 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Agnostic Multilingual Information Retrieval with Contrastive Learning
Oct 12, 2022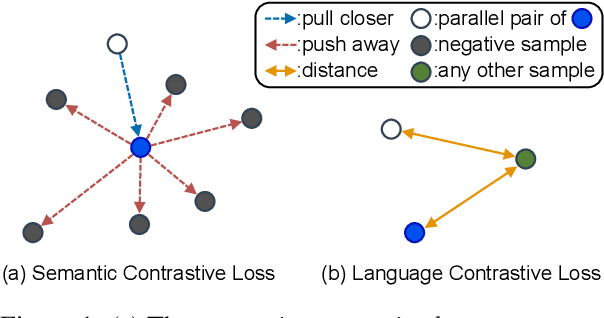
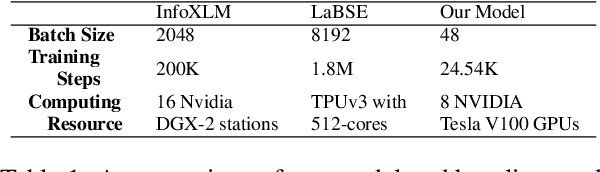
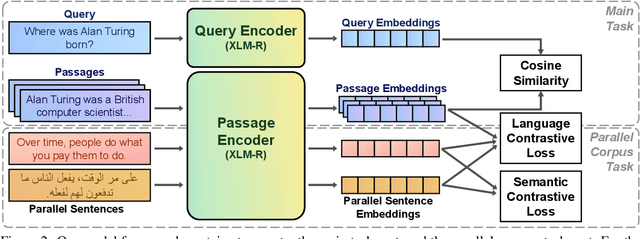
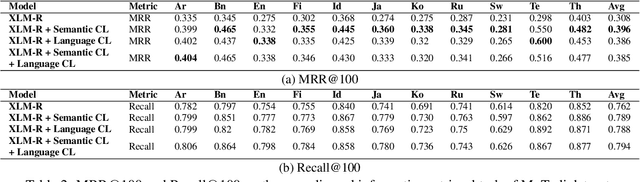
Multilingual information retrieval is challenging due to the lack of training datasets for many low-resource languages. We present an effective method by leveraging parallel and non-parallel corpora to improve the pretrained multilingual language models' cross-lingual transfer ability for information retrieval. We design the semantic contrastive loss as regular contrastive learning to improve the cross-lingual alignment of parallel sentence pairs, and we propose a new contrastive loss, the language contrastive loss, to leverage both parallel corpora and non-parallel corpora to further improve multilingual representation learning. We train our model on an English information retrieval dataset, and test its zero-shot transfer ability to other languages. Our experiment results show that our method brings significant improvement to prior work on retrieval performance, while it requires much less computational effort. Our model can work well even with a small number of parallel corpora. And it can be used as an add-on module to any backbone and other tasks. Our code is available at: https://github.com/xiyanghu/multilingualIR.
