 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Autoregressive Diffusion: Global Memory Meets Local Attention
Nov 17, 2025
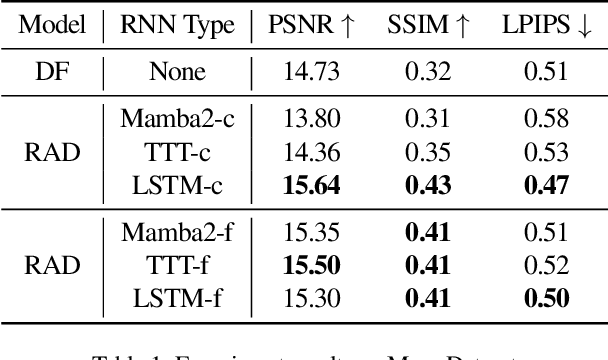

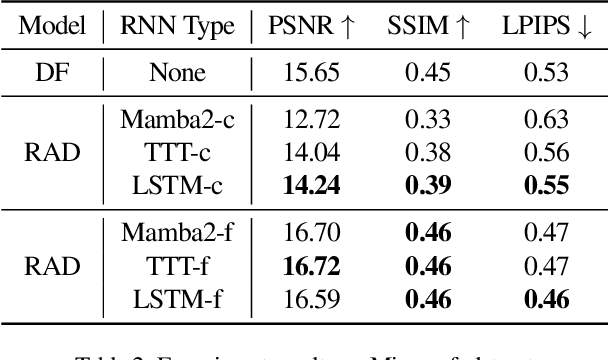
Recent advancements in video generation have demonstrated the potential of using video diffusion models as world models, with autoregressive generation of infinitely long videos through masked conditioning. However, such models, usually with local full attention, lack effective memory compression and retrieval for long-term generation beyond the window size, leading to issues of forgetting and spatiotemporal inconsistencies. To enhance the retention of historical information within a fixed memory budget, we introduce a recurrent neural network (RNN) into the diffusion transformer framework. Specifically, a diffusion model incorporating LSTM with attention achieves comparable performance to state-of-the-art RNN blocks, such as TTT and Mamba2. Moreover, existing diffusion-RNN approaches often suffer from performance degradation due to training-inference gap or the lack of overlap across windows. To address these limitations, we propose a novel Recurrent Autoregressive Diffusion (RAD) framework, which executes frame-wise autoregression for memory update and retrieval, consistently across training and inference time. Experiments on Memory Maze and Minecraft datasets demonstrate the superiority of RAD for long video generation, highlighting the efficiency of LSTM in sequence modeling.
Pixel-Space Post-Training of Latent Diffusion Models
Sep 26, 2024



Latent diffusion models (LDMs) have made significant advancements in the field of image generation in recent years. One major advantage of LDMs is their ability to operate in a compressed latent space, allowing for more efficient training and deployment. However, despite these advantages, challenges with LDMs still remain. For example, it has been observed that LDMs often generate high-frequency details and complex compositions imperfectly. We hypothesize that one reason for these flaws is due to the fact that all pre- and post-training of LDMs are done in latent space, which is typically $8 \times 8$ lower spatial-resolution than the output images. To address this issue, we propose adding pixel-space supervision in the post-training process to better preserve high-frequency details. Experimentally, we show that adding a pixel-space objective significantly improves both supervised quality fine-tuning and preference-based post-training by a large margin on a state-of-the-art DiT transformer and U-Net diffusion models in both visual quality and visual flaw metrics, while maintaining the same text alignment quality.
Towards Robust Robot 3D Perception in Urban Environments: The UT Campus Object Dataset
Oct 01, 2023



We introduce the UT Campus Object Dataset (CODa), a mobile robot egocentric perception dataset collected on the University of Texas Austin Campus. Our dataset contains 8.5 hours of multimodal sensor data: synchronized 3D point clouds and stereo RGB video from a 128-channel 3D LiDAR and two 1.25MP RGB cameras at 10 fps; RGB-D videos from an additional 0.5MP sensor at 7 fps, and a 9-DOF IMU sensor at 40 Hz. We provide 58 minutes of ground-truth annotations containing 1.3 million 3D bounding boxes with instance IDs for 53 semantic classes, 5000 frames of 3D semantic annotations for urban terrain, and pseudo-ground truth localization. We repeatedly traverse identical geographic locations for a wide range of indoor and outdoor areas, weather conditions, and times of the day. Using CODa, we empirically demonstrate that: 1) 3D object detection performance in urban settings is significantly higher when trained using CODa compared to existing datasets even when employing state-of-the-art domain adaptation approaches, 2) sensor-specific fine-tuning improves 3D object detection accuracy and 3) pretraining on CODa improves cross-dataset 3D object detection performance in urban settings compared to pretraining on AV datasets. Using our dataset and annotations, we release benchmarks for 3D object detection and 3D semantic segmentation using established metrics. In the future, the CODa benchmark will include additional tasks like unsupervised object discovery and re-identification. We publicly release CODa on the Texas Data Repository, pre-trained models, dataset development package, and interactive dataset viewer on our website at https://amrl.cs.utexas.edu/coda. We expect CODa to be a valuable dataset for research in egocentric 3D perception and planning for autonomous navigation in urban environments.