 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Contrastive Learning: Encoding Spatial Information for Compact Visual Representations
Nov 19, 2020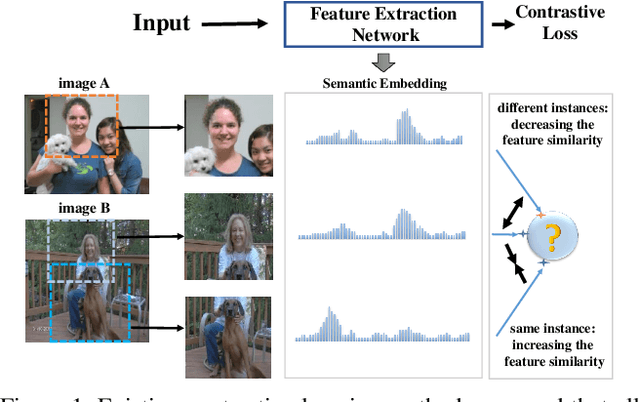
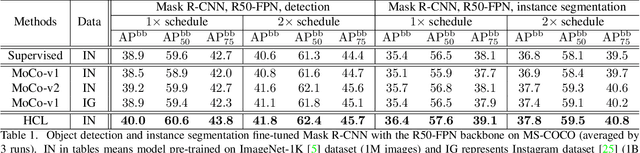
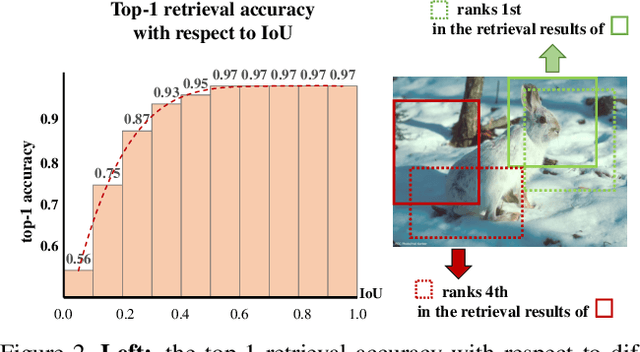
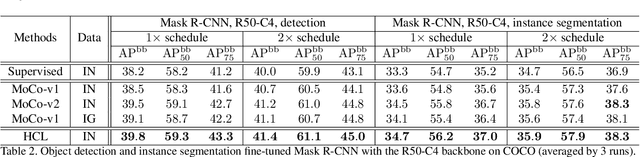
Contrastive learning has achieved great success in self-supervised visual representation learning, but existing approaches mostly ignored spatial information which is often crucial for visual representation. This paper presents heterogeneous contrastive learning (HCL), an effective approach that adds spatial information to the encoding stage to alleviate the learning inconsistency between the contrastive objective and strong data augmentation operations. We demonstrate the effectiveness of HCL by showing that (i) it achieves higher accuracy in instance discrimination and (ii) it surpasses existing pre-training methods in a series of downstream tasks while shrinking the pre-training costs by half. More importantly, we show that our approach achieves higher efficiency in visual representations, and thus delivers a key message to inspire the future research of self-supervised visual representation learning.
Can Semantic Labels Assist Self-Supervised Visual Representation Learning?
