 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClipGS: Clippable Gaussian Splatting for Interactive Cinematic Visualization of Volumetric Medical Data
Jul 09, 2025The visualization of volumetric medical data is crucial for enhancing diagnostic accuracy and improving surgical planning and education. Cinematic rendering techniques significantly enrich this process by providing high-quality visualizations that convey intricate anatomical details, thereby facilitating better understanding and decision-making in medical contexts. However, the high computing cost and low rendering speed limit the requirement of interactive visualization in practical applications. In this paper, we introduce ClipGS, an innovative Gaussian splatting framework with the clipping plane supported, for interactive cinematic visualization of volumetric medical data. To address the challenges posed by dynamic interactions, we propose a learnable truncation scheme that automatically adjusts the visibility of Gaussian primitives in response to the clipping plane. Besides, we also design an adaptive adjustment model to dynamically adjust the deformation of Gaussians and refine the rendering performance. We validate our method on five volumetric medical data (including CT and anatomical slice data), and reach an average 36.635 PSNR rendering quality with 156 FPS and 16.1 MB model size, outperforming state-of-the-art methods in rendering quality and efficiency.
Toward Reliable AR-Guided Surgical Navigation: Interactive Deformation Modeling with Data-Driven Biomechanics and Prompts
Jun 11, 2025In augmented reality (AR)-guided surgical navigation, preoperative organ models are superimposed onto the patient's intraoperative anatomy to visualize critical structures such as vessels and tumors. Accurate deformation modeling is essential to maintain the reliability of AR overlays by ensuring alignment between preoperative models and the dynamically changing anatomy. Although the finite element method (FEM) offers physically plausible modeling, its high computational cost limits intraoperative applicability. Moreover, existing algorithms often fail to handle large anatomical changes, such as those induced by pneumoperitoneum or ligament dissection, leading to inaccurate anatomical correspondences and compromised AR guidance. To address these challenges, we propose a data-driven biomechanics algorithm that preserves FEM-level accuracy while improving computational efficiency. In addition, we introduce a novel human-in-the-loop mechanism into the deformation modeling process. This enables surgeons to interactively provide prompts to correct anatomical misalignments, thereby incorporating clinical expertise and allowing the model to adapt dynamically to complex surgical scenarios. Experiments on a publicly available dataset demonstrate that our algorithm achieves a mean target registration error of 3.42 mm. Incorporating surgeon prompts through the interactive framework further reduces the error to 2.78 mm, surpassing state-of-the-art methods in volumetric accuracy. These results highlight the ability of our framework to deliver efficient and accurate deformation modeling while enhancing surgeon-algorithm collaboration, paving the way for safer and more reliable computer-assisted surgeries.
SAP-Bench: Benchmarking Multimodal Large Language Models in Surgical Action Planning
Jun 08, 2025Effective evaluation is critical for driving advancements in MLLM research. The surgical action planning (SAP) task, which aims to generate future action sequences from visual inputs, demands precise and sophisticated analytical capabilities. Unlike mathematical reasoning, surgical decision-making operates in life-critical domains and requires meticulous, verifiable processes to ensure reliability and patient safety. This task demands the ability to distinguish between atomic visual actions and coordinate complex, long-horizon procedures, capabilities that are inadequately evaluated by current benchmarks. To address this gap, we introduce SAP-Bench, a large-scale, high-quality dataset designed to enable multimodal large language models (MLLMs) to perform interpretable surgical action planning. Our SAP-Bench benchmark, derived from the cholecystectomy procedures context with the mean duration of 1137.5s, and introduces temporally-grounded surgical action annotations, comprising the 1,226 clinically validated action clips (mean duration: 68.7s) capturing five fundamental surgical actions across 74 procedures. The dataset provides 1,152 strategically sampled current frames, each paired with the corresponding next action as multimodal analysis anchors. We propose the MLLM-SAP framework that leverages MLLMs to generate next action recommendations from the current surgical scene and natural language instructions, enhanced with injected surgical domain knowledge. To assess our dataset's effectiveness and the broader capabilities of current models, we evaluate seven state-of-the-art MLLMs (e.g., OpenAI-o1, GPT-4o, QwenVL2.5-72B, Claude-3.5-Sonnet, GeminiPro2.5, Step-1o, and GLM-4v) and reveal critical gaps in next action prediction performance.
