 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERE: Structural Example Retrieval for Enhancing LLMs in Event Causality Identification
May 05, 2026Event Causality Identification (ECI) requires models to determine whether a given pair of events in a context exhibits a causal relationship. While Large Language Models (LLMs) have demonstrated strong performance across various NLP tasks, their effectiveness in ECI remains limited due to biases in causal reasoning, often leading to overprediction of causal relationships (causal hallucination). To mitigate these issues and enhance LLM performance in ECI, we propose SERE, a structural example retrieval framework that leverages LLMs' few-shot learning capabilities. SERE introduces an innovative retrieval mechanism based on three structural concepts: (i) Conceptual Path Metric, which measures the conceptual relationship between events using edit distance in ConceptNet; (ii) Syntactic Metric, which quantifies structural similarity through tree edit distance on syntactic trees; and (iii) Causal Pattern Filtering, which filters examples based on predefined causal structures using LLMs. By integrating these structural retrieval strategies, SERE selects more relevant examples to guide LLMs in causal reasoning, mitigating bias and improving accuracy in ECI tasks. Extensive experiments on multiple ECI datasets validate the effectiveness of SERE. The source code is publicly available at https://github.com/DMIRLAB-Group/SERE.
Rethinking Zero-Shot Time Series Classification: From Task-specific Classifiers to In-Context Inference
Jan 31, 2026The zero-shot evaluation of time series foundation models (TSFMs) for classification typically uses a frozen encoder followed by a task-specific classifier. However, this practice violates the training-free premise of zero-shot deployment and introduces evaluation bias due to classifier-dependent training choices. To address this issue, we propose TIC-FM, an in-context learning framework that treats the labeled training set as context and predicts labels for all test instances in a single forward pass, without parameter updates. TIC-FM pairs a time series encoder and a lightweight projection adapter with a split-masked latent memory Transformer. We further provide theoretical justification that in-context inference can subsume trained classifiers and can emulate gradient-based classifier training within a single forward pass. Experiments on 128 UCR datasets show strong accuracy, with consistent gains in the extreme low-label situation, highlighting training-free transfer
Causal-aware Large Language Models: Enhancing Decision-Making Through Learning, Adapting and Acting
May 30, 2025Large language models (LLMs) have shown great potential in decision-making due to the vast amount of knowledge stored within the models. However, these pre-trained models are prone to lack reasoning abilities and are difficult to adapt to new environments, further hindering their application to complex real-world tasks. To address these challenges, inspired by the human cognitive process, we propose Causal-aware LLMs, which integrate the structural causal model (SCM) into the decision-making process to model, update, and utilize structured knowledge of the environment in a ``learning-adapting-acting" paradigm. Specifically, in the learning stage, we first utilize an LLM to extract the environment-specific causal entities and their causal relations to initialize a structured causal model of the environment. Subsequently,in the adapting stage, we update the structured causal model through external feedback about the environment, via an idea of causal intervention. Finally, in the acting stage, Causal-aware LLMs exploit structured causal knowledge for more efficient policy-making through the reinforcement learning agent. The above processes are performed iteratively to learn causal knowledge, ultimately enabling the causal-aware LLMs to achieve a more accurate understanding of the environment and make more efficient decisions. Experimental results across 22 diverse tasks within the open-world game ``Crafter" validate the effectiveness of our proposed method.
An Identifiable Cost-Aware Causal Decision-Making Framework Using Counterfactual Reasoning
May 13, 2025



Decision making under abnormal conditions is a critical process that involves evaluating the current state and determining the optimal action to restore the system to a normal state at an acceptable cost. However, in such scenarios, existing decision-making frameworks highly rely on reinforcement learning or root cause analysis, resulting in them frequently neglecting the cost of the actions or failing to incorporate causal mechanisms adequately. By relaxing the existing causal decision framework to solve the necessary cause, we propose a minimum-cost causal decision (MiCCD) framework via counterfactual reasoning to address the above challenges. Emphasis is placed on making counterfactual reasoning processes identifiable in the presence of a large amount of mixed anomaly data, as well as finding the optimal intervention state in a continuous decision space. Specifically, it formulates a surrogate model based on causal graphs, using abnormal pattern clustering labels as supervisory signals. This enables the approximation of the structural causal model among the variables and lays a foundation for identifiable counterfactual reasoning. With the causal structure approximated, we then established an optimization model based on counterfactual estimation. The Sequential Least Squares Programming (SLSQP) algorithm is further employed to optimize intervention strategies while taking costs into account. Experimental evaluations on both synthetic and real-world datasets reveal that MiCCD outperforms conventional methods across multiple metrics, including F1-score, cost efficiency, and ranking quality(nDCG@k values), thus validating its efficacy and broad applicability.
Heterophilic Graph Neural Networks Optimization with Causal Message-passing
Nov 21, 2024