SpanDrop: Simple and Effective Counterfactual Learning for Long Sequences
Aug 03, 2022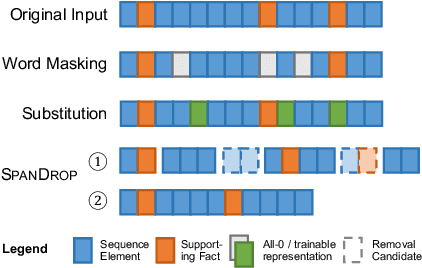
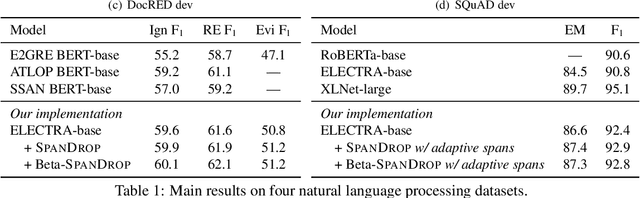
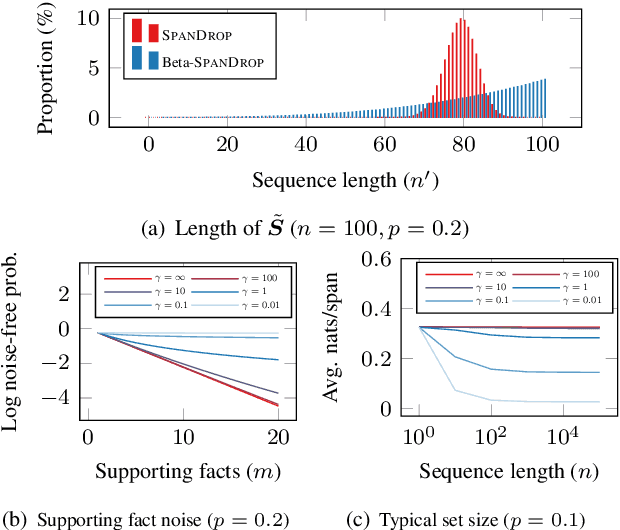
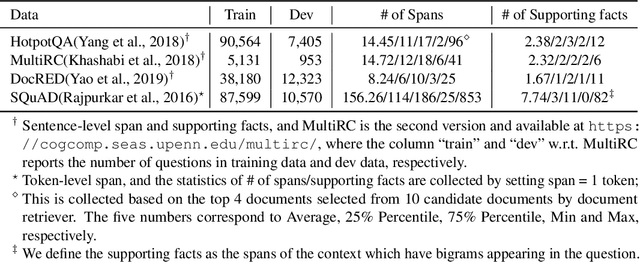
Distilling supervision signal from a long sequence to make predictions is a challenging task in machine learning, especially when not all elements in the input sequence contribute equally to the desired output. In this paper, we propose SpanDrop, a simple and effective data augmentation technique that helps models identify the true supervision signal in a long sequence with very few examples. By directly manipulating the input sequence, SpanDrop randomly ablates parts of the sequence at a time and ask the model to perform the same task to emulate counterfactual learning and achieve input attribution. Based on theoretical analysis of its properties, we also propose a variant of SpanDrop based on the beta-Bernoulli distribution, which yields diverse augmented sequences while providing a learning objective that is more consistent with the original dataset. We demonstrate the effectiveness of SpanDrop on a set of carefully designed toy tasks, as well as various natural language processing tasks that require reasoning over long sequences to arrive at the correct answer, and show that it helps models improve performance both when data is scarce and abundant.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022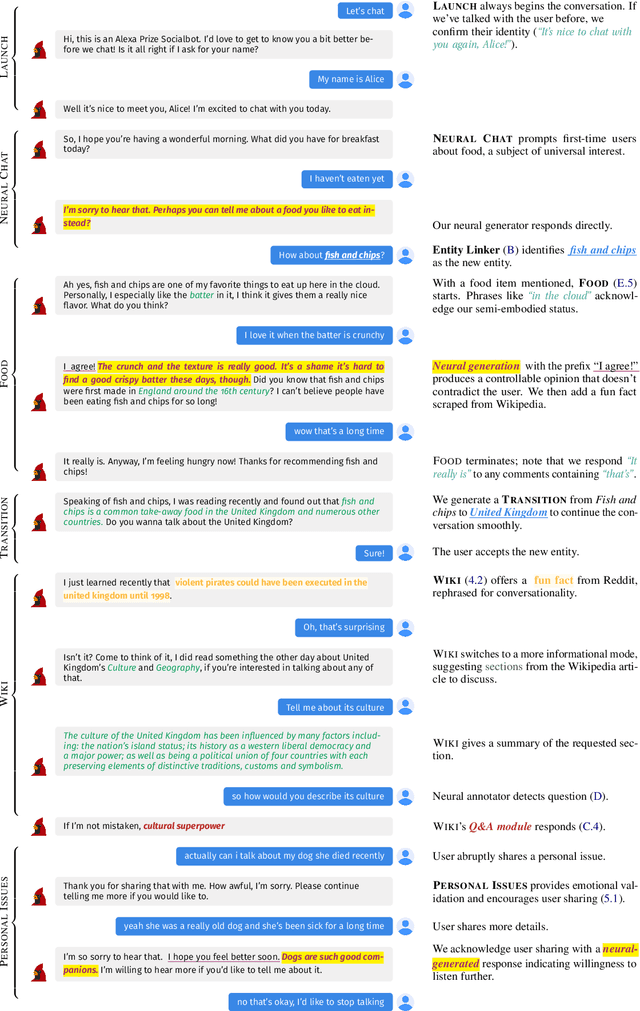


We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
DRAG: Dynamic Region-Aware GCN for Privacy-Leaking Image Detection
