 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-World Adverse Weather Image Restoration: Enhancing Clearness and Semantics with Vision-Language Models
Sep 03, 2024



This paper addresses the limitations of adverse weather image restoration approaches trained on synthetic data when applied to real-world scenarios. We formulate a semi-supervised learning framework employing vision-language models to enhance restoration performance across diverse adverse weather conditions in real-world settings. Our approach involves assessing image clearness and providing semantics using vision-language models on real data, serving as supervision signals for training restoration models. For clearness enhancement, we use real-world data, utilizing a dual-step strategy with pseudo-labels assessed by vision-language models and weather prompt learning. For semantic enhancement, we integrate real-world data by adjusting weather conditions in vision-language model descriptions while preserving semantic meaning. Additionally, we introduce an effective training strategy to bootstrap restoration performance. Our approach achieves superior results in real-world adverse weather image restoration, demonstrated through qualitative and quantitative comparisons with state-of-the-art works.
Unveiling Deep Shadows: A Survey on Image and Video Shadow Detection, Removal, and Generation in the Era of Deep Learning
Sep 03, 2024



Shadows are formed when light encounters obstacles, leading to areas of diminished illumination. In computer vision, shadow detection, removal, and generation are crucial for enhancing scene understanding, refining image quality, ensuring visual consistency in video editing, and improving virtual environments. This paper presents a comprehensive survey of shadow detection, removal, and generation in images and videos within the deep learning landscape over the past decade, covering tasks, deep models, datasets, and evaluation metrics. Our key contributions include a comprehensive survey of shadow analysis, standardization of experimental comparisons, exploration of the relationships among model size, speed, and performance, a cross-dataset generalization study, identification of open issues and future directions, and provision of publicly available resources to support further research.
SAM2Point: Segment Any 3D as Videos in Zero-shot and Promptable Manners
Aug 29, 2024



We introduce SAM2Point, a preliminary exploration adapting Segment Anything Model 2 (SAM 2) for zero-shot and promptable 3D segmentation. SAM2Point interprets any 3D data as a series of multi-directional videos, and leverages SAM 2 for 3D-space segmentation, without further training or 2D-3D projection. Our framework supports various prompt types, including 3D points, boxes, and masks, and can generalize across diverse scenarios, such as 3D objects, indoor scenes, outdoor environments, and raw sparse LiDAR. Demonstrations on multiple 3D datasets, e.g., Objaverse, S3DIS, ScanNet, Semantic3D, and KITTI, highlight the robust generalization capabilities of SAM2Point. To our best knowledge, we present the most faithful implementation of SAM in 3D, which may serve as a starting point for future research in promptable 3D segmentation. Online Demo: https://huggingface.co/spaces/ZiyuG/SAM2Point . Code: https://github.com/ZiyuGuo99/SAM2Point .
Surgical Workflow Recognition and Blocking Effectiveness Detection in Laparoscopic Liver Resections with Pringle Maneuver
Aug 21, 2024



Pringle maneuver (PM) in laparoscopic liver resection aims to reduce blood loss and provide a clear surgical view by intermittently blocking blood inflow of the liver, whereas prolonged PM may cause ischemic injury. To comprehensively monitor this surgical procedure and provide timely warnings of ineffective and prolonged blocking, we suggest two complementary AI-assisted surgical monitoring tasks: workflow recognition and blocking effectiveness detection in liver resections. The former presents challenges in real-time capturing of short-term PM, while the latter involves the intraoperative discrimination of long-term liver ischemia states. To address these challenges, we meticulously collect a novel dataset, called PmLR50, consisting of 25,037 video frames covering various surgical phases from 50 laparoscopic liver resection procedures. Additionally, we develop an online baseline for PmLR50, termed PmNet. This model embraces Masked Temporal Encoding (MTE) and Compressed Sequence Modeling (CSM) for efficient short-term and long-term temporal information modeling, and embeds Contrastive Prototype Separation (CPS) to enhance action discrimination between similar intraoperative operations. Experimental results demonstrate that PmNet outperforms existing state-of-the-art surgical workflow recognition methods on the PmLR50 benchmark. Our research offers potential clinical applications for the laparoscopic liver surgery community. Source code and data will be publicly available.
G2Face: High-Fidelity Reversible Face Anonymization via Generative and Geometric Priors
Aug 18, 2024



