 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-LRM++: Preserving Fine Details in Feed-Forward Wide-Coverage Reconstruction
Dec 11, 2025



Recent advances in generalizable Gaussian splatting (GS) have enabled feed-forward reconstruction of scenes from tens of input views. Long-LRM notably scales this paradigm to 32 input images at $950\times540$ resolution, achieving 360° scene-level reconstruction in a single forward pass. However, directly predicting millions of Gaussian parameters at once remains highly error-sensitive: small inaccuracies in positions or other attributes lead to noticeable blurring, particularly in fine structures such as text. In parallel, implicit representation methods such as LVSM and LaCT have demonstrated significantly higher rendering fidelity by compressing scene information into model weights rather than explicit Gaussians, and decoding RGB frames using the full transformer or TTT backbone. However, this computationally intensive decompression process for every rendered frame makes real-time rendering infeasible. These observations raise key questions: Is the deep, sequential "decompression" process necessary? Can we retain the benefits of implicit representations while enabling real-time performance? We address these questions with Long-LRM++, a model that adopts a semi-explicit scene representation combined with a lightweight decoder. Long-LRM++ matches the rendering quality of LaCT on DL3DV while achieving real-time 14 FPS rendering on an A100 GPU, overcoming the speed limitations of prior implicit methods. Our design also scales to 64 input views at the $950\times540$ resolution, demonstrating strong generalization to increased input lengths. Additionally, Long-LRM++ delivers superior novel-view depth prediction on ScanNetv2 compared to direct depth rendering from Gaussians. Extensive ablation studies validate the effectiveness of each component in the proposed framework.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
GS4: Generalizable Sparse Splatting Semantic SLAM
Jun 06, 2025Traditional SLAM algorithms are excellent at camera tracking but might generate lower resolution and incomplete 3D maps. Recently, Gaussian Splatting (GS) approaches have emerged as an option for SLAM with accurate, dense 3D map building. However, existing GS-based SLAM methods rely on per-scene optimization which is time-consuming and does not generalize to diverse scenes well. In this work, we introduce the first generalizable GS-based semantic SLAM algorithm that incrementally builds and updates a 3D scene representation from an RGB-D video stream using a learned generalizable network. Our approach starts from an RGB-D image recognition backbone to predict the Gaussian parameters from every downsampled and backprojected image location. Additionally, we seamlessly integrate 3D semantic segmentation into our GS framework, bridging 3D mapping and recognition through a shared backbone. To correct localization drifting and floaters, we propose to optimize the GS for only 1 iteration following global localization. We demonstrate state-of-the-art semantic SLAM performance on the real-world benchmark ScanNet with an order of magnitude fewer Gaussians compared to other recent GS-based methods, and showcase our model's generalization capability through zero-shot transfer to the NYUv2 and TUM RGB-D datasets.
WorldPrompter: Traversable Text-to-Scene Generation
Apr 02, 2025



Scene-level 3D generation is a challenging research topic, with most existing methods generating only partial scenes and offering limited navigational freedom. We introduce WorldPrompter, a novel generative pipeline for synthesizing traversable 3D scenes from text prompts. We leverage panoramic videos as an intermediate representation to model the 360{\deg} details of a scene. WorldPrompter incorporates a conditional 360{\deg} panoramic video generator, capable of producing a 128-frame video that simulates a person walking through and capturing a virtual environment. The resulting video is then reconstructed as Gaussian splats by a fast feedforward 3D reconstructor, enabling a true walkable experience within the 3D scene. Experiments demonstrate that our panoramic video generation model achieves convincing view consistency across frames, enabling high-quality panoramic Gaussian splat reconstruction and facilitating traversal over an area of the scene. Qualitative and quantitative results also show it outperforms the state-of-the-art 360{\deg} video generators and 3D scene generation models.