Mar 17, 2022
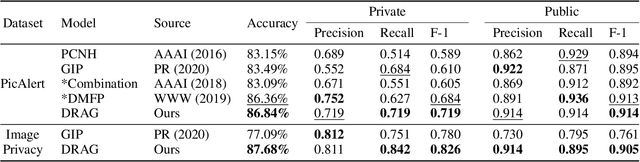
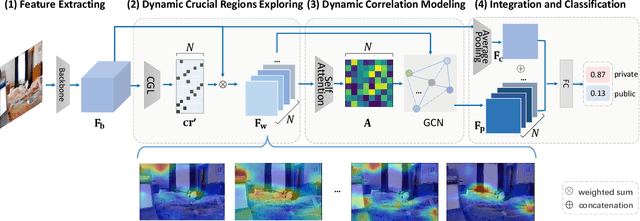
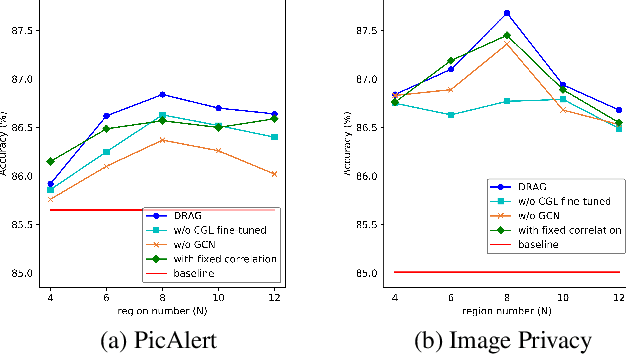
The daily practice of sharing images on social media raises a severe issue about privacy leakage. To address the issue, privacy-leaking image detection is studied recently, with the goal to automatically identify images that may leak privacy. Recent advance on this task benefits from focusing on crucial objects via pretrained object detectors and modeling their correlation. However, these methods have two limitations: 1) they neglect other important elements like scenes, textures, and objects beyond the capacity of pretrained object detectors; 2) the correlation among objects is fixed, but a fixed correlation is not appropriate for all the images. To overcome the limitations, we propose the Dynamic Region-Aware Graph Convolutional Network (DRAG) that dynamically finds out crucial regions including objects and other important elements, and models their correlation adaptively for each input image. To find out crucial regions, we cluster spatially-correlated feature channels into several region-aware feature maps. Further, we dynamically model the correlation with the self-attention mechanism and explore the interaction among the regions with a graph convolutional network. The DRAG achieved an accuracy of 87% on the largest dataset for privacy-leaking image detection, which is 10 percentage points higher than the state of the art. The further case study demonstrates that it found out crucial regions containing not only objects but other important elements like textures.
