Yuan}, a novel framework that autonomously corrects visual imperfections in text-to-image synthesis. \textit{Yuan} uniquely conditions on both the textual prompt and the segmented image, generating precise masks that identify areas in need of refinement without requiring manual intervention -- a common constraint in previous methodologies. Following the automated masking process, an advanced inpainting module seamlessly integrates contextually coherent content into the identified regions, preserving the integrity and fidelity of the original image and associated text prompts. Through extensive experimentation on publicly available datasets such as ImageNet100 and Stanford Dogs, along with a custom-generated dataset, \textit{Yuan} demonstrated superior performance in eliminating visual imperfections. Our approach consistently achieved higher scores in quantitative metrics, including NIQE, BRISQUE, and PI, alongside favorable qualitative evaluations. These results underscore \textit{Yuan}'s potential to significantly enhance the quality and applicability of AI-generated images across diverse fields.
Chirpy3D: Continuous Part Latents for Creative 3D Bird Generation
Jan 07, 2025



In this paper, we push the boundaries of fine-grained 3D generation into truly creative territory. Current methods either lack intricate details or simply mimic existing objects -- we enable both. By lifting 2D fine-grained understanding into 3D through multi-view diffusion and modeling part latents as continuous distributions, we unlock the ability to generate entirely new, yet plausible parts through interpolation and sampling. A self-supervised feature consistency loss further ensures stable generation of these unseen parts. The result is the first system capable of creating novel 3D objects with species-specific details that transcend existing examples. While we demonstrate our approach on birds, the underlying framework extends beyond things that can chirp! Code will be released at https://github.com/kamwoh/chirpy3d.