In this work, we discover that causal inference provides a promising approach to capture heterophilic message-passing in Graph Neural Network (GNN). By leveraging cause-effect analysis, we can discern heterophilic edges based on asymmetric node dependency. The learned causal structure offers more accurate relationships among nodes. To reduce the computational complexity, we introduce intervention-based causal inference in graph learning. We first simplify causal analysis on graphs by formulating it as a structural learning model and define the optimization problem within the Bayesian scheme. We then present an analysis of decomposing the optimization target into a consistency penalty and a structure modification based on cause-effect relations. We then estimate this target by conditional entropy and present insights into how conditional entropy quantifies the heterophily. Accordingly, we propose CausalMP, a causal message-passing discovery network for heterophilic graph learning, that iteratively learns the explicit causal structure of input graphs. We conduct extensive experiments in both heterophilic and homophilic graph settings. The result demonstrates that the our model achieves superior link prediction performance. Training on causal structure can also enhance node representation in classification task across different base models.
Cross Prompting Consistency with Segment Anything Model for Semi-supervised Medical Image Segmentation
Jul 07, 2024



Semi-supervised learning (SSL) has achieved notable progress in medical image segmentation. To achieve effective SSL, a model needs to be able to efficiently learn from limited labeled data and effectively exploiting knowledge from abundant unlabeled data. Recent developments in visual foundation models, such as the Segment Anything Model (SAM), have demonstrated remarkable adaptability with improved sample efficiency. To harness the power of foundation models for application in SSL, we propose a cross prompting consistency method with segment anything model (CPC-SAM) for semi-supervised medical image segmentation. Our method employs SAM's unique prompt design and innovates a cross-prompting strategy within a dual-branch framework to automatically generate prompts and supervisions across two decoder branches, enabling effectively learning from both scarce labeled and valuable unlabeled data. We further design a novel prompt consistency regularization, to reduce the prompt position sensitivity and to enhance the output invariance under different prompts. We validate our method on two medical image segmentation tasks. The extensive experiments with different labeled-data ratios and modalities demonstrate the superiority of our proposed method over the state-of-the-art SSL methods, with more than 9% Dice improvement on the breast cancer segmentation task.
FM-OSD: Foundation Model-Enabled One-Shot Detection of Anatomical Landmarks
Jul 07, 2024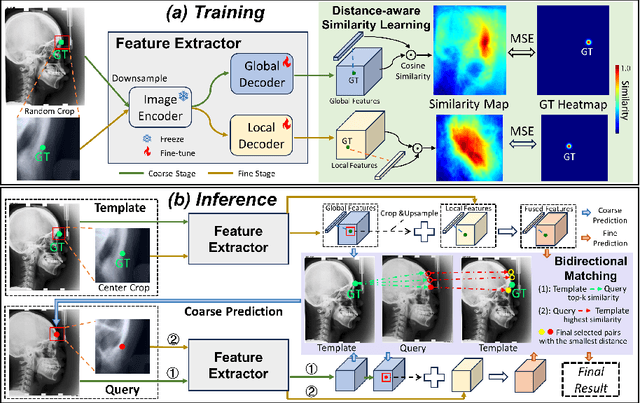