Nov 17, 2020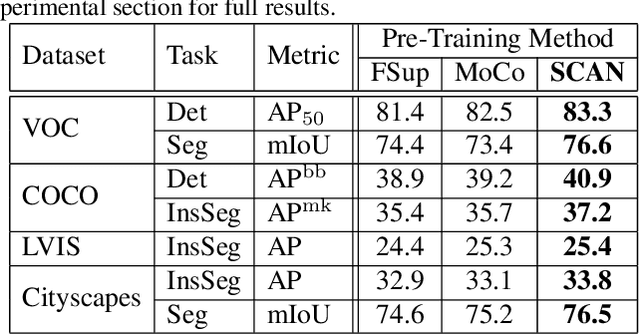

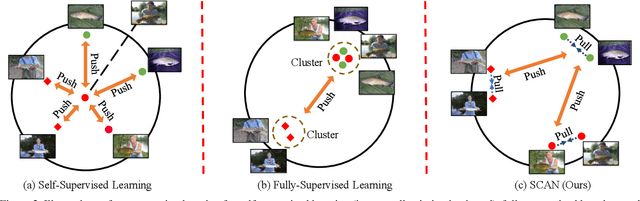
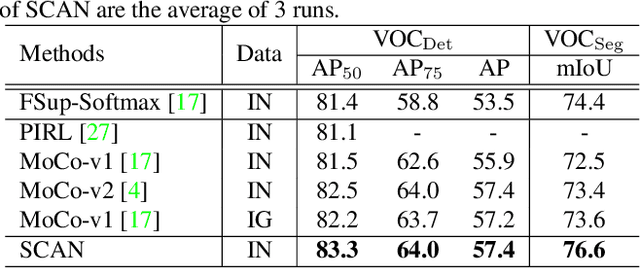
Recently, contrastive learning has largely advanced the progress of unsupervised visual representation learning. Pre-trained on ImageNet, some self-supervised algorithms reported higher transfer learning performance compared to fully-supervised methods, seeming to deliver the message that human labels hardly contribute to learning transferrable visual features. In this paper, we defend the usefulness of semantic labels but point out that fully-supervised and self-supervised methods are pursuing different kinds of features. To alleviate this issue, we present a new algorithm named Supervised Contrastive Adjustment in Neighborhood (SCAN) that maximally prevents the semantic guidance from damaging the appearance feature embedding. In a series of downstream tasks, SCAN achieves superior performance compared to previous fully-supervised and self-supervised methods, and sometimes the gain is significant. More importantly, our study reveals that semantic labels are useful in assisting self-supervised methods, opening a new direction for the community.
Self-Adaptively Learning to Demoire from Focused and Defocused Image Pairs
Nov 05, 2020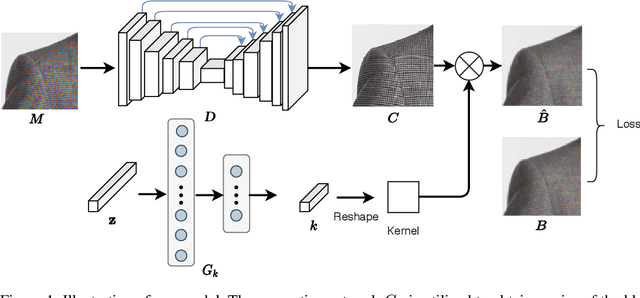



Moire artifacts are common in digital photography, resulting from the interference between high-frequency scene content and the color filter array of the camera. Existing deep learning-based demoireing methods trained on large scale datasets are limited in handling various complex moire patterns, and mainly focus on demoireing of photos taken of digital displays. Moreover, obtaining moire-free ground-truth in natural scenes is difficult but needed for training. In this paper, we propose a self-adaptive learning method for demoireing a high-frequency image, with the help of an additional defocused moire-free blur image. Given an image degraded with moire artifacts and a moire-free blur image, our network predicts a moire-free clean image and a blur kernel with a self-adaptive strategy that does not require an explicit training stage, instead performing test-time adaptation. Our model has two sub-networks and works iteratively. During each iteration, one sub-network takes the moire image as input, removing moire patterns and restoring image details, and the other sub-network estimates the blur kernel from the blur image. The two sub-networks are jointly optimized. Extensive experiments demonstrate that our method outperforms state-of-the-art methods and can produce high-quality demoired results. It can generalize well to the task of removing moire artifacts caused by display screens. In addition, we build a new moire dataset, including images with screen and texture moire artifacts. As far as we know, this is the first dataset with real texture moire patterns.