PointRecon: Online Point-based 3D Reconstruction via Ray-based 2D-3D Matching
Oct 30, 2024We propose a novel online, point-based 3D reconstruction method from posed monocular RGB videos. Our model maintains a global point cloud representation of the scene, continuously updating the features and 3D locations of points as new images are observed. It expands the point cloud with newly detected points while carefully removing redundancies. The point cloud updates and depth predictions for new points are achieved through a novel ray-based 2D-3D feature matching technique, which is robust against errors in previous point position predictions. In contrast to offline methods, our approach processes infinite-length sequences and provides real-time updates. Additionally, the point cloud imposes no pre-defined resolution or scene size constraints, and its unified global representation ensures view consistency across perspectives. Experiments on the ScanNet dataset show that our method achieves state-of-the-art quality among online MVS approaches. Project page: https://arthurhero.github.io/projects/pointrecon
Long-LRM: Long-sequence Large Reconstruction Model for Wide-coverage Gaussian Splats
Oct 16, 2024



We propose Long-LRM, a generalizable 3D Gaussian reconstruction model that is capable of reconstructing a large scene from a long sequence of input images. Specifically, our model can process 32 source images at 960x540 resolution within only 1.3 seconds on a single A100 80G GPU. Our architecture features a mixture of the recent Mamba2 blocks and the classical transformer blocks which allowed many more tokens to be processed than prior work, enhanced by efficient token merging and Gaussian pruning steps that balance between quality and efficiency. Unlike previous feed-forward models that are limited to processing 1~4 input images and can only reconstruct a small portion of a large scene, Long-LRM reconstructs the entire scene in a single feed-forward step. On large-scale scene datasets such as DL3DV-140 and Tanks and Temples, our method achieves performance comparable to optimization-based approaches while being two orders of magnitude more efficient. Project page: https://arthurhero.github.io/projects/llrm
AutoFocusFormer: Image Segmentation off the Grid
Apr 24, 2023Real world images often have highly imbalanced content density. Some areas are very uniform, e.g., large patches of blue sky, while other areas are scattered with many small objects. Yet, the commonly used successive grid downsampling strategy in convolutional deep networks treats all areas equally. Hence, small objects are represented in very few spatial locations, leading to worse results in tasks such as segmentation. Intuitively, retaining more pixels representing small objects during downsampling helps to preserve important information. To achieve this, we propose AutoFocusFormer (AFF), a local-attention transformer image recognition backbone, which performs adaptive downsampling by learning to retain the most important pixels for the task. Since adaptive downsampling generates a set of pixels irregularly distributed on the image plane, we abandon the classic grid structure. Instead, we develop a novel point-based local attention block, facilitated by a balanced clustering module and a learnable neighborhood merging module, which yields representations for our point-based versions of state-of-the-art segmentation heads. Experiments show that our AutoFocusFormer (AFF) improves significantly over baseline models of similar sizes.
