 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSSP: Diffusion State Space Policy with Full-History Encoding
May 14, 2026Diffusion-based imitation learning has shown strong promise for robot manipulation. However, most existing policies condition only on the current observation or a short window of recent observations, limiting their ability to resolve history-dependent ambiguities in long-horizon tasks. To address this, we introduce DSSP, a history-conditioned Diffusion State Space Policy that enables efficient, full-history conditioning for robot manipulation. Leveraging the continuous sequence modeling properties of State Space Models (SSMs), our history encoder effectively compresses the entire observation stream into a compact context representation. To ensure this context preserves critical information regarding future state evolution, the encoder is optimized with a dynamics-aware auxiliary training objective. This high-level context representation is then seamlessly fused with recent state observations to form a hierarchical conditioning mechanism for action generation. Furthermore, to maintain architectural consistency and minimize GPU memory overhead, we also instantiate the diffusion backbone itself using an SSM. Extensive experiments across simulation benchmarks and real-world manipulation tasks show that DSSP achieves state-of-the-art performance with a significantly smaller model size, demonstrating superior efficiency of the hierarchical conditioning in capturing crucial information as the history length increases.
Time Reversal Symmetry for Efficient Robotic Manipulations in Deep Reinforcement Learning
May 20, 2025Symmetry is pervasive in robotics and has been widely exploited to improve sample efficiency in deep reinforcement learning (DRL). However, existing approaches primarily focus on spatial symmetries, such as reflection, rotation, and translation, while largely neglecting temporal symmetries. To address this gap, we explore time reversal symmetry, a form of temporal symmetry commonly found in robotics tasks such as door opening and closing. We propose Time Reversal symmetry enhanced Deep Reinforcement Learning (TR-DRL), a framework that combines trajectory reversal augmentation and time reversal guided reward shaping to efficiently solve temporally symmetric tasks. Our method generates reversed transitions from fully reversible transitions, identified by a proposed dynamics-consistent filter, to augment the training data. For partially reversible transitions, we apply reward shaping to guide learning, according to successful trajectories from the reversed task. Extensive experiments on the Robosuite and MetaWorld benchmarks demonstrate that TR-DRL is effective in both single-task and multi-task settings, achieving higher sample efficiency and stronger final performance compared to baseline methods.
Diffusion Stabilizer Policy for Automated Surgical Robot Manipulations
Mar 03, 2025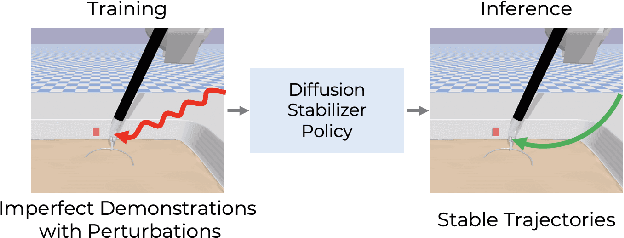
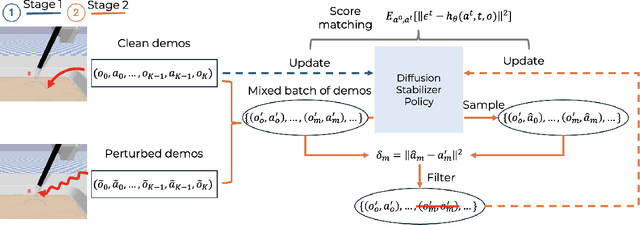
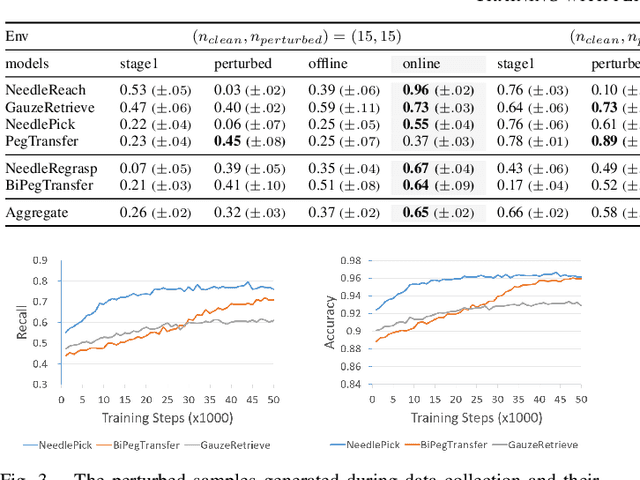
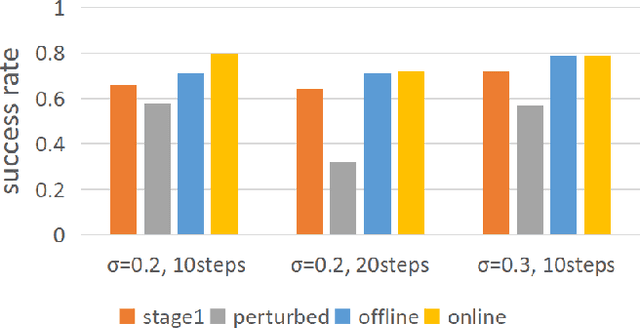
Intelligent surgical robots have the potential to revolutionize clinical practice by enabling more precise and automated surgical procedures. However, the automation of such robot for surgical tasks remains under-explored compared to recent advancements in solving household manipulation tasks. These successes have been largely driven by (1) advanced models, such as transformers and diffusion models, and (2) large-scale data utilization. Aiming to extend these successes to the domain of surgical robotics, we propose a diffusion-based policy learning framework, called Diffusion Stabilizer Policy (DSP), which enables training with imperfect or even failed trajectories. Our approach consists of two stages: first, we train the diffusion stabilizer policy using only clean data. Then, the policy is continuously updated using a mixture of clean and perturbed data, with filtering based on the prediction error on actions. Comprehensive experiments conducted in various surgical environments demonstrate the superior performance of our method in perturbation-free settings and its robustness when handling perturbed demonstrations.
