 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution
Jan 21, 2026Large Language Model (LLM)-based agents are widely used in real-world applications such as customer service, web navigation, and software engineering. As these systems become more autonomous and are deployed at scale, understanding why an agent takes a particular action becomes increasingly important for accountability and governance. However, existing research predominantly focuses on \textit{failure attribution} to localize explicit errors in unsuccessful trajectories, which is insufficient for explaining the reasoning behind agent behaviors. To bridge this gap, we propose a novel framework for \textbf{general agentic attribution}, designed to identify the internal factors driving agent actions regardless of the task outcome. Our framework operates hierarchically to manage the complexity of agent interactions. Specifically, at the \textit{component level}, we employ temporal likelihood dynamics to identify critical interaction steps; then at the \textit{sentence level}, we refine this localization using perturbation-based analysis to isolate the specific textual evidence. We validate our framework across a diverse suite of agentic scenarios, including standard tool use and subtle reliability risks like memory-induced bias. Experimental results demonstrate that the proposed framework reliably pinpoints pivotal historical events and sentences behind the agent behavior, offering a critical step toward safer and more accountable agentic systems.
Ability Transfer and Recovery via Modularized Parameters Localization
Jan 14, 2026Large language models can be continually pre-trained or fine-tuned to improve performance in specific domains, languages, or skills, but this specialization often degrades other capabilities and may cause catastrophic forgetting. We investigate how abilities are distributed within LLM parameters by analyzing module activations under domain- and language-specific inputs for closely related models. Across layers and modules, we find that ability-related activations are highly concentrated in a small set of channels (typically <5\%), and these channels are largely disentangled with good sufficiency and stability. Building on these observations, we propose ACT (Activation-Guided Channel-wise Ability Transfer), which localizes ability-relevant channels via activation differences and selectively transfers only the corresponding parameters, followed by lightweight fine-tuning for compatibility. Experiments on multilingual mathematical and scientific reasoning show that ACT can recover forgotten abilities while preserving retained skills. It can also merge multiple specialized models to integrate several abilities into a single model with minimal interference. Our code and data will be publicly released.
PDR: A Plug-and-Play Positional Decay Framework for LLM Pre-training Data Detection
Jan 11, 2026Detecting pre-training data in Large Language Models (LLMs) is crucial for auditing data privacy and copyright compliance, yet it remains challenging in black-box, zero-shot settings where computational resources and training data are scarce. While existing likelihood-based methods have shown promise, they typically aggregate token-level scores using uniform weights, thereby neglecting the inherent information-theoretic dynamics of autoregressive generation. In this paper, we hypothesize and empirically validate that memorization signals are heavily skewed towards the high-entropy initial tokens, where model uncertainty is highest, and decay as context accumulates. To leverage this linguistic property, we introduce Positional Decay Reweighting (PDR), a training-free and plug-and-play framework. PDR explicitly reweights token-level scores to amplify distinct signals from early positions while suppressing noise from later ones. Extensive experiments show that PDR acts as a robust prior and can usually enhance a wide range of advanced methods across multiple benchmarks.
Can Large Language Models Resolve Semantic Discrepancy in Self-Destructive Subcultures? Evidence from Jirai Kei
Jan 08, 2026Self-destructive behaviors are linked to complex psychological states and can be challenging to diagnose. These behaviors may be even harder to identify within subcultural groups due to their unique expressions. As large language models (LLMs) are applied across various fields, some researchers have begun exploring their application for detecting self-destructive behaviors. Motivated by this, we investigate self-destructive behavior detection within subcultures using current LLM-based methods. However, these methods have two main challenges: (1) Knowledge Lag: Subcultural slang evolves rapidly, faster than LLMs' training cycles; and (2) Semantic Misalignment: it is challenging to grasp the specific and nuanced expressions unique to subcultures. To address these issues, we proposed Subcultural Alignment Solver (SAS), a multi-agent framework that incorporates automatic retrieval and subculture alignment, significantly enhancing the performance of LLMs in detecting self-destructive behavior. Our experimental results show that SAS outperforms the current advanced multi-agent framework OWL. Notably, it competes well with fine-tuned LLMs. We hope that SAS will advance the field of self-destructive behavior detection in subcultural contexts and serve as a valuable resource for future researchers.
UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
Dec 12, 2025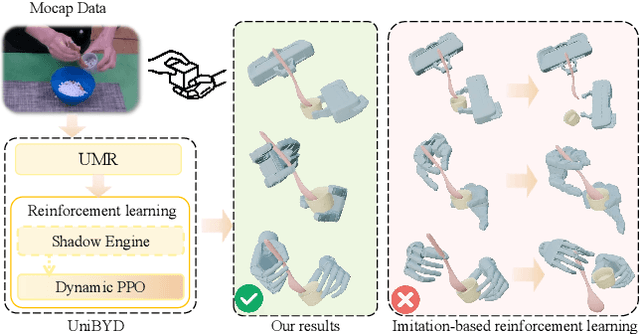
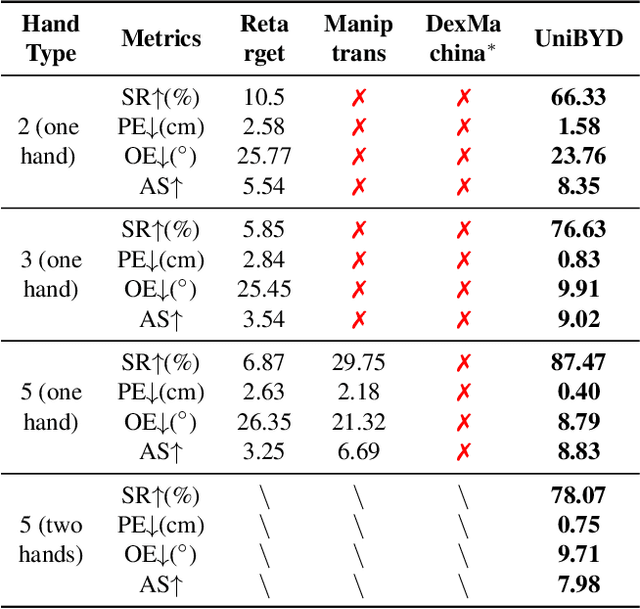
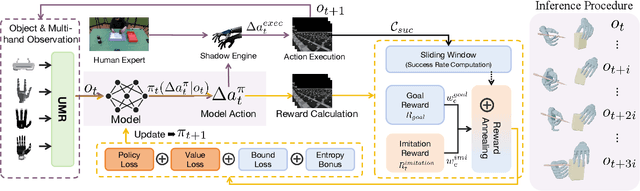
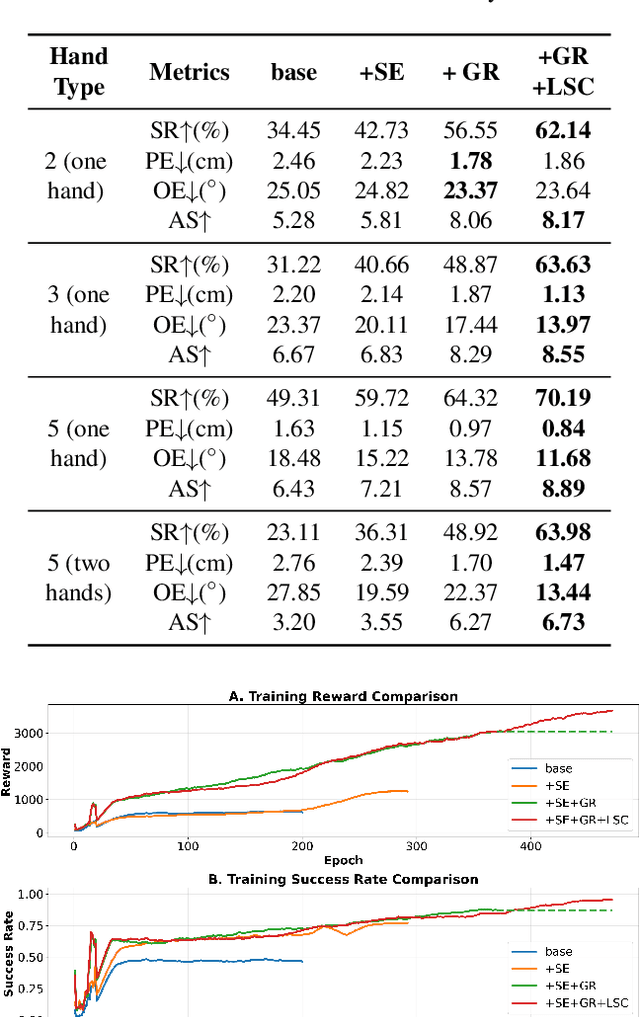
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.