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
Mar 01, 2022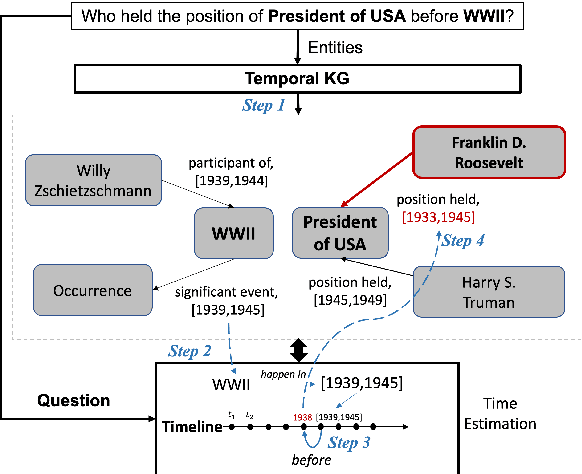
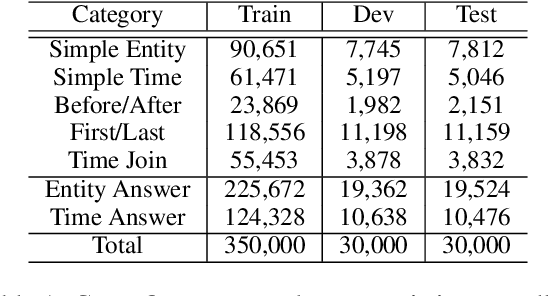
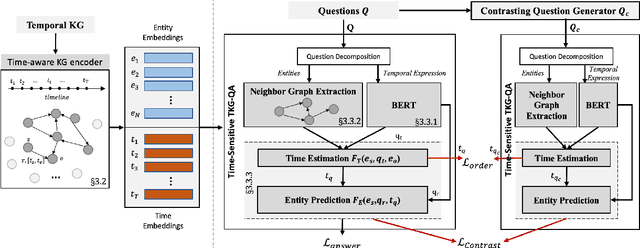
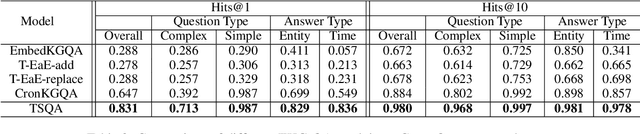
Question answering over temporal knowledge graphs (KGs) efficiently uses facts contained in a temporal KG, which records entity relations and when they occur in time, to answer natural language questions (e.g., "Who was the president of the US before Obama?"). These questions often involve three time-related challenges that previous work fail to adequately address: 1) questions often do not specify exact timestamps of interest (e.g., "Obama" instead of 2000); 2) subtle lexical differences in time relations (e.g., "before" vs "after"); 3) off-the-shelf temporal KG embeddings that previous work builds on ignore the temporal order of timestamps, which is crucial for answering temporal-order related questions. In this paper, we propose a time-sensitive question answering (TSQA) framework to tackle these problems. TSQA features a timestamp estimation module to infer the unwritten timestamp from the question. We also employ a time-sensitive KG encoder to inject ordering information into the temporal KG embeddings that TSQA is based on. With the help of techniques to reduce the search space for potential answers, TSQA significantly outperforms the previous state of the art on a new benchmark for question answering over temporal KGs, especially achieving a 32% (absolute) error reduction on complex questions that require multiple steps of reasoning over facts in the temporal KG.
