 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
Dec 26, 2025Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.
Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Dec 19, 2025Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.
ViewMask-1-to-3: Multi-View Consistent Image Generation via Multimodal Diffusion Models
Dec 16, 2025



Multi-view image generation from a single image and text description remains challenging due to the difficulty of maintaining geometric consistency across different viewpoints. Existing approaches typically rely on 3D-aware architectures or specialized diffusion models that require extensive multi-view training data and complex geometric priors. In this work, we introduce ViewMask-1-to-3, a pioneering approach to apply discrete diffusion models to multi-view image generation. Unlike continuous diffusion methods that operate in latent spaces, ViewMask-1-to-3 formulates multi-view synthesis as a discrete sequence modeling problem, where each viewpoint is represented as visual tokens obtained through MAGVIT-v2 tokenization. By unifying language and vision through masked token prediction, our approach enables progressive generation of multiple viewpoints through iterative token unmasking with text input. ViewMask-1-to-3 achieves cross-view consistency through simple random masking combined with self-attention, eliminating the requirement for complex 3D geometric constraints or specialized attention architectures. Our approach demonstrates that discrete diffusion provides a viable and simple alternative to existing multi-view generation methods, ranking first on average across GSO and 3D-FUTURE datasets in terms of PSNR, SSIM, and LPIPS, while maintaining architectural simplicity.
Laytrol: Preserving Pretrained Knowledge in Layout Control for Multimodal Diffusion Transformers
Nov 11, 2025With the development of diffusion models, enhancing spatial controllability in text-to-image generation has become a vital challenge. As a representative task for addressing this challenge, layout-to-image generation aims to generate images that are spatially consistent with the given layout condition. Existing layout-to-image methods typically introduce the layout condition by integrating adapter modules into the base generative model. However, the generated images often exhibit low visual quality and stylistic inconsistency with the base model, indicating a loss of pretrained knowledge. To alleviate this issue, we construct the Layout Synthesis (LaySyn) dataset, which leverages images synthesized by the base model itself to mitigate the distribution shift from the pretraining data. Moreover, we propose the Layout Control (Laytrol) Network, in which parameters are inherited from MM-DiT to preserve the pretrained knowledge of the base model. To effectively activate the copied parameters and avoid disturbance from unstable control conditions, we adopt a dedicated initialization scheme for Laytrol. In this scheme, the layout encoder is initialized as a pure text encoder to ensure that its output tokens remain within the data domain of MM-DiT. Meanwhile, the outputs of the layout control network are initialized to zero. In addition, we apply Object-level Rotary Position Embedding to the layout tokens to provide coarse positional information. Qualitative and quantitative experiments demonstrate the effectiveness of our method.
Reasoning Pattern Matters: Learning to Reason without Human Rationales
Oct 14, 2025



Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities under the widely adopted SFT+RLVR paradigm, which first performs Supervised Fine-Tuning (SFT) on human-annotated reasoning trajectories (rationales) to establish initial reasoning behaviors, then applies Reinforcement Learning with Verifiable Rewards (RLVR) to optimize the model using verifiable signals without golden rationales. However, annotating high-quality rationales for the SFT stage remains prohibitively expensive. This paper investigates when and how rationale annotation costs can be substantially reduced without compromising reasoning performance. We identify a broad class of problems, termed patterned reasoning tasks, where reasoning follows a fixed, procedural strategy consistent across instances. Although instances vary in content such as domain knowledge, factual information, or numeric values, the solution derives from applying a shared reasoning pattern. We argue that the success of SFT+RLVR on such tasks primarily stems from its ability to enable models to internalize these reasoning patterns. Using numerical semantic matching as a representative task, we provide both causal and behavioral evidence showing that reasoning patterns rather than the quantity or quality of rationales are the key determinant of performance. Building on these insights, we propose Pattern-Aware LLMs as Rationale AnnOtators (PARO), a simple yet effective framework that enables LLMs to generate rationales aligned with task-specific reasoning patterns without requiring human rationale annotations. Experiments show that PARO-generated rationales achieve comparable SFT+RLVR performance to human rationales that are 10 times larger. These results suggest that large-scale human rationale annotations can be replaced with LLM-based automatic annotations requiring only limited human supervision over reasoning patterns.
A Generative Foundation Model for Chest Radiography
Sep 04, 2025The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.
Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
Aug 27, 2025Vision-Language-Action (VLA) models adapt large vision-language backbones to map images and instructions to robot actions. However, prevailing VLA decoders either generate actions autoregressively in a fixed left-to-right order or attach continuous diffusion or flow matching heads outside the backbone, demanding specialized training and iterative sampling that hinder a unified, scalable architecture. We present Discrete Diffusion VLA, a single-transformer policy that models discretized action chunks with discrete diffusion and is trained with the same cross-entropy objective as the VLM backbone. The design retains diffusion's progressive refinement paradigm while remaining natively compatible with the discrete token interface of VLMs. Our method achieves an adaptive decoding order that resolves easy action elements before harder ones and uses secondary remasking to revisit uncertain predictions across refinement rounds, which improves consistency and enables robust error correction. This unified decoder preserves pretrained vision language priors, supports parallel decoding, breaks the autoregressive bottleneck, and reduces the number of function evaluations. Discrete Diffusion VLA achieves 96.3% avg. SR on LIBERO, 71.2% visual matching on SimplerEnv Fractal and 49.3% overall on SimplerEnv Bridge, improving over both autoregressive and continuous diffusion baselines. These findings indicate that discrete-diffusion action decoder supports precise action modeling and consistent training, laying groundwork for scaling VLA to larger models and datasets.
SWIRL: A Staged Workflow for Interleaved Reinforcement Learning in Mobile GUI Control
Aug 27, 2025