Improved Point Transformation Methods For Self-Supervised Depth Prediction
Feb 18, 2021
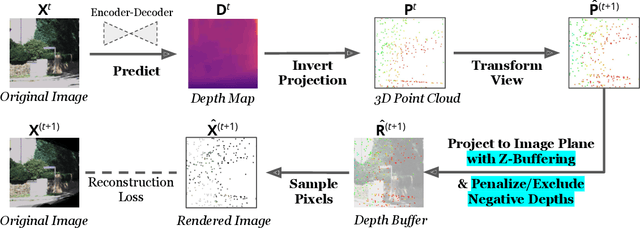
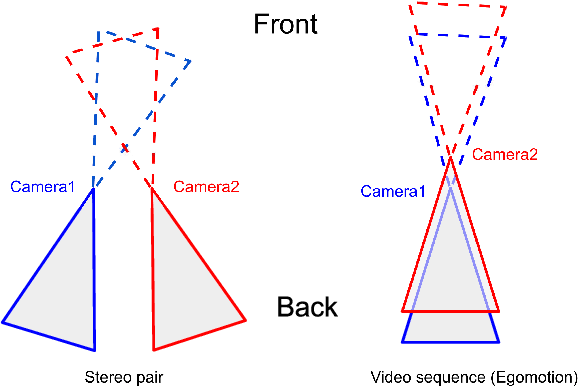
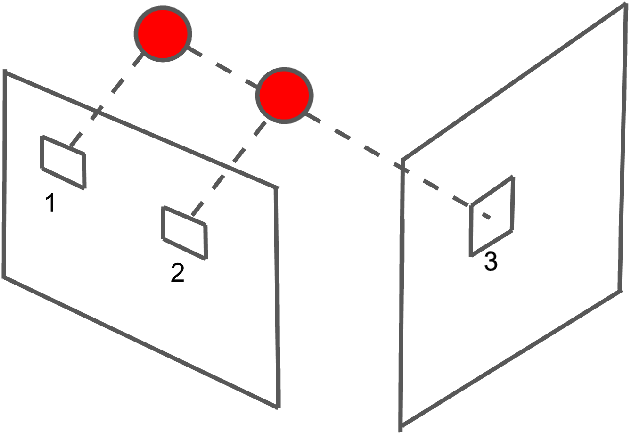
Given stereo or egomotion image pairs, a popular and successful method for unsupervised learning of monocular depth estimation is to measure the quality of image reconstructions resulting from the learned depth predictions. Continued research has improved the overall approach in recent years, yet the common framework still suffers from several important limitations, particularly when dealing with points occluded after transformation to a novel viewpoint. While prior work has addressed this problem heuristically, this paper introduces a z-buffering algorithm that correctly and efficiently handles occluded points. Because our algorithm is implemented with operators typical of machine learning libraries, it can be incorporated into any existing unsupervised depth learning framework with automatic support for differentiation. Additionally, because points having negative depth after transformation often signify erroneously shallow depth predictions, we introduce a loss function to penalize this undesirable behavior explicitly. Experimental results on the KITTI data set show that the z-buffer and negative depth loss both improve the performance of a state of the art depth-prediction network.
Visualizing Point Cloud Classifiers by Curvature Smoothing
Nov 27, 2019
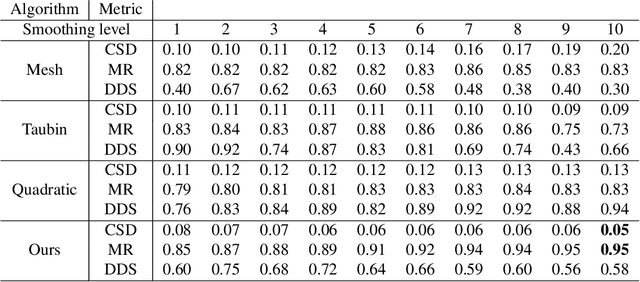

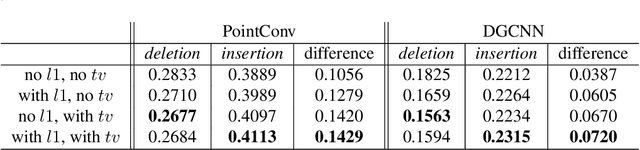
Recently, several networks that operate directly on point clouds have been proposed. There is significant utility in understanding them better, so that humans can understand more about the mechanisms how those networks classify point clouds, potentially helping diagnosing them and designing better architectures and data augmentation pipelines. In this paper, we propose a novel approach to visualize important features used in classification decisions of point cloud networks. Following ideas in visualizing 2-D convolutional networks, our approach is based on gradually smoothing parts of the point cloud. However, different from the 2-D case, we smooth the curvature of the point cloud to remove sharp shape features. The resulting point cloud is then evaluated on the original point cloud network to see whether the performance has dropped or remained the same, from which parts that are important to the point cloud classification are identified. A technical contribution of the paper is an approximated curvature smoothing algorithm, which can smoothly transition from the original point cloud to one of constant curvature, such as a uniform sphere. With this smoothing algorithm, we propose PCI-GOS, a 3-D extension of the Integrated-Gradients Optimized Saliency (I-GOS) algorithm, as a perturbation-based visualization technique realized on 3-D shapes. Experiment results revealed insights into these classifiers.