* 10 pages, 2 figures
Trustworthy AI: From Principles to Practices
Oct 04, 2021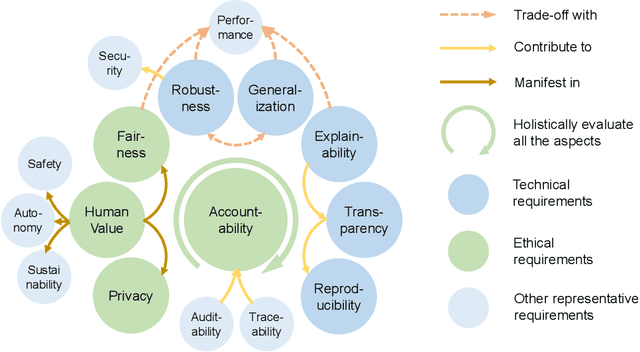
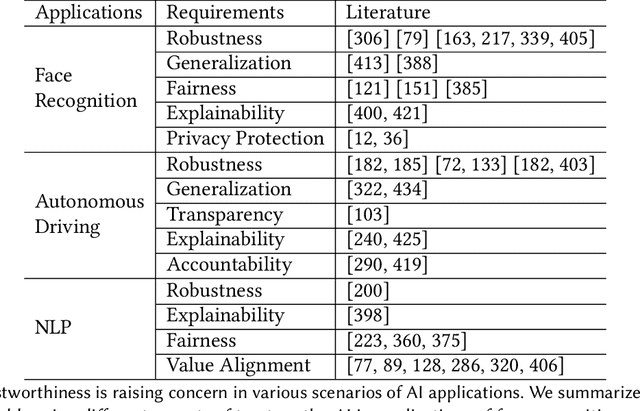
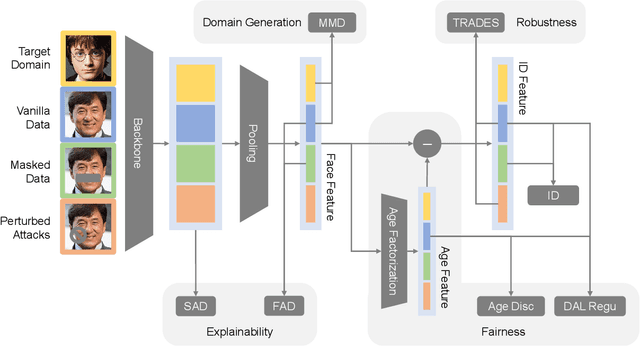
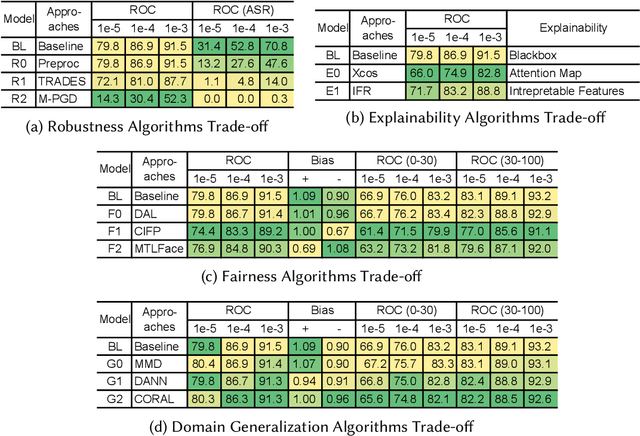
Fast developing artificial intelligence (AI) technology has enabled various applied systems deployed in the real world, impacting people's everyday lives. However, many current AI systems were found vulnerable to imperceptible attacks, biased against underrepresented groups, lacking in user privacy protection, etc., which not only degrades user experience but erodes the society's trust in all AI systems. In this review, we strive to provide AI practitioners a comprehensive guide towards building trustworthy AI systems. We first introduce the theoretical framework of important aspects of AI trustworthiness, including robustness, generalization, explainability, transparency, reproducibility, fairness, privacy preservation, alignment with human values, and accountability. We then survey leading approaches in these aspects in the industry. To unify the current fragmented approaches towards trustworthy AI, we propose a systematic approach that considers the entire lifecycle of AI systems, ranging from data acquisition to model development, to development and deployment, finally to continuous monitoring and governance. In this framework, we offer concrete action items to practitioners and societal stakeholders (e.g., researchers and regulators) to improve AI trustworthiness. Finally, we identify key opportunities and challenges in the future development of trustworthy AI systems, where we identify the need for paradigm shift towards comprehensive trustworthy AI systems.