Reversible face anonymization, unlike traditional face pixelization, seeks to replace sensitive identity information in facial images with synthesized alternatives, preserving privacy without sacrificing image clarity. Traditional methods, such as encoder-decoder networks, often result in significant loss of facial details due to their limited learning capacity. Additionally, relying on latent manipulation in pre-trained GANs can lead to changes in ID-irrelevant attributes, adversely affecting data utility due to GAN inversion inaccuracies. This paper introduces G\textsuperscript{2}Face, which leverages both generative and geometric priors to enhance identity manipulation, achieving high-quality reversible face anonymization without compromising data utility. We utilize a 3D face model to extract geometric information from the input face, integrating it with a pre-trained GAN-based decoder. This synergy of generative and geometric priors allows the decoder to produce realistic anonymized faces with consistent geometry. Moreover, multi-scale facial features are extracted from the original face and combined with the decoder using our novel identity-aware feature fusion blocks (IFF). This integration enables precise blending of the generated facial patterns with the original ID-irrelevant features, resulting in accurate identity manipulation. Extensive experiments demonstrate that our method outperforms existing state-of-the-art techniques in face anonymization and recovery, while preserving high data utility. Code is available at https://github.com/Harxis/G2Face.
Decoupling Feature Representations of Ego and Other Modalities for Incomplete Multi-modal Brain Tumor Segmentation
Aug 16, 2024



Multi-modal brain tumor segmentation typically involves four magnetic resonance imaging (MRI) modalities, while incomplete modalities significantly degrade performance. Existing solutions employ explicit or implicit modality adaptation, aligning features across modalities or learning a fused feature robust to modality incompleteness. They share a common goal of encouraging each modality to express both itself and the others. However, the two expression abilities are entangled as a whole in a seamless feature space, resulting in prohibitive learning burdens. In this paper, we propose DeMoSeg to enhance the modality adaptation by Decoupling the task of representing the ego and other Modalities for robust incomplete multi-modal Segmentation. The decoupling is super lightweight by simply using two convolutions to map each modality onto four feature sub-spaces. The first sub-space expresses itself (Self-feature), while the remaining sub-spaces substitute for other modalities (Mutual-features). The Self- and Mutual-features interactively guide each other through a carefully-designed Channel-wised Sparse Self-Attention (CSSA). After that, a Radiologist-mimic Cross-modality expression Relationships (RCR) is introduced to have available modalities provide Self-feature and also `lend' their Mutual-features to compensate for the absent ones by exploiting the clinical prior knowledge. The benchmark results on BraTS2020, BraTS2018 and BraTS2015 verify the DeMoSeg's superiority thanks to the alleviated modality adaptation difficulty. Concretely, for BraTS2020, DeMoSeg increases Dice by at least 0.92%, 2.95% and 4.95% on whole tumor, tumor core and enhanced tumor regions, respectively, compared to other state-of-the-arts. Codes are at https://github.com/kk42yy/DeMoSeg
FM-OSD: Foundation Model-Enabled One-Shot Detection of Anatomical Landmarks
Jul 07, 2024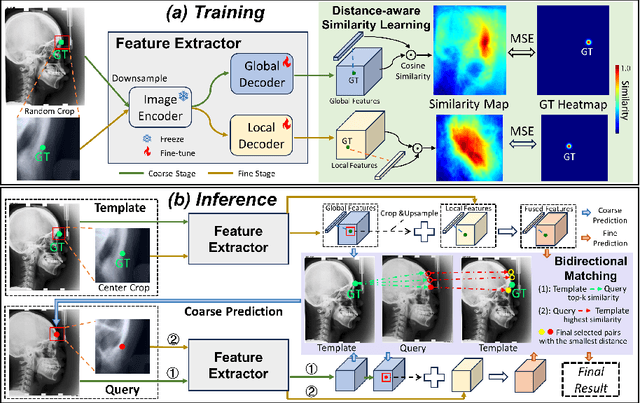


