 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTaMIn: Learning Contact-Rich Tasks Through Robot-Free Visuo-Tactile Manipulation Interface
Apr 08, 2025Tactile information plays a crucial role for humans and robots to interact effectively with their environment, particularly for tasks requiring the understanding of contact properties. Solving such dexterous manipulation tasks often relies on imitation learning from demonstration datasets, which are typically collected via teleoperation systems and often demand substantial time and effort. To address these challenges, we present ViTaMIn, an embodiment-free manipulation interface that seamlessly integrates visual and tactile sensing into a hand-held gripper, enabling data collection without the need for teleoperation. Our design employs a compliant Fin Ray gripper with tactile sensing, allowing operators to perceive force feedback during manipulation for more intuitive operation. Additionally, we propose a multimodal representation learning strategy to obtain pre-trained tactile representations, improving data efficiency and policy robustness. Experiments on seven contact-rich manipulation tasks demonstrate that ViTaMIn significantly outperforms baseline methods, demonstrating its effectiveness for complex manipulation tasks.
Intrinsically-Motivated Humans and Agents in Open-World Exploration
Mar 31, 2025What drives exploration? Understanding intrinsic motivation is a long-standing challenge in both cognitive science and artificial intelligence; numerous objectives have been proposed and used to train agents, yet there remains a gap between human and agent exploration. We directly compare adults, children, and AI agents in a complex open-ended environment, Crafter, and study how common intrinsic objectives: Entropy, Information Gain, and Empowerment, relate to their behavior. We find that only Entropy and Empowerment are consistently positively correlated with human exploration progress, indicating that these objectives may better inform intrinsic reward design for agents. Furthermore, across agents and humans we observe that Entropy initially increases rapidly, then plateaus, while Empowerment increases continuously, suggesting that state diversity may provide more signal in early exploration, while advanced exploration should prioritize control. Finally, we find preliminary evidence that private speech utterances, and particularly goal verbalizations, may aid exploration in children.
RoboCopilot: Human-in-the-loop Interactive Imitation Learning for Robot Manipulation
Mar 10, 2025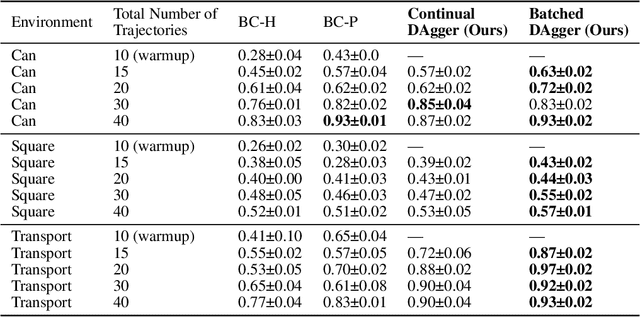

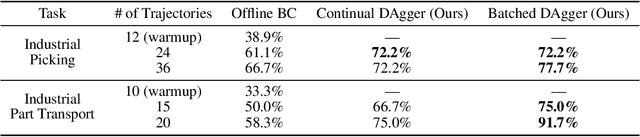

Learning from human demonstration is an effective approach for learning complex manipulation skills. However, existing approaches heavily focus on learning from passive human demonstration data for its simplicity in data collection. Interactive human teaching has appealing theoretical and practical properties, but they are not well supported by existing human-robot interfaces. This paper proposes a novel system that enables seamless control switching between human and an autonomous policy for bi-manual manipulation tasks, enabling more efficient learning of new tasks. This is achieved through a compliant, bilateral teleoperation system. Through simulation and hardware experiments, we demonstrate the value of our system in an interactive human teaching for learning complex bi-manual manipulation skills.
Geometric Retargeting: A Principled, Ultrafast Neural Hand Retargeting Algorithm
Mar 10, 2025We introduce Geometric Retargeting (GeoRT), an ultrafast, and principled neural hand retargeting algorithm for teleoperation, developed as part of our recent Dexterity Gen (DexGen) system. GeoRT converts human finger keypoints to robot hand keypoints at 1KHz, achieving state-of-the-art speed and accuracy with significantly fewer hyperparameters. This high-speed capability enables flexible postprocessing, such as leveraging a foundational controller for action correction like DexGen. GeoRT is trained in an unsupervised manner, eliminating the need for manual annotation of hand pairs. The core of GeoRT lies in novel geometric objective functions that capture the essence of retargeting: preserving motion fidelity, ensuring configuration space (C-space) coverage, maintaining uniform response through high flatness, pinch correspondence and preventing self-collisions. This approach is free from intensive test-time optimization, offering a more scalable and practical solution for real-time hand retargeting.
OTTER: A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
Mar 05, 2025



