 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Motion Planner for Urban Driving via Hierarchical Imitation Learning
Mar 24, 2023
Learning-based approaches have achieved impressive performance for autonomous driving and an increasing number of data-driven works are being studied in the decision-making and planning module. However, the reliability and the stability of the neural network is still full of challenges. In this paper, we introduce a hierarchical imitation method including a high-level grid-based behavior planner and a low-level trajectory planner, which is not only an individual data-driven driving policy and can also be easily embedded into the rule-based architecture. We evaluate our method both in closed-loop simulation and real world driving, and demonstrate the neural network planner has outstanding performance in complex urban autonomous driving scenarios.
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
Mar 21, 2023



Autonomous driving requires a comprehensive understanding of the surrounding environment for reliable trajectory planning. Previous works rely on dense rasterized scene representation (e.g., agent occupancy and semantic map) to perform planning, which is computationally intensive and misses the instance-level structure information. In this paper, we propose VAD, an end-to-end vectorized paradigm for autonomous driving, which models the driving scene as fully vectorized representation. The proposed vectorized paradigm has two significant advantages. On one hand, VAD exploits the vectorized agent motion and map elements as explicit instance-level planning constraints which effectively improves planning safety. On the other hand, VAD runs much faster than previous end-to-end planning methods by getting rid of computation-intensive rasterized representation and hand-designed post-processing steps. VAD achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, outperforming the previous best method by a large margin (reducing the average collision rate by 48.4%). Besides, VAD greatly improves the inference speed (up to 9.3x), which is critical for the real-world deployment of an autonomous driving system. Code and models will be released for facilitating future research.
Lane Graph as Path: Continuity-preserving Path-wise Modeling for Online Lane Graph Construction
Mar 15, 2023



Online lane graph construction is a promising but challenging task in autonomous driving. Previous methods usually model the lane graph at the pixel or piece level, and recover the lane graph by pixel-wise or piece-wise connection, which breaks down the continuity of the lane. Human drivers focus on and drive along the continuous and complete paths instead of considering lane pieces. Autonomous vehicles also require path-specific guidance from lane graph for trajectory planning. We argue that the path, which indicates the traffic flow, is the primitive of the lane graph. Motivated by this, we propose to model the lane graph in a novel path-wise manner, which well preserves the continuity of the lane and encodes traffic information for planning. We present a path-based online lane graph construction method, termed LaneGAP, which end-to-end learns the path and recovers the lane graph via a Path2Graph algorithm. We qualitatively and quantitatively demonstrate the superiority of LaneGAP over conventional pixel-based and piece-based methods. Abundant visualizations show LaneGAP can cope with diverse traffic conditions. Code and models will be released at \url{https://github.com/hustvl/LaneGAP} for facilitating future research.
Deep-Learning Tool for Early Identifying Non-Traumatic Intracranial Hemorrhage Etiology based on CT Scan
Feb 02, 2023