Learning dissection trajectories from expert surgical videos via imitation learning with equivariant diffusion
Jun 05, 2025



Endoscopic Submucosal Dissection (ESD) is a well-established technique for removing epithelial lesions. Predicting dissection trajectories in ESD videos offers significant potential for enhancing surgical skill training and simplifying the learning process, yet this area remains underexplored. While imitation learning has shown promise in acquiring skills from expert demonstrations, challenges persist in handling uncertain future movements, learning geometric symmetries, and generalizing to diverse surgical scenarios. To address these, we introduce a novel approach: Implicit Diffusion Policy with Equivariant Representations for Imitation Learning (iDPOE). Our method models expert behavior through a joint state action distribution, capturing the stochastic nature of dissection trajectories and enabling robust visual representation learning across various endoscopic views. By incorporating a diffusion model into policy learning, iDPOE ensures efficient training and sampling, leading to more accurate predictions and better generalization. Additionally, we enhance the model's ability to generalize to geometric symmetries by embedding equivariance into the learning process. To address state mismatches, we develop a forward-process guided action inference strategy for conditional sampling. Using an ESD video dataset of nearly 2000 clips, experimental results show that our approach surpasses state-of-the-art methods, both explicit and implicit, in trajectory prediction. To the best of our knowledge, this is the first application of imitation learning to surgical skill development for dissection trajectory prediction.
Medical Large Vision Language Models with Multi-Image Visual Ability
May 25, 2025Medical large vision-language models (LVLMs) have demonstrated promising performance across various single-image question answering (QA) benchmarks, yet their capability in processing multi-image clinical scenarios remains underexplored. Unlike single image based tasks, medical tasks involving multiple images often demand sophisticated visual understanding capabilities, such as temporal reasoning and cross-modal analysis, which are poorly supported by current medical LVLMs. To bridge this critical gap, we present the Med-MIM instruction dataset, comprising 83.2K medical multi-image QA pairs that span four types of multi-image visual abilities (temporal understanding, reasoning, comparison, co-reference). Using this dataset, we fine-tune Mantis and LLaVA-Med, resulting in two specialized medical VLMs: MIM-LLaVA-Med and Med-Mantis, both optimized for multi-image analysis. Additionally, we develop the Med-MIM benchmark to comprehensively evaluate the medical multi-image understanding capabilities of LVLMs. We assess eight popular LVLMs, including our two models, on the Med-MIM benchmark. Experimental results show that both Med-Mantis and MIM-LLaVA-Med achieve superior performance on the held-in and held-out subsets of the Med-MIM benchmark, demonstrating that the Med-MIM instruction dataset effectively enhances LVLMs' multi-image understanding capabilities in the medical domain.
Endo3R: Unified Online Reconstruction from Dynamic Monocular Endoscopic Video
Apr 04, 2025



Reconstructing 3D scenes from monocular surgical videos can enhance surgeon's perception and therefore plays a vital role in various computer-assisted surgery tasks. However, achieving scale-consistent reconstruction remains an open challenge due to inherent issues in endoscopic videos, such as dynamic deformations and textureless surfaces. Despite recent advances, current methods either rely on calibration or instrument priors to estimate scale, or employ SfM-like multi-stage pipelines, leading to error accumulation and requiring offline optimization. In this paper, we present Endo3R, a unified 3D foundation model for online scale-consistent reconstruction from monocular surgical video, without any priors or extra optimization. Our model unifies the tasks by predicting globally aligned pointmaps, scale-consistent video depths, and camera parameters without any offline optimization. The core contribution of our method is expanding the capability of the recent pairwise reconstruction model to long-term incremental dynamic reconstruction by an uncertainty-aware dual memory mechanism. The mechanism maintains history tokens of both short-term dynamics and long-term spatial consistency. Notably, to tackle the highly dynamic nature of surgical scenes, we measure the uncertainty of tokens via Sampson distance and filter out tokens with high uncertainty. Regarding the scarcity of endoscopic datasets with ground-truth depth and camera poses, we further devise a self-supervised mechanism with a novel dynamics-aware flow loss. Abundant experiments on SCARED and Hamlyn datasets demonstrate our superior performance in zero-shot surgical video depth prediction and camera pose estimation with online efficiency. Project page: https://wrld.github.io/Endo3R/.
