 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealMaster: Lifting Rendered Scenes into Photorealistic Video
Mar 24, 2026State-of-the-art video generation models produce remarkable photorealism, but they lack the precise control required to align generated content with specific scene requirements. Furthermore, without an underlying explicit geometry, these models cannot guarantee 3D consistency. Conversely, 3D engines offer granular control over every scene element and provide native 3D consistency by design, yet their output often remains trapped in the "uncanny valley". Bridging this sim-to-real gap requires both structural precision, where the output must exactly preserve the geometry and dynamics of the input, and global semantic transformation, where materials, lighting, and textures must be holistically transformed to achieve photorealism. We present RealMaster, a method that leverages video diffusion models to lift rendered video into photorealistic video while maintaining full alignment with the output of the 3D engine. To train this model, we generate a paired dataset via an anchor-based propagation strategy, where the first and last frames are enhanced for realism and propagated across the intermediate frames using geometric conditioning cues. We then train an IC-LoRA on these paired videos to distill the high-quality outputs of the pipeline into a model that generalizes beyond the pipeline's constraints, handling objects and characters that appear mid-sequence and enabling inference without requiring anchor frames. Evaluated on complex GTA-V sequences, RealMaster significantly outperforms existing video editing baselines, improving photorealism while preserving the geometry, dynamics, and identity specified by the original 3D control.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models
Feb 04, 2025



Despite tremendous recent progress, generative video models still struggle to capture real-world motion, dynamics, and physics. We show that this limitation arises from the conventional pixel reconstruction objective, which biases models toward appearance fidelity at the expense of motion coherence. To address this, we introduce VideoJAM, a novel framework that instills an effective motion prior to video generators, by encouraging the model to learn a joint appearance-motion representation. VideoJAM is composed of two complementary units. During training, we extend the objective to predict both the generated pixels and their corresponding motion from a single learned representation. During inference, we introduce Inner-Guidance, a mechanism that steers the generation toward coherent motion by leveraging the model's own evolving motion prediction as a dynamic guidance signal. Notably, our framework can be applied to any video model with minimal adaptations, requiring no modifications to the training data or scaling of the model. VideoJAM achieves state-of-the-art performance in motion coherence, surpassing highly competitive proprietary models while also enhancing the perceived visual quality of the generations. These findings emphasize that appearance and motion can be complementary and, when effectively integrated, enhance both the visual quality and the coherence of video generation. Project website: https://hila-chefer.github.io/videojam-paper.github.io/
Through-The-Mask: Mask-based Motion Trajectories for Image-to-Video Generation
Jan 06, 2025



We consider the task of Image-to-Video (I2V) generation, which involves transforming static images into realistic video sequences based on a textual description. While recent advancements produce photorealistic outputs, they frequently struggle to create videos with accurate and consistent object motion, especially in multi-object scenarios. To address these limitations, we propose a two-stage compositional framework that decomposes I2V generation into: (i) An explicit intermediate representation generation stage, followed by (ii) A video generation stage that is conditioned on this representation. Our key innovation is the introduction of a mask-based motion trajectory as an intermediate representation, that captures both semantic object information and motion, enabling an expressive but compact representation of motion and semantics. To incorporate the learned representation in the second stage, we utilize object-level attention objectives. Specifically, we consider a spatial, per-object, masked-cross attention objective, integrating object-specific prompts into corresponding latent space regions and a masked spatio-temporal self-attention objective, ensuring frame-to-frame consistency for each object. We evaluate our method on challenging benchmarks with multi-object and high-motion scenarios and empirically demonstrate that the proposed method achieves state-of-the-art results in temporal coherence, motion realism, and text-prompt faithfulness. Additionally, we introduce \benchmark, a new challenging benchmark for single-object and multi-object I2V generation, and demonstrate our method's superiority on this benchmark. Project page is available at https://guyyariv.github.io/TTM/.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Video Editing via Factorized Diffusion Distillation
Mar 24, 2024We introduce Emu Video Edit (EVE), a model that establishes a new state-of-the art in video editing without relying on any supervised video editing data. To develop EVE we separately train an image editing adapter and a video generation adapter, and attach both to the same text-to-image model. Then, to align the adapters towards video editing we introduce a new unsupervised distillation procedure, Factorized Diffusion Distillation. This procedure distills knowledge from one or more teachers simultaneously, without any supervised data. We utilize this procedure to teach EVE to edit videos by jointly distilling knowledge to (i) precisely edit each individual frame from the image editing adapter, and (ii) ensure temporal consistency among the edited frames using the video generation adapter. Finally, to demonstrate the potential of our approach in unlocking other capabilities, we align additional combinations of adapters
Emu Edit: Precise Image Editing via Recognition and Generation Tasks
Nov 16, 2023



