 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-VLA: A High-Concurrency Distributed Asynchronous Reinforcement Learning Framework for Vision-Language-Action Models
May 14, 2026The rapid evolution of Embodied AI has enabled Vision-Language-Action (VLA) models to excel in multimodal perception and task execution. However, applying Reinforcement Learning (RL) to these massive models in large-scale distributed environments faces severe systemic bottlenecks, primarily due to the resource conflict between high-fidelity physical simulation and the intensive VRAM/bandwidth demands of deep learning. This conflict often leaves overall throughput constrained by execution-phase inefficiencies. To address these challenges, we propose D-VLA, a high-concurrency, low-latency distributed RL framework for large-scale embodied foundation models. D-VLA introduces "Plane Decoupling," physically isolating high-frequency training data from low-frequency weight control to eliminate interference between simulation and optimization. We further design a four-thread asynchronous "Swimlane" pipeline, enabling full parallel overlap of sampling, inference, gradient computation, and parameter distribution. Additionally, a dual-pool VRAM management model and topology-aware replication resolve memory fragmentation and optimize communication efficiency. Experiments on benchmarks like LIBERO show that D-VLA significantly outperforms mainstream RL frameworks in throughput and sampling efficiency for billion-parameter VLA models. In trillion-parameter scalability tests, our framework maintains exceptional stability and linear speedup, providing a robust system for high-performance general-purpose embodied agents.
Missing Old Logits in Asynchronous Agentic RL: Semantic Mismatch and Repair Methods for Off-Policy Correction
May 12, 2026Asynchronous reinforcement learning improves rollout throughput for large language model agents by decoupling sample generation from policy optimization, but it also introduces a critical failure mode for PPO-style off-policy correction. In heterogeneous training systems, the total importance ratio should ideally be decomposed into two semantically distinct factors: a \emph{training--inference discrepancy term} that aligns inference-side and training-side distributions at the same behavior-policy version, and a \emph{policy-staleness term} that constrains the update from the historical policy to the current policy. We show that practical asynchronous pipelines with delayed updates and partial rollouts often lose the required historical training-side logits, or old logits. This missing-old-logit problem entangles discrepancy repair with staleness correction, breaks the intended semantics of decoupled correction, and makes clipping and masking thresholds interact undesirably. To address this issue, we study both exact and approximate correction routes. We propose three exact old-logit acquisition strategies: snapshot-based version tracking, a dedicated old-logit model, and synchronization via partial rollout interruption, and compare their system trade-offs. From the perspective of approximate correction, we focus on preserving the benefits of decoupled correction through a more appropriate approximate policy when exact old logits cannot be recovered at low cost, without incurring extra system overhead. Following this analysis, we adopt a revised PPO-EWMA method, which achieves significant gains in both training speed and optimization performance. Code at https://github.com/millioniron/ROLL.
JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
Apr 22, 2026Robotic autonomy in open-world environments is fundamentally limited by insufficient data diversity and poor cross-embodiment generalization. Existing robotic datasets are often limited in scale and task coverage, while relatively large differences across robot embodiments impede effective behavior knowledge transfer. To address these challenges, we propose JoyAI-RA, a vision-language-action (VLA) embodied foundation model tailored for generalizable robotic manipulation. JoyAI-RA presents a multi-source multi-level pretraining framework that integrates web data, large-scale egocentric human manipulation videos, simulation-generated trajectories, and real-robot data. Through training on heterogeneous multi-source data with explicit action-space unification, JoyAI-RA effectively bridges embodiment gaps, particularly between human manipulation and robotic control, thereby enhancing cross-embodiment behavior learning. JoyAI-RA outperforms state-of-the-art methods in both simulation and real-world benchmarks, especially on diverse tasks with generalization demands.
Thousand-GPU Large-Scale Training and Optimization Recipe for AI-Native Cloud Embodied Intelligence Infrastructure
Mar 11, 2026Embodied intelligence is a key step towards Artificial General Intelligence (AGI), yet its development faces multiple challenges including data, frameworks, infrastructure, and evaluation systems. To address these issues, we have, for the first time in the industry, launched a cloud-based, thousand-GPU distributed training platform for embodied intelligence, built upon the widely adopted LeRobot framework, and have systematically overcome bottlenecks across the entire pipeline. At the data layer, we have restructured the data pipeline to optimize the flow of embodied training data. In terms of training, for the GR00T-N1.5 model, utilizing thousand-GPU clusters and data at the scale of hundreds of millions, the single-round training time has been reduced from 15 hours to just 22 minutes, achieving a 40-fold speedup. At the model layer, by combining variable-length FlashAttention and Data Packing, we have moved from sample redundancy to sequence integration, resulting in a 188% speed increase; π-0.5 attention optimization has accelerated training by 165%; and FP8 quantization has delivered a 140% speedup. On the infrastructure side, relying on high-performance storage, a 3.2T RDMA network, and a Ray-driven elastic AI data lake, we have achieved deep synergy among data, storage, communication, and computation. We have also built an end-to-end evaluation system, creating a closed loop from training to simulation to assessment. This framework has already been fully validated on thousand-GPU clusters, laying a crucial technical foundation for the development and application of next-generation autonomous intelligent robots, and is expected to accelerate the arrival of the era of human-machine integration.
RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Trustworthy AI: From Principles to Practices
Oct 04, 2021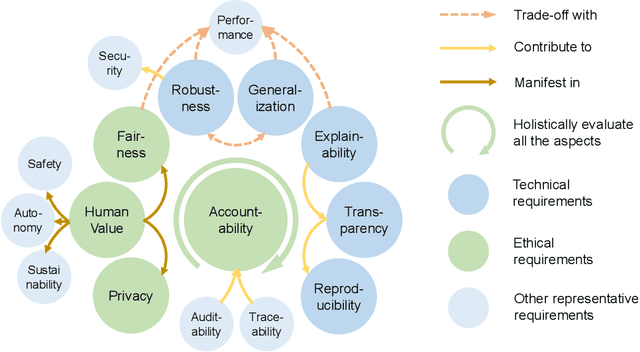
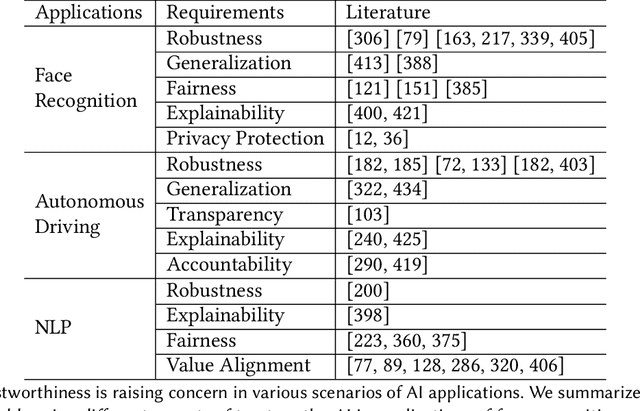
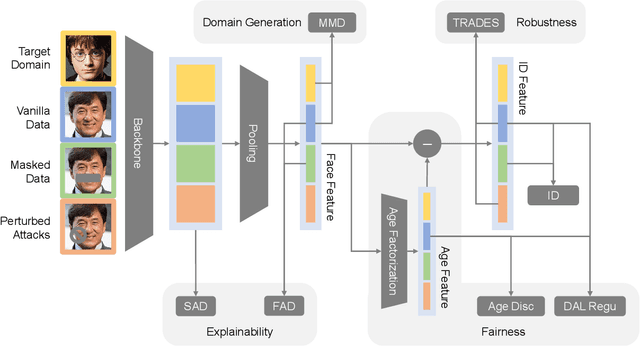
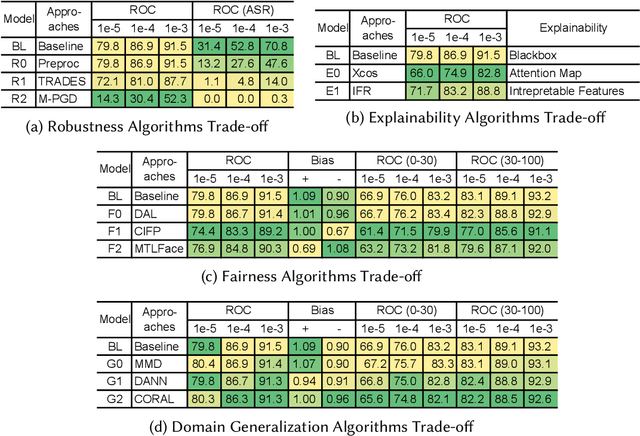
Fast developing artificial intelligence (AI) technology has enabled various applied systems deployed in the real world, impacting people's everyday lives. However, many current AI systems were found vulnerable to imperceptible attacks, biased against underrepresented groups, lacking in user privacy protection, etc., which not only degrades user experience but erodes the society's trust in all AI systems. In this review, we strive to provide AI practitioners a comprehensive guide towards building trustworthy AI systems. We first introduce the theoretical framework of important aspects of AI trustworthiness, including robustness, generalization, explainability, transparency, reproducibility, fairness, privacy preservation, alignment with human values, and accountability. We then survey leading approaches in these aspects in the industry. To unify the current fragmented approaches towards trustworthy AI, we propose a systematic approach that considers the entire lifecycle of AI systems, ranging from data acquisition to model development, to development and deployment, finally to continuous monitoring and governance. In this framework, we offer concrete action items to practitioners and societal stakeholders (e.g., researchers and regulators) to improve AI trustworthiness. Finally, we identify key opportunities and challenges in the future development of trustworthy AI systems, where we identify the need for paradigm shift towards comprehensive trustworthy AI systems.