Long-LRM++: Preserving Fine Details in Feed-Forward Wide-Coverage Reconstruction
Dec 11, 2025



Recent advances in generalizable Gaussian splatting (GS) have enabled feed-forward reconstruction of scenes from tens of input views. Long-LRM notably scales this paradigm to 32 input images at $950\times540$ resolution, achieving 360° scene-level reconstruction in a single forward pass. However, directly predicting millions of Gaussian parameters at once remains highly error-sensitive: small inaccuracies in positions or other attributes lead to noticeable blurring, particularly in fine structures such as text. In parallel, implicit representation methods such as LVSM and LaCT have demonstrated significantly higher rendering fidelity by compressing scene information into model weights rather than explicit Gaussians, and decoding RGB frames using the full transformer or TTT backbone. However, this computationally intensive decompression process for every rendered frame makes real-time rendering infeasible. These observations raise key questions: Is the deep, sequential "decompression" process necessary? Can we retain the benefits of implicit representations while enabling real-time performance? We address these questions with Long-LRM++, a model that adopts a semi-explicit scene representation combined with a lightweight decoder. Long-LRM++ matches the rendering quality of LaCT on DL3DV while achieving real-time 14 FPS rendering on an A100 GPU, overcoming the speed limitations of prior implicit methods. Our design also scales to 64 input views at the $950\times540$ resolution, demonstrating strong generalization to increased input lengths. Additionally, Long-LRM++ delivers superior novel-view depth prediction on ScanNetv2 compared to direct depth rendering from Gaussians. Extensive ablation studies validate the effectiveness of each component in the proposed framework.
Imagine in Space: Exploring the Frontier of Spatial Intelligence and Reasoning Efficiency in Vision Language Models
Nov 16, 2025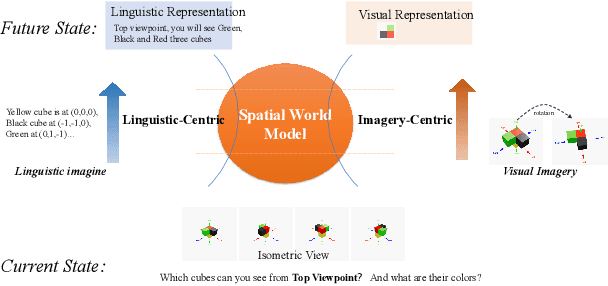
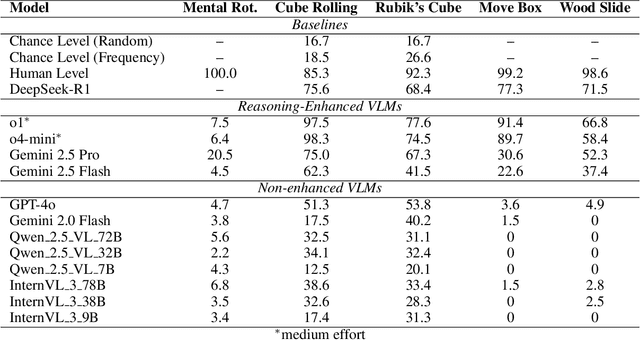
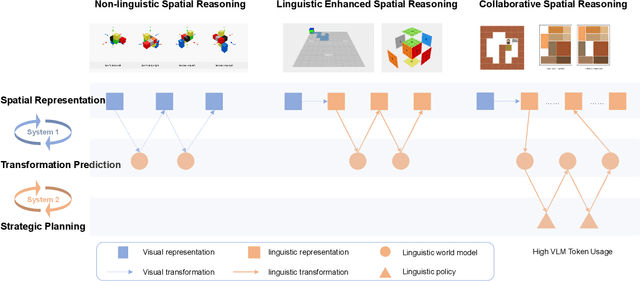

Large language models (LLMs) and vision language models (VLMs), such as DeepSeek R1,OpenAI o3, and Gemini 2.5 Pro, have demonstrated remarkable reasoning capabilities across logical inference, problem solving, and decision making. However, spatial reasoning:a fundamental component of human cognition that includes mental rotation, navigation, and spatial relationship comprehension remains a significant challenge for current advanced VLMs. We hypothesize that imagination, the internal simulation of spatial states, is the dominant reasoning mechanism within a spatial world model. To test this hypothesis and systematically probe current VLM spatial reasoning mechanisms, we introduce SpatiaLite, a fully synthetic benchmark that jointly measures spatial reasoning accuracy and reasoning efficiency. Comprehensive experiments reveal three key findings. First, advanced VLMs predominantly rely on linguistic representations for reasoning and imagination, resulting in significant deficiencies on visual centric tasks that demand perceptual spatial relations and 3D geometry transformations such as mental rotation or projection prediction. Second, advanced VLMs exhibit severe inefficiency in their current spatial reasoning mechanisms, with token usage growing rapidly as transformation complexity increases. Third, we propose an Imagery Driven Framework (IDF) for data synthesis and training, which can implicitly construct an internal world model that is critical for spatial reasoning in VLMs. Building on SpatiaLite, this work delineates the spatial reasoning limits and patterns of advanced VLMs, identifies key shortcomings, and informs future advances