pFedFair: Towards Optimal Group Fairness-Accuracy Trade-off in Heterogeneous Federated Learning
Mar 19, 2025Federated learning (FL) algorithms commonly aim to maximize clients' accuracy by training a model on their collective data. However, in several FL applications, the model's decisions should meet a group fairness constraint to be independent of sensitive attributes such as gender or race. While such group fairness constraints can be incorporated into the objective function of the FL optimization problem, in this work, we show that such an approach would lead to suboptimal classification accuracy in an FL setting with heterogeneous client distributions. To achieve an optimal accuracy-group fairness trade-off, we propose the Personalized Federated Learning for Client-Level Group Fairness (pFedFair) framework, where clients locally impose their fairness constraints over the distributed training process. Leveraging the image embedding models, we extend the application of pFedFair to computer vision settings, where we numerically show that pFedFair achieves an optimal group fairness-accuracy trade-off in heterogeneous FL settings. We present the results of several numerical experiments on benchmark and synthetic datasets, which highlight the suboptimality of non-personalized FL algorithms and the improvements made by the pFedFair method.
WonderVerse: Extendable 3D Scene Generation with Video Generative Models
Mar 13, 2025We introduce \textit{WonderVerse}, a simple but effective framework for generating extendable 3D scenes. Unlike existing methods that rely on iterative depth estimation and image inpainting, often leading to geometric distortions and inconsistencies, WonderVerse leverages the powerful world-level priors embedded within video generative foundation models to create highly immersive and geometrically coherent 3D environments. Furthermore, we propose a new technique for controllable 3D scene extension to substantially increase the scale of the generated environments. Besides, we introduce a novel abnormal sequence detection module that utilizes camera trajectory to address geometric inconsistency in the generated videos. Finally, WonderVerse is compatible with various 3D reconstruction methods, allowing both efficient and high-quality generation. Extensive experiments on 3D scene generation demonstrate that our WonderVerse, with an elegant and simple pipeline, delivers extendable and highly-realistic 3D scenes, markedly outperforming existing works that rely on more complex architectures.
Towards Universal Learning-based Model for Cardiac Image Reconstruction: Summary of the CMRxRecon2024 Challenge
Mar 05, 2025Cardiovascular magnetic resonance (CMR) offers diverse imaging contrasts for assessment of cardiac function and tissue characterization. However, acquiring each single CMR modality is often time-consuming, and comprehensive clinical protocols require multiple modalities with various sampling patterns, further extending the overall acquisition time and increasing susceptibility to motion artifacts. Existing deep learning-based reconstruction methods are often designed for specific acquisition parameters, which limits their ability to generalize across a variety of scan scenarios. As part of the CMRxRecon Series, the CMRxRecon2024 challenge provides diverse datasets encompassing multi-modality multi-view imaging with various sampling patterns, and a platform for the international community to develop and benchmark reconstruction solutions in two well-crafted tasks. Task 1 is a modality-universal setting, evaluating the out-of-distribution generalization of the reconstructed model, while Task 2 follows sampling-universal setting assessing the one-for-all adaptability of the universal model. Main contributions include providing the first and largest publicly available multi-modality, multi-view cardiac k-space dataset; developing a benchmarking platform that simulates clinical acceleration protocols, with a shared code library and tutorial for various k-t undersampling patterns and data processing; giving technical insights of enhanced data consistency based on physic-informed networks and adaptive prompt-learning embedding to be versatile to different clinical settings; additional finding on evaluation metrics to address the limitations of conventional ground-truth references in universal reconstruction tasks.
