 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAvatar: Unlocking Highly Expressive Avatars via Harmonized Text-Audio Conditioning
Jan 31, 2026Existing video avatar models have demonstrated impressive capabilities in scenarios such as talking, public speaking, and singing. However, the majority of these methods exhibit limited alignment with respect to text instructions, particularly when the prompts involve complex elements including large full-body movement, dynamic camera trajectory, background transitions, or human-object interactions. To break out this limitation, we present JoyAvatar, a framework capable of generating long duration avatar videos, featuring two key technical innovations. Firstly, we introduce a twin-teacher enhanced training algorithm that enables the model to transfer inherent text-controllability from the foundation model while simultaneously learning audio-visual synchronization. Secondly, during training, we dynamically modulate the strength of multi-modal conditions (e.g., audio and text) based on the distinct denoising timestep, aiming to mitigate conflicts between the heterogeneous conditioning signals. These two key designs serve to substantially expand the avatar model's capacity to generate natural, temporally coherent full-body motions and dynamic camera movements as well as preserve the basic avatar capabilities, such as accurate lip-sync and identity consistency. GSB evaluation results demonstrate that our JoyAvatar model outperforms the state-of-the-art models such as Omnihuman-1.5 and KlingAvatar 2.0. Moreover, our approach enables complex applications including multi-person dialogues and non-human subjects role-playing. Some video samples are provided on https://joyavatar.github.io/.
JoyAvatar: Real-time and Infinite Audio-Driven Avatar Generation with Autoregressive Diffusion
Dec 12, 2025Existing DiT-based audio-driven avatar generation methods have achieved considerable progress, yet their broader application is constrained by limitations such as high computational overhead and the inability to synthesize long-duration videos. Autoregressive methods address this problem by applying block-wise autoregressive diffusion methods. However, these methods suffer from the problem of error accumulation and quality degradation. To address this, we propose JoyAvatar, an audio-driven autoregressive model capable of real-time inference and infinite-length video generation with the following contributions: (1) Progressive Step Bootstrapping (PSB), which allocates more denoising steps to initial frames to stabilize generation and reduce error accumulation; (2) Motion Condition Injection (MCI), enhancing temporal coherence by injecting noise-corrupted previous frames as motion condition; and (3) Unbounded RoPE via Cache-Resetting (URCR), enabling infinite-length generation through dynamic positional encoding. Our 1.3B-parameter causal model achieves 16 FPS on a single GPU and achieves competitive results in visual quality, temporal consistency, and lip synchronization.
PAC: Pronunciation-Aware Contextualized Large Language Model-based Automatic Speech Recognition
Sep 16, 2025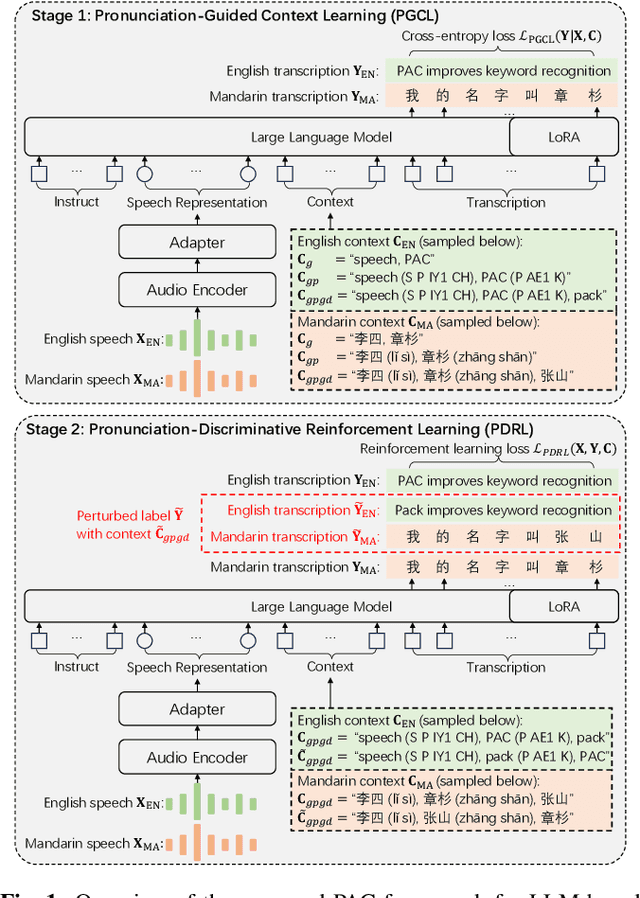