Center-wise Local Image Mixture For Contrastive Representation Learning
Nov 05, 2020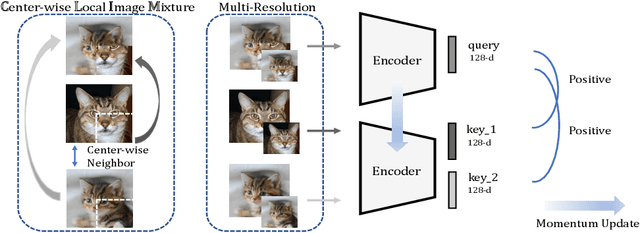
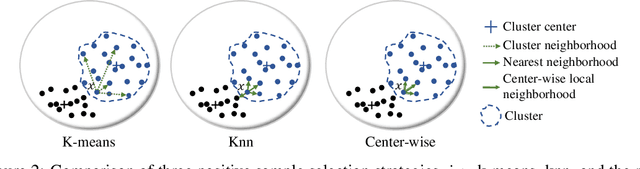
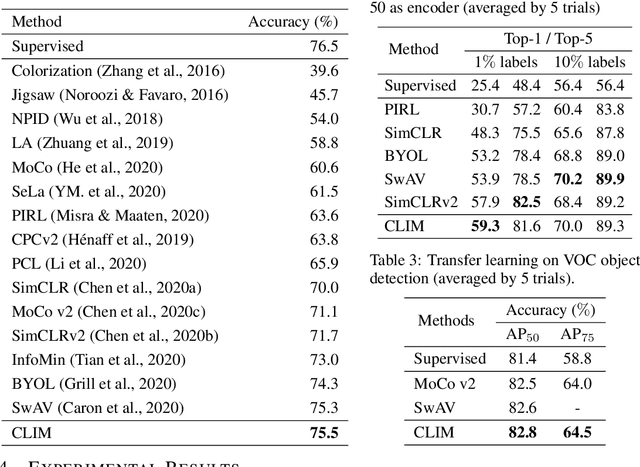
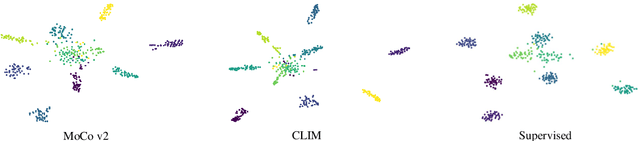
Recent advances in unsupervised representation learning have experienced remarkable progress, especially with the achievements of contrastive learning, which regards each image as well its augmentations as a separate class, while does not consider the semantic similarity among images. This paper proposes a new kind of data augmentation, named Center-wise Local Image Mixture, to expand the neighborhood space of an image. CLIM encourages both local similarity and global aggregation while pulling similar images. This is achieved by searching local similar samples of an image, and only selecting images that are closer to the corresponding cluster center, which we denote as center-wise local selection. As a result, similar representations are progressively approaching the clusters, while do not break the local similarity. Furthermore, image mixture is used as a smoothing regularization to avoid overconfidence on the selected samples. Besides, we introduce multi-resolution augmentation, which enables the representation to be scale invariant. Integrating the two augmentations produces better feature representation on several unsupervised benchmarks. Notably, we reach 75.5% top-1 accuracy with linear evaluation over ResNet-50, and 59.3% top-1 accuracy when fine-tuned with only 1% labels, as well as consistently outperforming supervised pretraining on several downstream transfer tasks.