ScaleADFG: Affordance-based Dexterous Functional Grasping via Scalable Dataset
Nov 12, 2025Dexterous functional tool-use grasping is essential for effective robotic manipulation of tools. However, existing approaches face significant challenges in efficiently constructing large-scale datasets and ensuring generalizability to everyday object scales. These issues primarily arise from size mismatches between robotic and human hands, and the diversity in real-world object scales. To address these limitations, we propose the ScaleADFG framework, which consists of a fully automated dataset construction pipeline and a lightweight grasp generation network. Our dataset introduce an affordance-based algorithm to synthesize diverse tool-use grasp configurations without expert demonstrations, allowing flexible object-hand size ratios and enabling large robotic hands (compared to human hands) to grasp everyday objects effectively. Additionally, we leverage pre-trained models to generate extensive 3D assets and facilitate efficient retrieval of object affordances. Our dataset comprising five object categories, each containing over 1,000 unique shapes with 15 scale variations. After filtering, the dataset includes over 60,000 grasps for each 2 dexterous robotic hands. On top of this dataset, we train a lightweight, single-stage grasp generation network with a notably simple loss design, eliminating the need for post-refinement. This demonstrates the critical importance of large-scale datasets and multi-scale object variant for effective training. Extensive experiments in simulation and on real robot confirm that the ScaleADFG framework exhibits strong adaptability to objects of varying scales, enhancing functional grasp stability, diversity, and generalizability. Moreover, our network exhibits effective zero-shot transfer to real-world objects. Project page is available at https://sizhe-wang.github.io/ScaleADFG_webpage
From Structure to Detail: Hierarchical Distillation for Efficient Diffusion Model
Nov 12, 2025The inference latency of diffusion models remains a critical barrier to their real-time application. While trajectory-based and distribution-based step distillation methods offer solutions, they present a fundamental trade-off. Trajectory-based methods preserve global structure but act as a "lossy compressor", sacrificing high-frequency details. Conversely, distribution-based methods can achieve higher fidelity but often suffer from mode collapse and unstable training. This paper recasts them from independent paradigms into synergistic components within our novel Hierarchical Distillation (HD) framework. We leverage trajectory distillation not as a final generator, but to establish a structural ``sketch", providing a near-optimal initialization for the subsequent distribution-based refinement stage. This strategy yields an ideal initial distribution that enhances the ceiling of overall performance. To further improve quality, we introduce and refine the adversarial training process. We find standard discriminator structures are ineffective at refining an already high-quality generator. To overcome this, we introduce the Adaptive Weighted Discriminator (AWD), tailored for the HD pipeline. By dynamically allocating token weights, AWD focuses on local imperfections, enabling efficient detail refinement. Our approach demonstrates state-of-the-art performance across diverse tasks. On ImageNet $256\times256$, our single-step model achieves an FID of 2.26, rivaling its 250-step teacher. It also achieves promising results on the high-resolution text-to-image MJHQ benchmark, proving its generalizability. Our method establishes a robust new paradigm for high-fidelity, single-step diffusion models.