The rapid advancement of large vision language models (LVLMs) and agent systems has heightened interest in mobile GUI agents that can reliably translate natural language into interface operations. Existing single-agent approaches, however, remain limited by structural constraints. Although multi-agent systems naturally decouple different competencies, recent progress in multi-agent reinforcement learning (MARL) has often been hindered by inefficiency and remains incompatible with current LVLM architectures. To address these challenges, we introduce SWIRL, a staged workflow for interleaved reinforcement learning designed for multi-agent systems. SWIRL reformulates MARL into a sequence of single-agent reinforcement learning tasks, updating one agent at a time while keeping the others fixed. This formulation enables stable training and promotes efficient coordination across agents. Theoretically, we provide a stepwise safety bound, a cross-round monotonic improvement theorem, and convergence guarantees on return, ensuring robust and principled optimization. In application to mobile GUI control, SWIRL instantiates a Navigator that converts language and screen context into structured plans, and an Interactor that grounds these plans into executable atomic actions. Extensive experiments demonstrate superior performance on both high-level and low-level GUI benchmarks. Beyond GUI tasks, SWIRL also demonstrates strong capability in multi-agent mathematical reasoning, underscoring its potential as a general framework for developing efficient and robust multi-agent systems.
BOOD: Boundary-based Out-Of-Distribution Data Generation
Aug 01, 2025


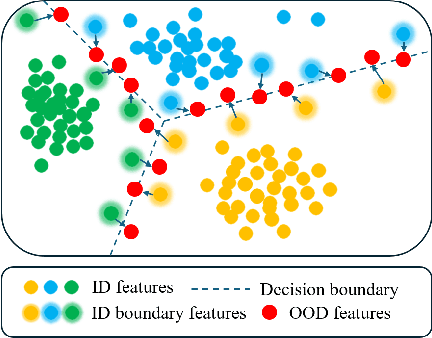
Harnessing the power of diffusion models to synthesize auxiliary training data based on latent space features has proven effective in enhancing out-of-distribution (OOD) detection performance. However, extracting effective features outside the in-distribution (ID) boundary in latent space remains challenging due to the difficulty of identifying decision boundaries between classes. This paper proposes a novel framework called Boundary-based Out-Of-Distribution data generation (BOOD), which synthesizes high-quality OOD features and generates human-compatible outlier images using diffusion models. BOOD first learns a text-conditioned latent feature space from the ID dataset, selects ID features closest to the decision boundary, and perturbs them to cross the decision boundary to form OOD features. These synthetic OOD features are then decoded into images in pixel space by a diffusion model. Compared to previous works, BOOD provides a more training efficient strategy for synthesizing informative OOD features, facilitating clearer distinctions between ID and OOD data. Extensive experimental results on common benchmarks demonstrate that BOOD surpasses the state-of-the-art method significantly, achieving a 29.64% decrease in average FPR95 (40.31% vs. 10.67%) and a 7.27% improvement in average AUROC (90.15% vs. 97.42%) on the CIFAR-100 dataset.
Is Diversity All You Need for Scalable Robotic Manipulation?
Jul 08, 2025Data scaling has driven remarkable success in foundation models for Natural Language Processing (NLP) and Computer Vision (CV), yet the principles of effective data scaling in robotic manipulation remain insufficiently understood. In this work, we investigate the nuanced role of data diversity in robot learning by examining three critical dimensions-task (what to do), embodiment (which robot to use), and expert (who demonstrates)-challenging the conventional intuition of "more diverse is better". Throughout extensive experiments on various robot platforms, we reveal that (1) task diversity proves more critical than per-task demonstration quantity, benefiting transfer from diverse pre-training tasks to novel downstream scenarios; (2) multi-embodiment pre-training data is optional for cross-embodiment transfer-models trained on high-quality single-embodiment data can efficiently transfer to different platforms, showing more desirable scaling property during fine-tuning than multi-embodiment pre-trained models; and (3) expert diversity, arising from individual operational preferences and stochastic variations in human demonstrations, can be confounding to policy learning, with velocity multimodality emerging as a key contributing factor. Based on this insight, we propose a distribution debiasing method to mitigate velocity ambiguity, the yielding GO-1-Pro achieves substantial performance gains of 15%, equivalent to using 2.5 times pre-training data. Collectively, these findings provide new perspectives and offer practical guidance on how to scale robotic manipulation datasets effectively.