CooGAN: A Memory-Efficient Framework for High-Resolution Facial Attribute Editing
Nov 03, 2020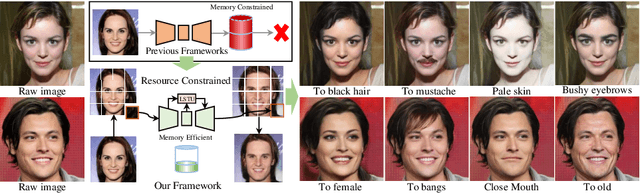

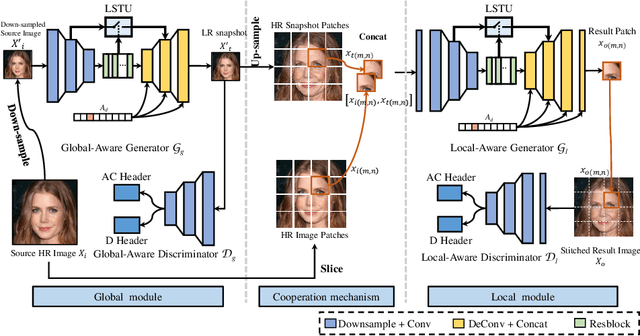

In contrast to great success of memory-consuming face editing methods at a low resolution, to manipulate high-resolution (HR) facial images, i.e., typically larger than 7682 pixels, with very limited memory is still challenging. This is due to the reasons of 1) intractable huge demand of memory; 2) inefficient multi-scale features fusion. To address these issues, we propose a NOVEL pixel translation framework called Cooperative GAN(CooGAN) for HR facial image editing. This framework features a local path for fine-grained local facial patch generation (i.e., patch-level HR, LOW memory) and a global path for global lowresolution (LR) facial structure monitoring (i.e., image-level LR, LOW memory), which largely reduce memory requirements. Both paths work in a cooperative manner under a local-to-global consistency objective (i.e., for smooth stitching). In addition, we propose a lighter selective transfer unit for more efficient multi-scale features fusion, yielding higher fidelity facial attributes manipulation. Extensive experiments on CelebAHQ well demonstrate the memory efficiency as well as the high image generation quality of the proposed framework.
Loss-rescaling VQA: Revisiting Language Prior Problem from a Class-imbalance View
Oct 30, 2020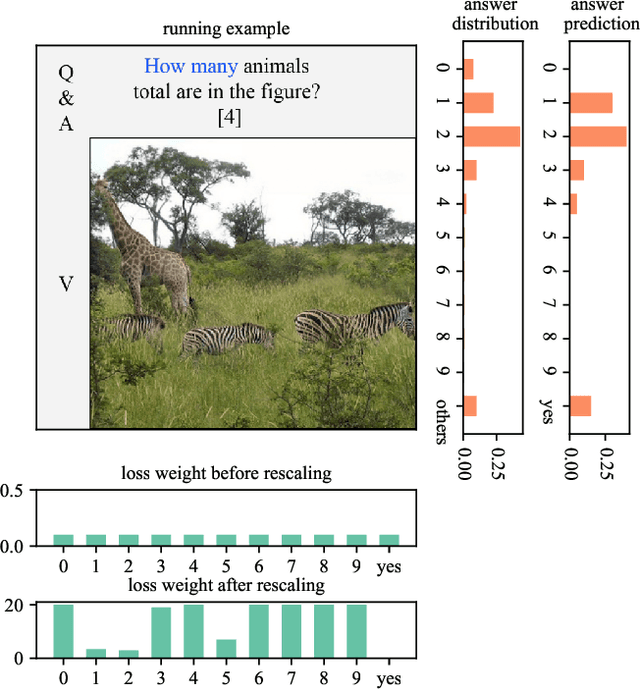
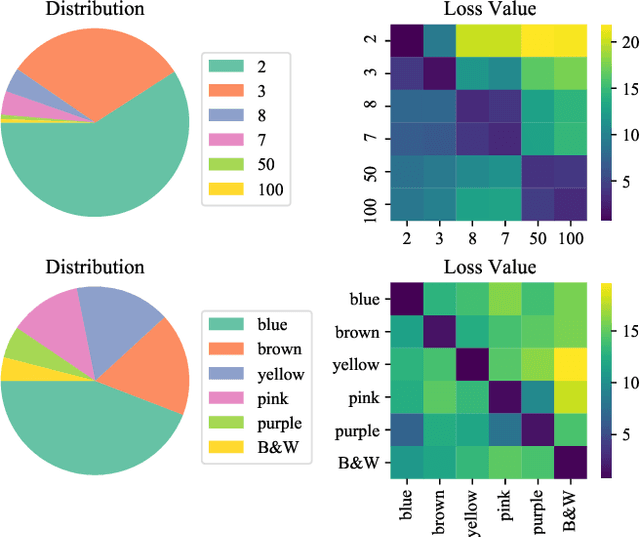
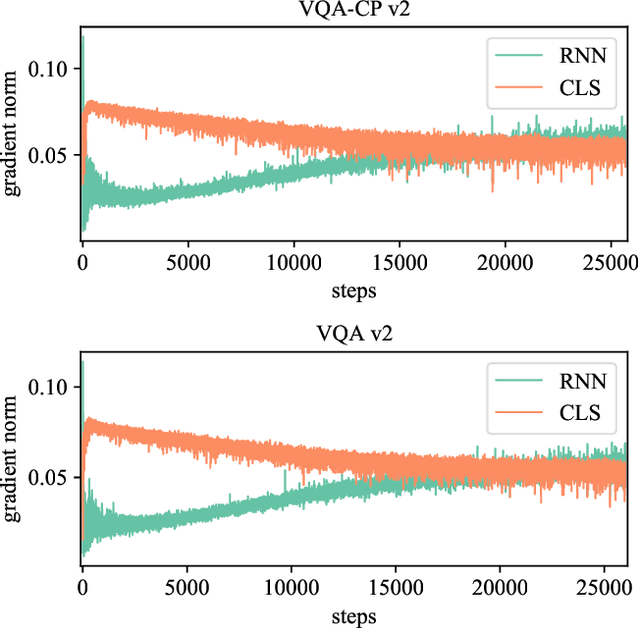
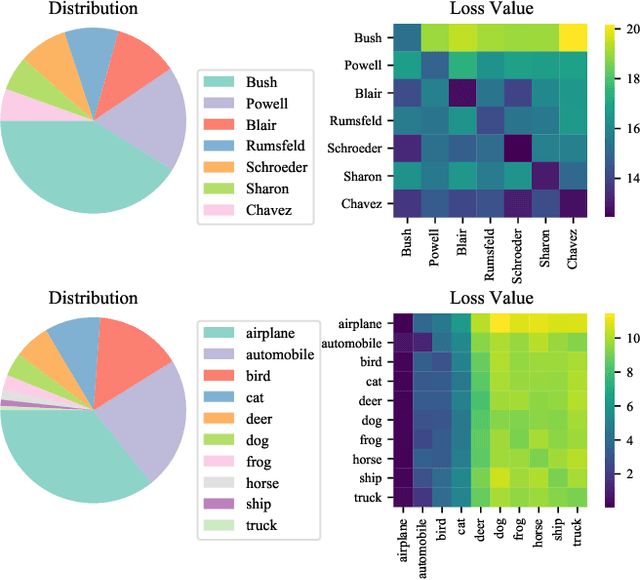
Recent studies have pointed out that many well-developed Visual Question Answering (VQA) models are heavily affected by the language prior problem, which refers to making predictions based on the co-occurrence pattern between textual questions and answers instead of reasoning visual contents. To tackle it, most existing methods focus on enhancing visual feature learning to reduce this superficial textual shortcut influence on VQA model decisions. However, limited effort has been devoted to providing an explicit interpretation for its inherent cause. It thus lacks a good guidance for the research community to move forward in a purposeful way, resulting in model construction perplexity in overcoming this non-trivial problem. In this paper, we propose to interpret the language prior problem in VQA from a class-imbalance view. Concretely, we design a novel interpretation scheme whereby the loss of mis-predicted frequent and sparse answers of the same question type is distinctly exhibited during the late training phase. It explicitly reveals why the VQA model tends to produce a frequent yet obviously wrong answer, to a given question whose right answer is sparse in the training set. Based upon this observation, we further develop a novel loss re-scaling approach to assign different weights to each answer based on the training data statistics for computing the final loss. We apply our approach into three baselines and the experimental results on two VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify the validity of the class imbalance interpretation scheme on other computer vision tasks, such as face recognition and image classification.