VeniBot: Towards Autonomous Venipuncture with Automatic Puncture Area and Angle Regression from NIR Images
May 27, 2021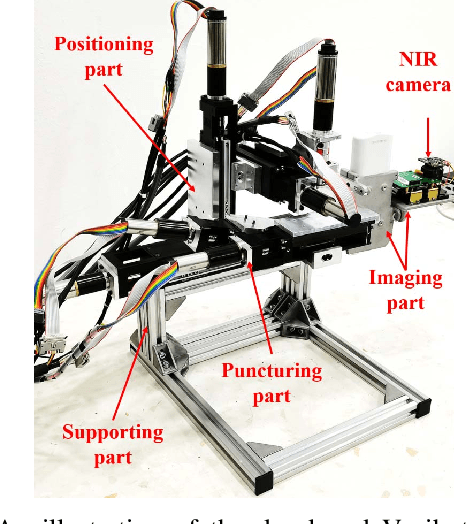
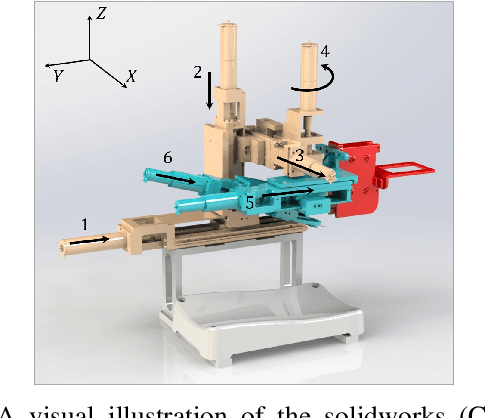
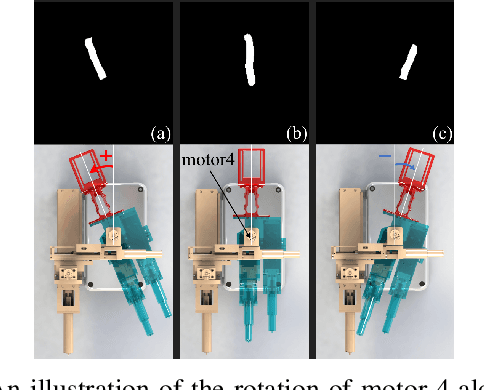
Venipucture is a common step in clinical scenarios, and is with highly practical value to be automated with robotics. Nowadays, only a few on-shelf robotic systems are developed, however, they can not fulfill practical usage due to varied reasons. In this paper, we develop a compact venipucture robot -- VeniBot, with four parts, six motors and two imaging devices. For the automation, we focus on the positioning part and propose a Dual-In-Dual-Out network based on two-step learning and two-task learning, which can achieve fully automatic regression of the suitable puncture area and angle from near-infrared(NIR) images. The regressed suitable puncture area and angle can further navigate the positioning part of VeniBot, which is an important step towards a fully autonomous venipucture robot. Validation on 30 VeniBot-collected volunteers shows a high mean dice coefficient(DSC) of 0.7634 and a low angle error of 15.58{\deg} on suitable puncture area and angle regression respectively, indicating its potentially wide and practical application in the future.