Multi-period Learning for Financial Time Series Forecasting
Nov 07, 2025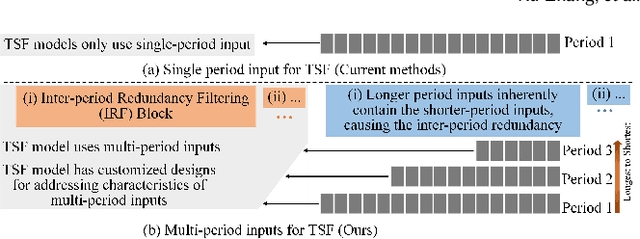
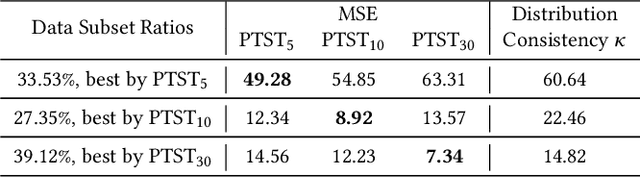
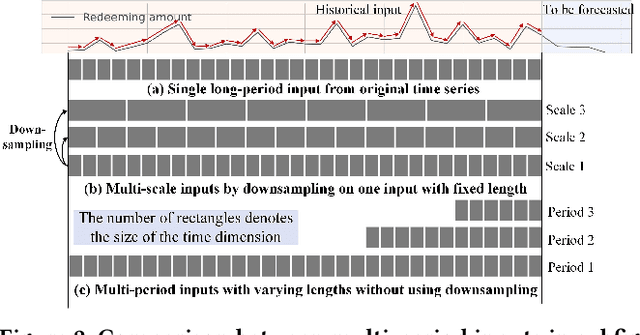
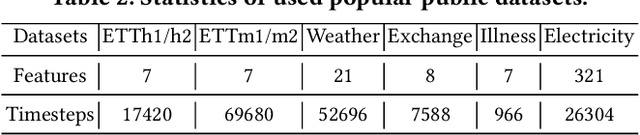
Time series forecasting is important in finance domain. Financial time series (TS) patterns are influenced by both short-term public opinions and medium-/long-term policy and market trends. Hence, processing multi-period inputs becomes crucial for accurate financial time series forecasting (TSF). However, current TSF models either use only single-period input, or lack customized designs for addressing multi-period characteristics. In this paper, we propose a Multi-period Learning Framework (MLF) to enhance financial TSF performance. MLF considers both TSF's accuracy and efficiency requirements. Specifically, we design three new modules to better integrate the multi-period inputs for improving accuracy: (i) Inter-period Redundancy Filtering (IRF), that removes the information redundancy between periods for accurate self-attention modeling, (ii) Learnable Weighted-average Integration (LWI), that effectively integrates multi-period forecasts, (iii) Multi-period self-Adaptive Patching (MAP), that mitigates the bias towards certain periods by setting the same number of patches across all periods. Furthermore, we propose a Patch Squeeze module to reduce the number of patches in self-attention modeling for maximized efficiency. MLF incorporates multiple inputs with varying lengths (periods) to achieve better accuracy and reduces the costs of selecting input lengths during training. The codes and datasets are available at https://github.com/Meteor-Stars/MLF.