One-bit Supervision for Image Classification
Sep 16, 2020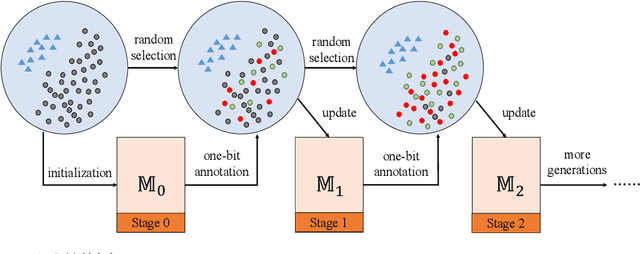

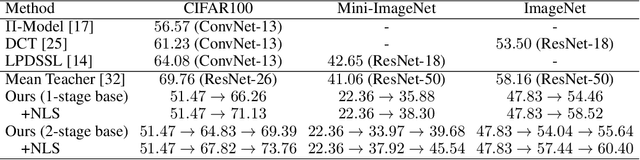
This paper presents one-bit supervision, a novel setting of learning from incomplete annotations, in the scenario of image classification. Instead of training a model upon the accurate label of each sample, our setting requires the model to query with a predicted label of each sample and learn from the answer whether the guess is correct. This provides one bit (yes or no) of information, and more importantly, annotating each sample becomes much easier than finding the accurate label from many candidate classes. There are two keys to training a model upon one-bit supervision: improving the guess accuracy and making use of incorrect guesses. For these purposes, we propose a multi-stage training paradigm which incorporates negative label suppression into an off-the-shelf semi-supervised learning algorithm. In three popular image classification benchmarks, our approach claims higher efficiency in utilizing the limited amount of annotations.
Reinforced Axial Refinement Network for Monocular 3D Object Detection
Aug 31, 2020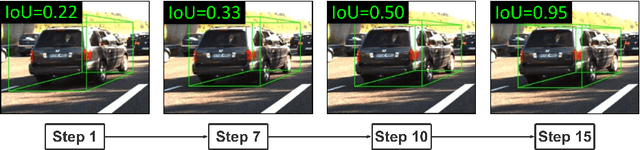
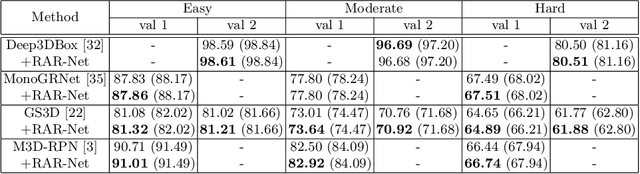
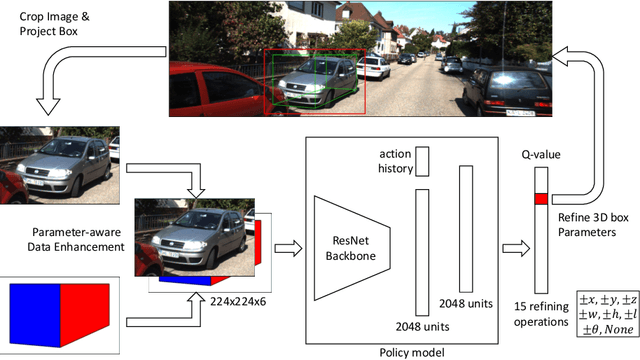
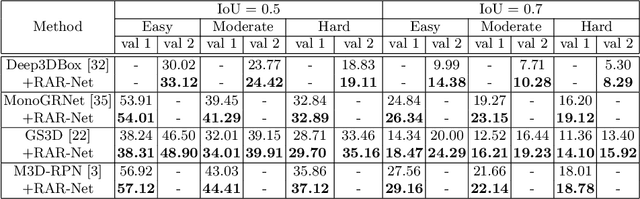
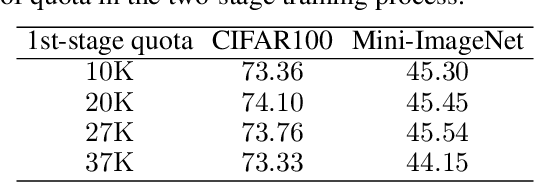
Monocular 3D object detection aims to extract the 3D position and properties of objects from a 2D input image. This is an ill-posed problem with a major difficulty lying in the information loss by depth-agnostic cameras. Conventional approaches sample 3D bounding boxes from the space and infer the relationship between the target object and each of them, however, the probability of effective samples is relatively small in the 3D space. To improve the efficiency of sampling, we propose to start with an initial prediction and refine it gradually towards the ground truth, with only one 3d parameter changed in each step. This requires designing a policy