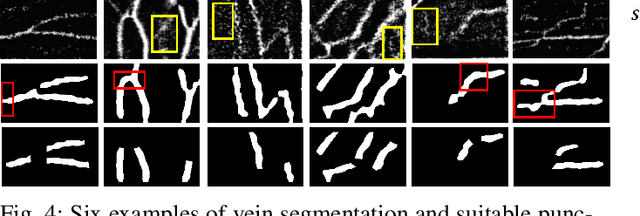
VeniBot: Towards Autonomous Venipuncture with Semi-supervised Vein Segmentation from Ultrasound Images
May 27, 2021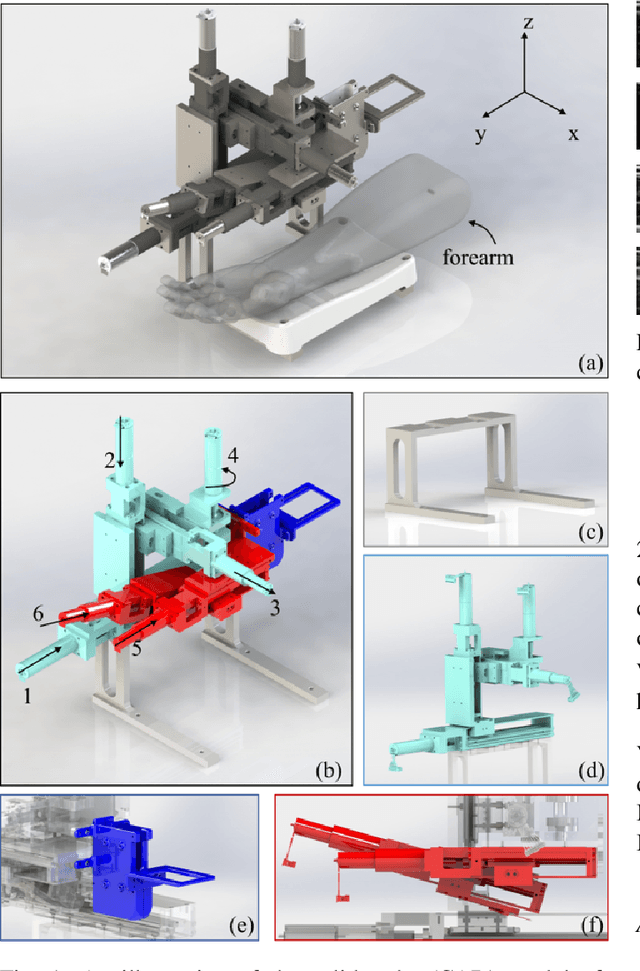
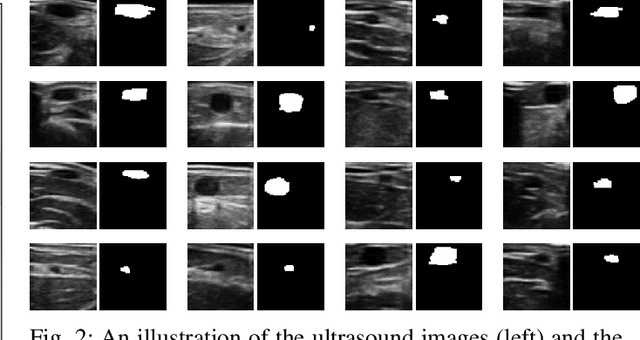
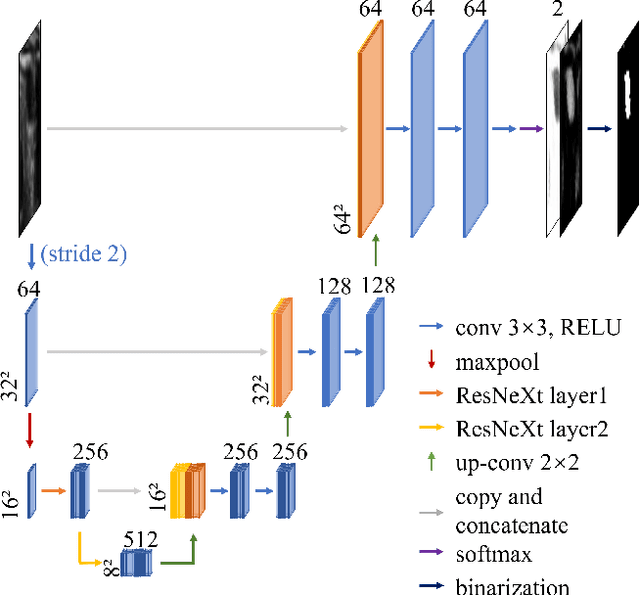

In the modern medical care, venipuncture is an indispensable procedure for both diagnosis and treatment. In this paper, unlike existing solutions that fully or partially rely on professional assistance, we propose VeniBot -- a compact robotic system solution integrating both novel hardware and software developments. For the hardware, we design a set of units to facilitate the supporting, positioning, puncturing and imaging functionalities. For the software, to move towards a full automation, we propose a novel deep learning framework -- semi-ResNeXt-Unet for semi-supervised vein segmentation from ultrasound images. From which, the depth information of vein is calculated and used to enable automated navigation for the puncturing unit. VeniBot is validated on 40 volunteers, where ultrasound images can be collected successfully. For the vein segmentation validation, the proposed semi-ResNeXt-Unet improves the dice similarity coefficient (DSC) by 5.36%, decreases the centroid error by 1.38 pixels and decreases the failure rate by 5.60%, compared to fully-supervised ResNeXt-Unet.