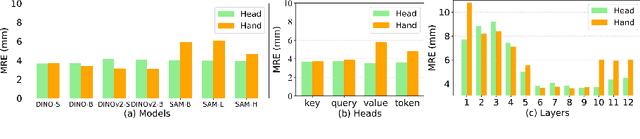
One-shot detection of anatomical landmarks is gaining significant attention for its efficiency in using minimal labeled data to produce promising results. However, the success of current methods heavily relies on the employment of extensive unlabeled data to pre-train an effective feature extractor, which limits their applicability in scenarios where a substantial amount of unlabeled data is unavailable. In this paper, we propose the first foundation model-enabled one-shot landmark detection (FM-OSD) framework for accurate landmark detection in medical images by utilizing solely a single template image without any additional unlabeled data. Specifically, we use the frozen image encoder of visual foundation models as the feature extractor, and introduce dual-branch global and local feature decoders to increase the resolution of extracted features in a coarse to fine manner. The introduced feature decoders are efficiently trained with a distance-aware similarity learning loss to incorporate domain knowledge from the single template image. Moreover, a novel bidirectional matching strategy is developed to improve both robustness and accuracy of landmark detection in the case of scattered similarity map obtained by foundation models. We validate our method on two public anatomical landmark detection datasets. By using solely a single template image, our method demonstrates significant superiority over strong state-of-the-art one-shot landmark detection methods.
Learning by Doing: An Online Causal Reinforcement Learning Framework with Causal-Aware Policy
Feb 07, 2024As a key component to intuitive cognition and reasoning solutions in human intelligence, causal knowledge provides great potential for reinforcement learning (RL) agents' interpretability towards decision-making by helping reduce the searching space. However, there is still a considerable gap in discovering and incorporating causality into RL, which hinders the rapid development of causal RL. In this paper, we consider explicitly modeling the generation process of states with the causal graphical model, based on which we augment the policy. We formulate the causal structure updating into the RL interaction process with active intervention learning of the environment. To optimize the derived objective, we propose a framework with theoretical performance guarantees that alternates between two steps: using interventions for causal structure learning during exploration and using the learned causal structure for policy guidance during exploitation. Due to the lack of public benchmarks that allow direct intervention in the state space, we design the root cause localization task in our simulated fault alarm environment and then empirically show the effectiveness and robustness of the proposed method against state-of-the-art baselines. Theoretical analysis shows that our performance improvement attributes to the virtuous cycle of causal-guided policy learning and causal structure learning, which aligns with our experimental results.
Deep Learning for Multivariate Time Series Imputation: A Survey
Feb 06, 2024The ubiquitous missing values cause the multivariate time series data to be partially observed, destroying the integrity of time series and hindering the effective time series data analysis. Recently deep learning imputation methods have demonstrated remarkable success in elevating the quality of corrupted time series data, subsequently enhancing performance in downstream tasks. In this paper, we conduct a comprehensive survey on the recently proposed deep learning imputation methods. First, we propose a taxonomy for the reviewed methods, and then provide a structured review of these methods by highlighting their strengths and limitations. We also conduct empirical experiments to study different methods and compare their enhancement for downstream tasks. Finally, the open issues for future research on multivariate time series imputation are pointed out. All code and configurations of this work, including a regularly maintained multivariate time series imputation paper list, can be found in the GitHub repository~\url{https://github.com/WenjieDu/Awesome\_Imputation}.
Hierarchical Topological Ordering with Conditional Independence Test for Limited Time Series
Aug 16, 2023



Learning directed acyclic graphs (DAGs) to identify causal relations underlying observational data is crucial but also poses significant challenges. Recently, topology-based methods have emerged as a two-step approach to discovering DAGs by first learning the topological ordering of variables and then eliminating redundant edges, while ensuring that the graph remains acyclic. However, one limitation is that these methods would generate numerous spurious edges that require subsequent pruning. To overcome this limitation, in this paper, we propose an improvement to topology-based methods by introducing limited time series data, consisting of only two cross-sectional records that need not be adjacent in time and are subject to flexible timing. By incorporating conditional instrumental variables as exogenous interventions, we aim to identify descendant nodes for each variable. Following this line, we propose a hierarchical topological ordering algorithm with conditional independence test (HT-CIT), which enables the efficient learning of sparse DAGs with a smaller search space compared to other popular approaches. The HT-CIT algorithm greatly reduces the number of edges that need to be pruned. Empirical results from synthetic and real-world datasets demonstrate the superiority of the proposed HT-CIT algorithm.