Background: To develop an artificial intelligence system that can accurately identify acute non-traumatic intracranial hemorrhage (ICH) etiology based on non-contrast CT (NCCT) scans and investigate whether clinicians can benefit from it in a diagnostic setting. Materials and Methods: The deep learning model was developed with 1868 eligible NCCT scans with non-traumatic ICH collected between January 2011 and April 2018. We tested the model on two independent datasets (TT200 and SD 98) collected after April 2018. The model's diagnostic performance was compared with clinicians's performance. We further designed a simulated study to compare the clinicians's performance with and without the deep learning system augmentation. Results: The proposed deep learning system achieved area under the receiver operating curve of 0.986 (95% CI 0.967-1.000) on aneurysms, 0.952 (0.917-0.987) on hypertensive hemorrhage, 0.950 (0.860-1.000) on arteriovenous malformation (AVM), 0.749 (0.586-0.912) on Moyamoya disease (MMD), 0.837 (0.704-0.969) on cavernous malformation (CM), and 0.839 (0.722-0.959) on other causes in TT200 dataset. Given a 90% specificity level, the sensitivities of our model were 97.1% and 90.9% for aneurysm and AVM diagnosis, respectively. The model also shows an impressive generalizability in an independent dataset SD98. The clinicians achieve significant improvements in the sensitivity, specificity, and accuracy of diagnoses of certain hemorrhage etiologies with proposed system augmentation. Conclusions: The proposed deep learning algorithms can be an effective tool for early identification of hemorrhage etiologies based on NCCT scans. It may also provide more information for clinicians for triage and further imaging examination selection.
Deep Learning Approach to Predict Hemorrhage in Moyamoya Disease
Feb 01, 2023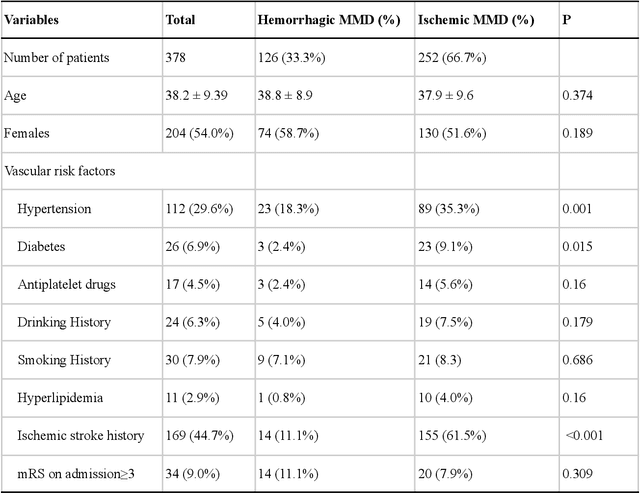


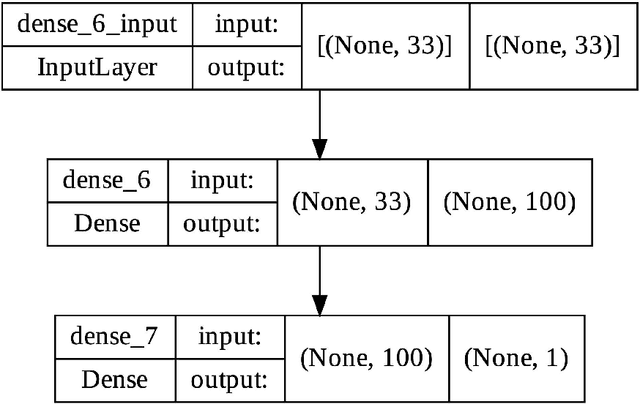
Objective: Reliable tools to predict moyamoya disease (MMD) patients at risk for hemorrhage could have significant value. The aim of this paper is to develop three machine learning classification algorithms to predict hemorrhage in moyamoya disease. Methods: Clinical data of consecutive MMD patients who were admitted to our hospital between 2009 and 2015 were reviewed. Demographics, clinical, radiographic data were analyzed to develop artificial neural network (ANN), support vector machine (SVM), and random forest models. Results: We extracted 33 parameters, including 11 demographic and 22 radiographic features as input for model development. Of all compared classification results, ANN achieved the highest overall accuracy of 75.7% (95% CI, 68.6%-82.8%), followed by SVM with 69.2% (95% CI, 56.9%-81.5%) and random forest with 70.0% (95% CI, 57.0%-83.0%). Conclusions: The proposed ANN framework can be a potential effective tool to predict the possibility of hemorrhage among adult MMD patients based on clinical information and radiographic features.
FireFly: A High-Throughput and Reconfigurable Hardware Accelerator for Spiking Neural Networks
Jan 23, 2023Spiking neural networks (SNNs) have been widely used due to their strong biological interpretability and high energy efficiency. With the introduction of the backpropagation algorithm and surrogate gradient, the structure of spiking neural networks has become more complex, and the performance gap with artificial neural networks has gradually decreased. However, most SNN hardware implementations for field-programmable gate arrays (FPGAs) cannot meet arithmetic or memory efficiency requirements, which significantly restricts the development of SNNs. They do not delve into the arithmetic operations between the binary spikes and synaptic weights or assume unlimited on-chip RAM resources by using overly expensive devices on small tasks. To improve arithmetic efficiency, we analyze the neural dynamics of spiking neurons, generalize the SNN arithmetic operation to the multiplex-accumulate operation, and propose a high-performance implementation of such operation by utilizing the DSP48E2 hard block in Xilinx Ultrascale FPGAs. To improve memory efficiency, we design a memory system to enable efficient synaptic weights and membrane voltage memory access with reasonable on-chip RAM consumption. Combining the above two improvements, we propose an FPGA accelerator that can process spikes generated by the firing neuron on-the-fly (FireFly). FireFly is implemented on several FPGA edge devices with limited resources but still guarantees a peak performance of 5.53TSOP/s at 300MHz. As a lightweight accelerator, FireFly achieves the highest computational density efficiency compared with existing research using large FPGA devices.
Towards Accurate Ground Plane Normal Estimation from Ego-Motion
Dec 08, 2022