Conversational AI Systems for Social Good: Opportunities and Challenges
May 13, 2021
Conversational artificial intelligence (ConvAI) systems have attracted much academic and commercial attention recently, making significant progress on both fronts. However, little existing work discusses how these systems can be developed and deployed for social good. In this paper, we briefly review the progress the community has made towards better ConvAI systems and reflect on how existing technologies can help advance social good initiatives from various angles that are unique for ConvAI, or not yet become common knowledge in the community. We further discuss about the challenges ahead for ConvAI systems to better help us achieve these goals and highlight the risks involved in their development and deployment in the real world.
Graph Ensemble Learning over Multiple Dependency Trees for Aspect-level Sentiment Classification
Mar 12, 2021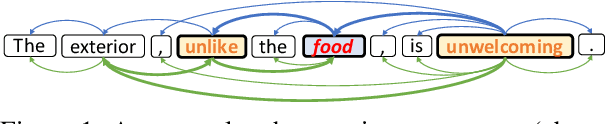
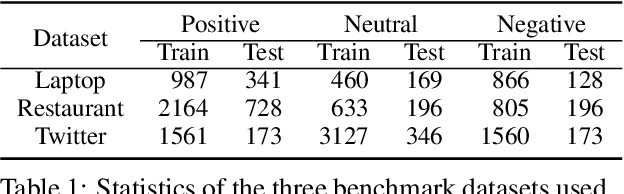
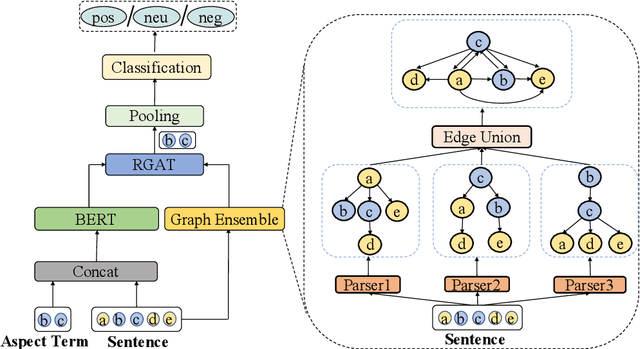
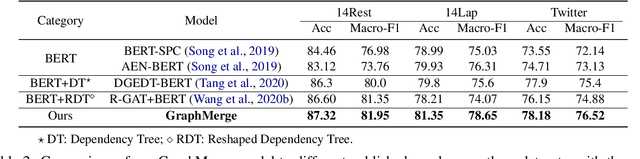
Recent work on aspect-level sentiment classification has demonstrated the efficacy of incorporating syntactic structures such as dependency trees with graph neural networks(GNN), but these approaches are usually vulnerable to parsing errors. To better leverage syntactic information in the face of unavoidable errors, we propose a simple yet effective graph ensemble technique, GraphMerge, to make use of the predictions from differ-ent parsers. Instead of assigning one set of model parameters to each dependency tree, we first combine the dependency relations from different parses before applying GNNs over the resulting graph. This allows GNN mod-els to be robust to parse errors at no additional computational cost, and helps avoid overparameterization and overfitting from GNN layer stacking by introducing more connectivity into the ensemble graph. Our experiments on the SemEval 2014 Task 4 and ACL 14 Twitter datasets show that our GraphMerge model not only outperforms models with single dependency tree, but also beats other ensemble mod-els without adding model parameters.