which gets a reward after several steps, and thus we adopt reinforcement learning to optimize it. The proposed framework, Reinforced Axial Refinement Network (RAR-Net), serves as a post-processing stage which can be freely integrated into existing monocular 3D detection methods, and improve the performance on the KITTI dataset with small extra computational costs.
Label Decoupling Framework for Salient Object Detection
Aug 25, 2020
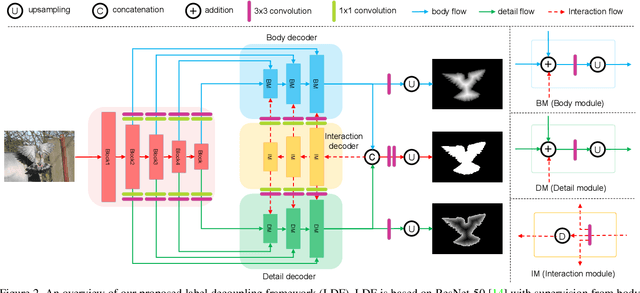
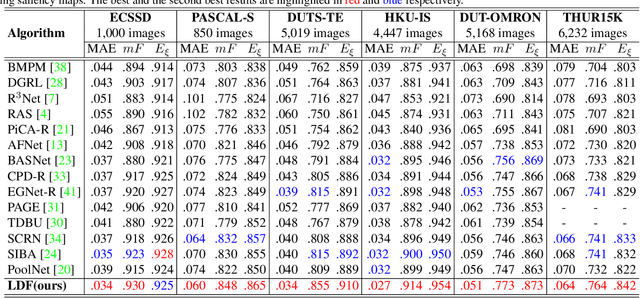

To get more accurate saliency maps, recent methods mainly focus on aggregating multi-level features from fully convolutional network (FCN) and introducing edge information as auxiliary supervision. Though remarkable progress has been achieved, we observe that the closer the pixel is to the edge, the more difficult it is to be predicted, because edge pixels have a very imbalance distribution. To address this problem, we propose a label decoupling framework (LDF) which consists of a label decoupling (LD) procedure and a feature interaction network (FIN). LD explicitly decomposes the original saliency map into body map and detail map, where body map concentrates on center areas of objects and detail map focuses on regions around edges. Detail map works better because it involves much more pixels than traditional edge supervision. Different from saliency map, body map discards edge pixels and only pays attention to center areas. This successfully avoids the distraction from edge pixels during training. Therefore, we employ two branches in FIN to deal with body map and detail map respectively. Feature interaction (FI) is designed to fuse the two complementary branches to predict the saliency map, which is then used to refine the two branches again. This iterative refinement is helpful for learning better representations and more precise saliency maps. Comprehensive experiments on six benchmark datasets demonstrate that LDF outperforms state-of-the-art approaches on different evaluation metrics.