This paper presents a Pronunciation-Aware Contextualized (PAC) framework to address two key challenges in Large Language Model (LLM)-based Automatic Speech Recognition (ASR) systems: effective pronunciation modeling and robust homophone discrimination. Both are essential for raw or long-tail word recognition. The proposed approach adopts a two-stage learning paradigm. First, we introduce a pronunciation-guided context learning method. It employs an interleaved grapheme-phoneme context modeling strategy that incorporates grapheme-only distractors, encouraging the model to leverage phonemic cues for accurate recognition. Then, we propose a pronunciation-discriminative reinforcement learning method with perturbed label sampling to further enhance the model\'s ability to distinguish contextualized homophones. Experimental results on the public English Librispeech and Mandarin AISHELL-1 datasets indicate that PAC: (1) reduces relative Word Error Rate (WER) by 30.2% and 53.8% compared to pre-trained LLM-based ASR models, and (2) achieves 31.8% and 60.5% relative reductions in biased WER for long-tail words compared to strong baselines, respectively.
UME: Upcycling Mixture-of-Experts for Scalable and Efficient Automatic Speech Recognition
Dec 23, 2024



Recent advancements in scaling up models have significantly improved performance in Automatic Speech Recognition (ASR) tasks. However, training large ASR models from scratch remains costly. To address this issue, we introduce UME, a novel method that efficiently Upcycles pretrained dense ASR checkpoints into larger Mixture-of-Experts (MoE) architectures. Initially, feed-forward networks are converted into MoE layers. By reusing the pretrained weights, we establish a robust foundation for the expanded model, significantly reducing optimization time. Then, layer freezing and expert balancing strategies are employed to continue training the model, further enhancing performance. Experiments on a mixture of 170k-hour Mandarin and English datasets show that UME: 1) surpasses the pretrained baseline by a margin of 11.9% relative error rate reduction while maintaining comparable latency; 2) reduces training time by up to 86.7% and achieves superior accuracy compared to training models of the same size from scratch.
Leveraging Label Information for Multimodal Emotion Recognition
Sep 05, 2023Multimodal emotion recognition (MER) aims to detect the emotional status of a given expression by combining the speech and text information. Intuitively, label information should be capable of helping the model locate the salient tokens/frames relevant to the specific emotion, which finally facilitates the MER task. Inspired by this, we propose a novel approach for MER by leveraging label information. Specifically, we first obtain the representative label embeddings for both text and speech modalities, then learn the label-enhanced text/speech representations for each utterance via label-token and label-frame interactions. Finally, we devise a novel label-guided attentive fusion module to fuse the label-aware text and speech representations for emotion classification. Extensive experiments were conducted on the public IEMOCAP dataset, and experimental results demonstrate that our proposed approach outperforms existing baselines and achieves new state-of-the-art performance.
AUGUST: an Automatic Generation Understudy for Synthesizing Conversational Recommendation Datasets
Jun 16, 2023



High-quality data is essential for conversational recommendation systems and serves as the cornerstone of the network architecture development and training strategy design. Existing works contribute heavy human efforts to manually labeling or designing and extending recommender dialogue templates. However, they suffer from (i) the limited number of human annotators results in that datasets can hardly capture rich and large-scale cases in the real world, (ii) the limited experience and knowledge of annotators account for the uninformative corpus and inappropriate recommendations. In this paper, we propose a novel automatic dataset synthesis approach that can generate both large-scale and high-quality recommendation dialogues through a data2text generation process, where unstructured recommendation conversations are generated from structured graphs based on user-item information from the real world. In doing so, we comprehensively exploit: (i) rich personalized user profiles from traditional recommendation datasets, (ii) rich external knowledge from knowledge graphs, and (iii) the conversation ability contained in human-to-human conversational recommendation datasets. Extensive experiments validate the benefit brought by the automatically synthesized data under low-resource scenarios and demonstrate the promising potential to facilitate the development of a more effective conversational recommendation system.
OTF: Optimal Transport based Fusion of Supervised and Self-Supervised Learning Models for Automatic Speech Recognition
Jun 05, 2023