Diffusion Stabilizer Policy for Automated Surgical Robot Manipulations
Mar 03, 2025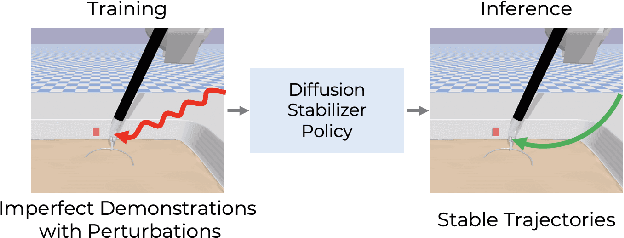
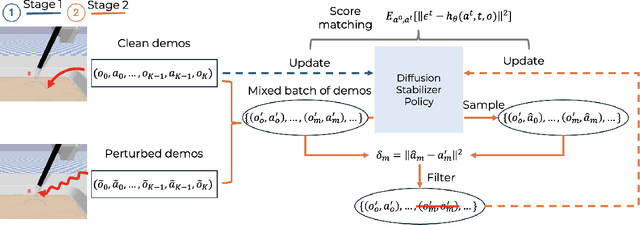
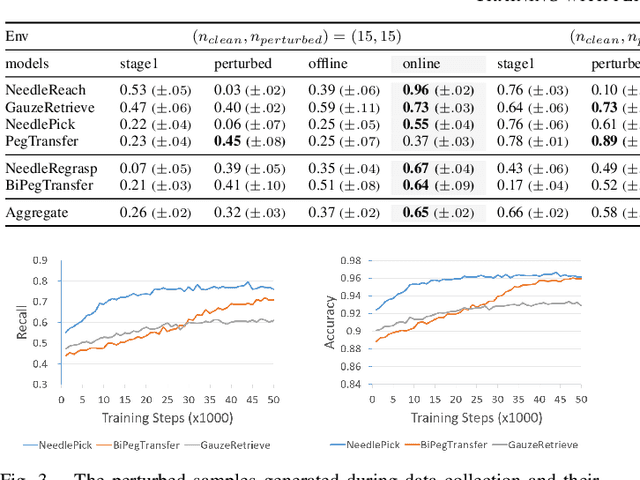
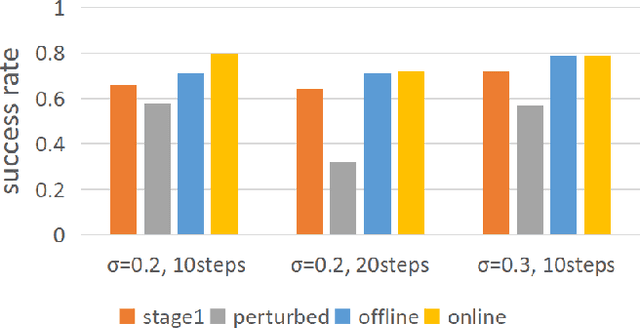
Intelligent surgical robots have the potential to revolutionize clinical practice by enabling more precise and automated surgical procedures. However, the automation of such robot for surgical tasks remains under-explored compared to recent advancements in solving household manipulation tasks. These successes have been largely driven by (1) advanced models, such as transformers and diffusion models, and (2) large-scale data utilization. Aiming to extend these successes to the domain of surgical robotics, we propose a diffusion-based policy learning framework, called Diffusion Stabilizer Policy (DSP), which enables training with imperfect or even failed trajectories. Our approach consists of two stages: first, we train the diffusion stabilizer policy using only clean data. Then, the policy is continuously updated using a mixture of clean and perturbed data, with filtering based on the prediction error on actions. Comprehensive experiments conducted in various surgical environments demonstrate the superior performance of our method in perturbation-free settings and its robustness when handling perturbed demonstrations.