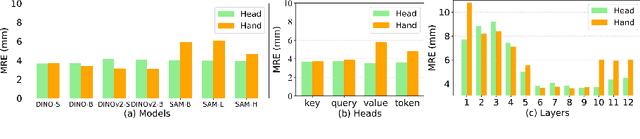
One-shot detection of anatomical landmarks is gaining significant attention for its efficiency in using minimal labeled data to produce promising results. However, the success of current methods heavily relies on the employment of extensive unlabeled data to pre-train an effective feature extractor, which limits their applicability in scenarios where a substantial amount of unlabeled data is unavailable. In this paper, we propose the first foundation model-enabled one-shot landmark detection (FM-OSD) framework for accurate landmark detection in medical images by utilizing solely a single template image without any additional unlabeled data. Specifically, we use the frozen image encoder of visual foundation models as the feature extractor, and introduce dual-branch global and local feature decoders to increase the resolution of extracted features in a coarse to fine manner. The introduced feature decoders are efficiently trained with a distance-aware similarity learning loss to incorporate domain knowledge from the single template image. Moreover, a novel bidirectional matching strategy is developed to improve both robustness and accuracy of landmark detection in the case of scattered similarity map obtained by foundation models. We validate our method on two public anatomical landmark detection datasets. By using solely a single template image, our method demonstrates significant superiority over strong state-of-the-art one-shot landmark detection methods.
Cross Prompting Consistency with Segment Anything Model for Semi-supervised Medical Image Segmentation
Jul 07, 2024



Semi-supervised learning (SSL) has achieved notable progress in medical image segmentation. To achieve effective SSL, a model needs to be able to efficiently learn from limited labeled data and effectively exploiting knowledge from abundant unlabeled data. Recent developments in visual foundation models, such as the Segment Anything Model (SAM), have demonstrated remarkable adaptability with improved sample efficiency. To harness the power of foundation models for application in SSL, we propose a cross prompting consistency method with segment anything model (CPC-SAM) for semi-supervised medical image segmentation. Our method employs SAM's unique prompt design and innovates a cross-prompting strategy within a dual-branch framework to automatically generate prompts and supervisions across two decoder branches, enabling effectively learning from both scarce labeled and valuable unlabeled data. We further design a novel prompt consistency regularization, to reduce the prompt position sensitivity and to enhance the output invariance under different prompts. We validate our method on two medical image segmentation tasks. The extensive experiments with different labeled-data ratios and modalities demonstrate the superiority of our proposed method over the state-of-the-art SSL methods, with more than 9% Dice improvement on the breast cancer segmentation task.
A Review of Image Processing Methods in Prostate Ultrasound
Jun 30, 2024Prostate cancer (PCa) poses a significant threat to men's health, with early diagnosis being crucial for improving prognosis and reducing mortality rates. Transrectal ultrasound (TRUS) plays a vital role in the diagnosis and image-guided intervention of PCa.To facilitate physicians with more accurate and efficient computer-assisted diagnosis and interventions, many image processing algorithms in TRUS have been proposed and achieved state-of-the-art performance in several tasks, including prostate gland segmentation, prostate image registration, PCa classification and detection, and interventional needle detection.The rapid development of these algorithms over the past two decades necessitates a comprehensive summary. In consequence, this survey provides a systematic analysis of this field, outlining the evolution of image processing methods in the context of TRUS image analysis and meanwhile highlighting their relevant contributions. Furthermore, this survey discusses current challenges and suggests future research directions to possibly advance this field further.
Comprehensive Generative Replay for Task-Incremental Segmentation with Concurrent Appearance and Semantic Forgetting
Jun 28, 2024Generalist segmentation models are increasingly favored for diverse tasks involving various objects from different image sources. Task-Incremental Learning (TIL) offers a privacy-preserving training paradigm using tasks arriving sequentially, instead of gathering them due to strict data sharing policies. However, the task evolution can span a wide scope that involves shifts in both image appearance and segmentation semantics with intricate correlation, causing concurrent appearance and semantic forgetting. To solve this issue, we propose a Comprehensive Generative Replay (CGR) framework that restores appearance and semantic knowledge by synthesizing image-mask pairs to mimic past task data, which focuses on two aspects: modeling image-mask correspondence and promoting scalability for diverse tasks. Specifically, we introduce a novel Bayesian Joint Diffusion (BJD) model for high-quality synthesis of image-mask pairs with their correspondence explicitly preserved by conditional denoising. Furthermore, we develop a Task-Oriented Adapter (TOA) that recalibrates prompt embeddings to modulate the diffusion model, making the data synthesis compatible with different tasks. Experiments on incremental tasks (cardiac, fundus and prostate segmentation) show its clear advantage for alleviating concurrent appearance and semantic forgetting. Code is available at https://github.com/jingyzhang/CGR.