Self-Supervised Learning (SSL) Automatic Speech Recognition (ASR) models have shown great promise over Supervised Learning (SL) ones in low-resource settings. However, the advantages of SSL are gradually weakened when the amount of labeled data increases in many industrial applications. To further improve the ASR performance when abundant labels are available, we first explore the potential of combining SL and SSL ASR models via analyzing their complementarity in recognition accuracy and optimization property. Then, we propose a novel Optimal Transport based Fusion (OTF) method for SL and SSL models without incurring extra computation cost in inference. Specifically, optimal transport is adopted to softly align the layer-wise weights to unify the two different networks into a single one. Experimental results on the public 1k-hour English LibriSpeech dataset and our in-house 2.6k-hour Chinese dataset show that OTF largely outperforms the individual models with lower error rates.
SegCLIP: Patch Aggregation with Learnable Centers for Open-Vocabulary Semantic Segmentation
Nov 27, 2022



Recently, the contrastive language-image pre-training, e.g., CLIP, has demonstrated promising results on various downstream tasks. The pre-trained model can capture enriched visual concepts for images by learning from a large scale of text-image data. However, transferring the learned visual knowledge to open-vocabulary semantic segmentation is still under-explored. In this paper, we propose a CLIP-based model named SegCLIP for the topic of open-vocabulary segmentation in an annotation-free manner. The SegCLIP achieves segmentation based on ViT and the main idea is to gather patches with learnable centers to semantic regions through training on text-image pairs. The gathering operation can dynamically capture the semantic groups, which can be used to generate the final segmentation results. We further propose a reconstruction loss on masked patches and a superpixel-based KL loss with pseudo-labels to enhance the visual representation. Experimental results show that our model achieves comparable or superior segmentation accuracy on the PASCAL VOC 2012 (+1.4% mIoU), PASCAL Context (+2.4% mIoU), and COCO (+5.6% mIoU) compared with baselines. We release the code at https://github.com/ArrowLuo/SegCLIP.
Multi-Speaker Multi-Style Speech Synthesis with Timbre and Style Disentanglement
Nov 22, 2022Disentanglement of a speaker's timbre and style is very important for style transfer in multi-speaker multi-style text-to-speech (TTS) scenarios. With the disentanglement of timbres and styles, TTS systems could synthesize expressive speech for a given speaker with any style which has been seen in the training corpus. However, there are still some shortcomings with the current research on timbre and style disentanglement. The current method either requires single-speaker multi-style recordings, which are difficult and expensive to collect, or uses a complex network and complicated training method, which is difficult to reproduce and control the style transfer behavior. To improve the disentanglement effectiveness of timbres and styles, and to remove the reliance on single-speaker multi-style corpus, a simple but effective timbre and style disentanglement method is proposed in this paper. The FastSpeech2 network is employed as the backbone network, with explicit duration, pitch, and energy trajectory to represent the style. Each speaker's data is considered as a separate and isolated style, then a speaker embedding and a style embedding are added to the FastSpeech2 network to learn disentangled representations. Utterance level pitch and energy normalization are utilized to improve the decoupling effect. Experimental results demonstrate that the proposed model could synthesize speech with any style seen during training with high style similarity while maintaining very high speaker similarity.
MoNET: Tackle State Momentum via Noise-Enhanced Training for Dialogue State Tracking
Nov 11, 2022



Dialogue state tracking (DST) aims to convert the dialogue history into dialogue states which consist of slot-value pairs. As condensed structural information memorizing all history information, the dialogue state in the last turn is typically adopted as the input for predicting the current state by DST models. However, these models tend to keep the predicted slot values unchanged, which is defined as state momentum in this paper. Specifically, the models struggle to update slot values that need to be changed and correct wrongly predicted slot values in the last turn. To this end, we propose MoNET to tackle state momentum via noise-enhanced training. First, the previous state of each turn in the training data is noised via replacing some of its slot values. Then, the noised previous state is used as the input to learn to predict the current state, improving the model's ability to update and correct slot values. Furthermore, a contrastive context matching framework is designed to narrow the representation distance between a state and its corresponding noised variant, which reduces the impact of noised state and makes the model better understand the dialogue history. Experimental results on MultiWOZ datasets show that MoNET outperforms previous DST methods. Ablations and analysis verify the effectiveness of MoNET in alleviating state momentum and improving anti-noise ability.