Weight-Sharing Neural Architecture Search: A Battle to Shrink the Optimization Gap
Aug 05, 2020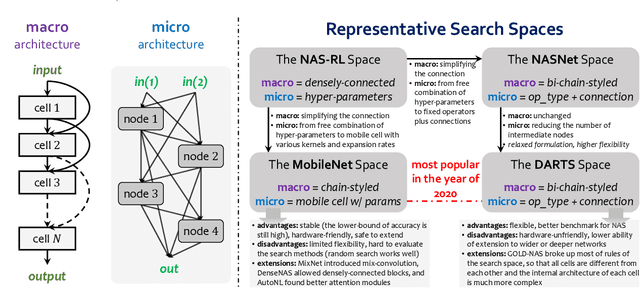
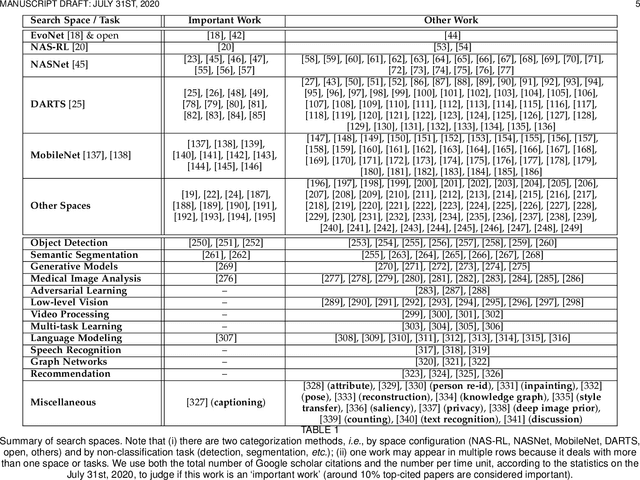
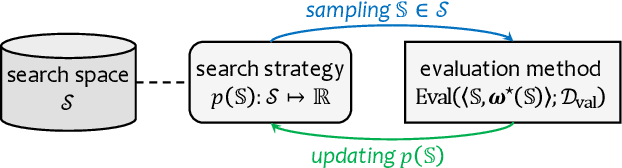
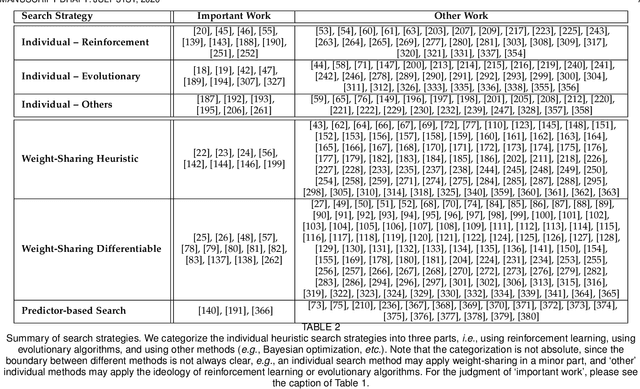
Neural architecture search (NAS) has attracted increasing attentions in both academia and industry. In the early age, researchers mostly applied individual search methods which sample and evaluate the candidate architectures separately and thus incur heavy computational overheads. To alleviate the burden, weight-sharing methods were proposed in which exponentially many architectures share weights in the same super-network, and the costly training procedure is performed only once. These methods, though being much faster, often suffer the issue of instability. This paper provides a literature review on NAS, in particular the weight-sharing methods, and points out that the major challenge comes from the optimization gap between the super-network and the sub-architectures. From this perspective, we summarize existing approaches into several categories according to their efforts in bridging the gap, and analyze both advantages and disadvantages of these methodologies. Finally, we share our opinions on the future directions of NAS and AutoML. Due to the expertise of the authors, this paper mainly focuses on the application of NAS to computer vision problems and may bias towards the work in our group.