State-Novelty Guided Action Persistence in Deep Reinforcement Learning
Sep 09, 2024While a powerful and promising approach, deep reinforcement learning (DRL) still suffers from sample inefficiency, which can be notably improved by resorting to more sophisticated techniques to address the exploration-exploitation dilemma. One such technique relies on action persistence (i.e., repeating an action over multiple steps). However, previous work exploiting action persistence either applies a fixed strategy or learns additional value functions (or policy) for selecting the repetition number. In this paper, we propose a novel method to dynamically adjust the action persistence based on the current exploration status of the state space. In such a way, our method does not require training of additional value functions or policy. Moreover, the use of a smooth scheduling of the repeat probability allows a more effective balance between exploration and exploitation. Furthermore, our method can be seamlessly integrated into various basic exploration strategies to incorporate temporal persistence. Finally, extensive experiments on different DMControl tasks demonstrate that our state-novelty guided action persistence method significantly improves the sample efficiency.
Revisiting Data Augmentation in Deep Reinforcement Learning
Feb 19, 2024



Various data augmentation techniques have been recently proposed in image-based deep reinforcement learning (DRL). Although they empirically demonstrate the effectiveness of data augmentation for improving sample efficiency or generalization, which technique should be preferred is not always clear. To tackle this question, we analyze existing methods to better understand them and to uncover how they are connected. Notably, by expressing the variance of the Q-targets and that of the empirical actor/critic losses of these methods, we can analyze the effects of their different components and compare them. We furthermore formulate an explanation about how these methods may be affected by choosing different data augmentation transformations in calculating the target Q-values. This analysis suggests recommendations on how to exploit data augmentation in a more principled way. In addition, we include a regularization term called tangent prop, previously proposed in computer vision, but whose adaptation to DRL is novel to the best of our knowledge. We evaluate our proposition and validate our analysis in several domains. Compared to different relevant baselines, we demonstrate that it achieves state-of-the-art performance in most environments and shows higher sample efficiency and better generalization ability in some complex environments.
Beyond Inverted Pendulums: Task-optimal Simple Models of Legged Locomotion
Jan 05, 2023Reduced-order models (ROM) are popular in online motion planning due to their simplicity. A good ROM captures the bulk of the full model's dynamics while remaining low dimension. However, planning within the reduced-order space unavoidably constrains the full model, and hence we sacrifice the full potential of the robot. In the community of legged locomotion, this has lead to a search for better model extensions, but many of these extensions require human intuition, and there has not existed a principled way of evaluating the model performance and discovering new models. In this work, we propose a model optimization algorithm that automatically synthesizes reduced-order models, optimal with respect to any user-specified cost function. To demonstrate our work, we optimized models for a bipedal robot Cassie. We show in hardware experiment that the optimal ROM is simple enough for real time planning application and that the real robot achieves higher performance by using the optimal ROM.