In this paper, we introduce a novel approach for ground plane normal estimation of wheeled vehicles. In practice, the ground plane is dynamically changed due to braking and unstable road surface. As a result, the vehicle pose, especially the pitch angle, is oscillating from subtle to obvious. Thus, estimating ground plane normal is meaningful since it can be encoded to improve the robustness of various autonomous driving tasks (e.g., 3D object detection, road surface reconstruction, and trajectory planning). Our proposed method only uses odometry as input and estimates accurate ground plane normal vectors in real time. Particularly, it fully utilizes the underlying connection between the ego pose odometry (ego-motion) and its nearby ground plane. Built on that, an Invariant Extended Kalman Filter (IEKF) is designed to estimate the normal vector in the sensor's coordinate. Thus, our proposed method is simple yet efficient and supports both camera- and inertial-based odometry algorithms. Its usability and the marked improvement of robustness are validated through multiple experiments on public datasets. For instance, we achieve state-of-the-art accuracy on KITTI dataset with the estimated vector error of 0.39{\deg}. Our code is available at github.com/manymuch/ground_normal_filter.
Perceive, Interact, Predict: Learning Dynamic and Static Clues for End-to-End Motion Prediction
Dec 05, 2022



Motion prediction is highly relevant to the perception of dynamic objects and static map elements in the scenarios of autonomous driving. In this work, we propose PIP, the first end-to-end Transformer-based framework which jointly and interactively performs online mapping, object detection and motion prediction. PIP leverages map queries, agent queries and mode queries to encode the instance-wise information of map elements, agents and motion intentions, respectively. Based on the unified query representation, a differentiable multi-task interaction scheme is proposed to exploit the correlation between perception and prediction. Even without human-annotated HD map or agent's historical tracking trajectory as guidance information, PIP realizes end-to-end multi-agent motion prediction and achieves better performance than tracking-based and HD-map-based methods. PIP provides comprehensive high-level information of the driving scene (vectorized static map and dynamic objects with motion information), and contributes to the downstream planning and control. Code and models will be released for facilitating further research.
Non-reversible Parallel Tempering for Deep Posterior Approximation
Nov 20, 2022



Parallel tempering (PT), also known as replica exchange, is the go-to workhorse for simulations of multi-modal distributions. The key to the success of PT is to adopt efficient swap schemes. The popular deterministic even-odd (DEO) scheme exploits the non-reversibility property and has successfully reduced the communication cost from $O(P^2)$ to $O(P)$ given sufficiently many $P$ chains. However, such an innovation largely disappears in big data due to the limited chains and few bias-corrected swaps. To handle this issue, we generalize the DEO scheme to promote non-reversibility and propose a few solutions to tackle the underlying bias caused by the geometric stopping time. Notably, in big data scenarios, we obtain an appealing communication cost $O(P\log P)$ based on the optimal window size. In addition, we also adopt stochastic gradient descent (SGD) with large and constant learning rates as exploration kernels. Such a user-friendly nature enables us to conduct approximation tasks for complex posteriors without much tuning costs.
SMS: Spiking Marching Scheme for Efficient Long Time Integration of Differential Equations
Nov 17, 2022



We propose a Spiking Neural Network (SNN)-based explicit numerical scheme for long time integration of time-dependent Ordinary and Partial Differential Equations (ODEs, PDEs). The core element of the method is a SNN, trained to use spike-encoded information about the solution at previous timesteps to predict spike-encoded information at the next timestep. After the network has been trained, it operates as an explicit numerical scheme that can be used to compute the solution at future timesteps, given a spike-encoded initial condition. A decoder is used to transform the evolved spiking-encoded solution back to function values. We present results from numerical experiments of using the proposed method for ODEs and PDEs of varying complexity.