Instruction-based image editing holds immense potential for a variety of applications, as it enables users to perform any editing operation using a natural language instruction. However, current models in this domain often struggle with accurately executing user instructions. We present Emu Edit, a multi-task image editing model which sets state-of-the-art results in instruction-based image editing. To develop Emu Edit we train it to multi-task across an unprecedented range of tasks, such as region-based editing, free-form editing, and Computer Vision tasks, all of which are formulated as generative tasks. Additionally, to enhance Emu Edit's multi-task learning abilities, we provide it with learned task embeddings which guide the generation process towards the correct edit type. Both these elements are essential for Emu Edit's outstanding performance. Furthermore, we show that Emu Edit can generalize to new tasks, such as image inpainting, super-resolution, and compositions of editing tasks, with just a few labeled examples. This capability offers a significant advantage in scenarios where high-quality samples are scarce. Lastly, to facilitate a more rigorous and informed assessment of instructable image editing models, we release a new challenging and versatile benchmark that includes seven different image editing tasks.
Automatic Program Synthesis of Long Programs with a Learned Garbage Collector
Sep 12, 2018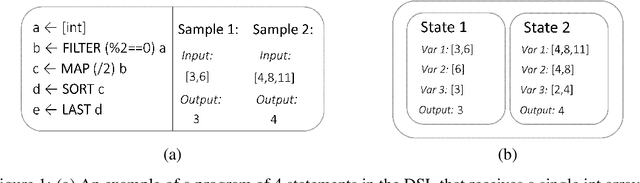
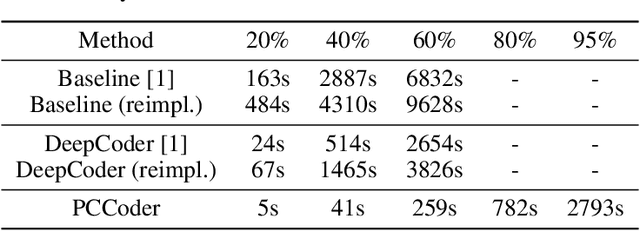
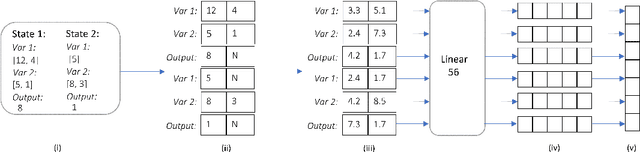
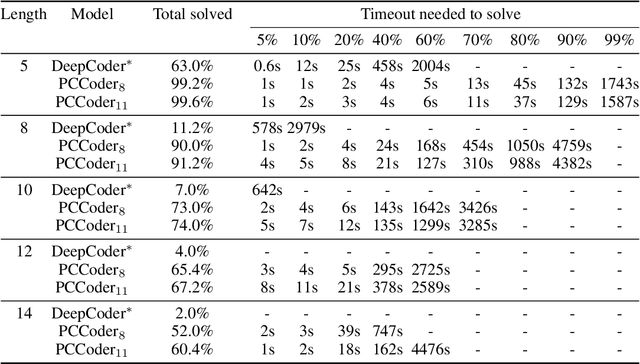
We consider the problem of generating automatic code given sample input-output pairs. We train a neural network to map from the current state and the outputs to the program's next statement. The neural network optimizes multiple tasks concurrently: the next operation out of a set of high level commands, the operands of the next statement, and which variables can be dropped from memory. Using our method we are able to create programs that are more than twice as long as existing state-of-the-art solutions, while improving the success rate for comparable lengths, and cutting the run-time by two orders of magnitude. Our code is publicly available at https://github.com/amitz25/PCCoder