Vision-Language-Action (VLA) models aim to predict robotic actions based on visual observations and language instructions. Existing approaches require fine-tuning pre-trained visionlanguage models (VLMs) as visual and language features are independently fed into downstream policies, degrading the pre-trained semantic alignments. We propose OTTER, a novel VLA architecture that leverages these existing alignments through explicit, text-aware visual feature extraction. Instead of processing all visual features, OTTER selectively extracts and passes only task-relevant visual features that are semantically aligned with the language instruction to the policy transformer. This allows OTTER to keep the pre-trained vision-language encoders frozen. Thereby, OTTER preserves and utilizes the rich semantic understanding learned from large-scale pre-training, enabling strong zero-shot generalization capabilities. In simulation and real-world experiments, OTTER significantly outperforms existing VLA models, demonstrating strong zeroshot generalization to novel objects and environments. Video, code, checkpoints, and dataset: https://ottervla.github.io/.
MuJoCo Playground
Feb 12, 2025We introduce MuJoCo Playground, a fully open-source framework for robot learning built with MJX, with the express goal of streamlining simulation, training, and sim-to-real transfer onto robots. With a simple "pip install playground", researchers can train policies in minutes on a single GPU. Playground supports diverse robotic platforms, including quadrupeds, humanoids, dexterous hands, and robotic arms, enabling zero-shot sim-to-real transfer from both state and pixel inputs. This is achieved through an integrated stack comprising a physics engine, batch renderer, and training environments. Along with video results, the entire framework is freely available at playground.mujoco.org
DexterityGen: Foundation Controller for Unprecedented Dexterity
Feb 06, 2025



Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.
Value-Based Deep RL Scales Predictably
Feb 06, 2025Scaling data and compute is critical to the success of machine learning. However, scaling demands predictability: we want methods to not only perform well with more compute or data, but also have their performance be predictable from small-scale runs, without running the large-scale experiment. In this paper, we show that value-based off-policy RL methods are predictable despite community lore regarding their pathological behavior. First, we show that data and compute requirements to attain a given performance level lie on a Pareto frontier, controlled by the updates-to-data (UTD) ratio. By estimating this frontier, we can predict this data requirement when given more compute, and this compute requirement when given more data. Second, we determine the optimal allocation of a total resource budget across data and compute for a given performance and use it to determine hyperparameters that maximize performance for a given budget. Third, this scaling behavior is enabled by first estimating predictable relationships between hyperparameters, which is used to manage effects of overfitting and plasticity loss unique to RL. We validate our approach using three algorithms: SAC, BRO, and PQL on DeepMind Control, OpenAI gym, and IsaacGym, when extrapolating to higher levels of data, compute, budget, or performance.
Beyond Sight: Finetuning Generalist Robot Policies with Heterogeneous Sensors via Language Grounding
Jan 08, 2025Interacting with the world is a multi-sensory experience: achieving effective general-purpose interaction requires making use of all available modalities -- including vision, touch, and audio -- to fill in gaps from partial observation. For example, when vision is occluded reaching into a bag, a robot should rely on its senses of touch and sound. However, state-of-the-art generalist robot policies are typically trained on large datasets to predict robot actions solely from visual and proprioceptive observations. In this work, we propose FuSe, a novel approach that enables finetuning visuomotor generalist policies on heterogeneous sensor modalities for which large datasets are not readily available by leveraging natural language as a common cross-modal grounding. We combine a multimodal contrastive loss with a sensory-grounded language generation loss to encode high-level semantics. In the context of robot manipulation, we show that FuSe enables performing challenging tasks that require reasoning jointly over modalities such as vision, touch, and sound in a zero-shot setting, such as multimodal prompting, compositional cross-modal prompting, and descriptions of objects it interacts with. We show that the same recipe is applicable to widely different generalist policies, including both diffusion-based generalist policies and large vision-language-action (VLA) models. Extensive experiments in the real world show that FuSeis able to increase success rates by over 20% compared to all considered baselines.
MaxInfoRL: Boosting exploration in reinforcement learning through information gain maximization
Dec 16, 2024



Reinforcement learning (RL) algorithms aim to balance exploiting the current best strategy with exploring new options that could lead to higher rewards. Most common RL algorithms use undirected exploration, i.e., select random sequences of actions. Exploration can also be directed using intrinsic rewards, such as curiosity or model epistemic uncertainty. However, effectively balancing task and intrinsic rewards is challenging and often task-dependent. In this work, we introduce a framework, MaxInfoRL, for balancing intrinsic and extrinsic exploration. MaxInfoRL steers exploration towards informative transitions, by maximizing intrinsic rewards such as the information gain about the underlying task. When combined with Boltzmann exploration, this approach naturally trades off maximization of the value function with that of the entropy over states, rewards, and actions. We show that our approach achieves sublinear regret in the simplified setting of multi-armed bandits. We then apply this general formulation to a variety of off-policy model-free RL methods for continuous state-action spaces, yielding novel algorithms that achieve superior performance across hard exploration problems and complex scenarios such as visual control tasks.