 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Graph Based Approaches for Author Name Disambiguation
Dec 12, 2023In many applications, such as scientific literature management, researcher search, social network analysis and etc, Name Disambiguation (aiming at disambiguating WhoIsWho) has been a challenging problem. In addition, the growth of scientific literature makes the problem more difficult and urgent. Although name disambiguation has been extensively studied in academia and industry, the problem has not been solved well due to the clutter of data and the complexity of the same name scenario. In this work, we aim to explore models that can perform the task of name disambiguation using the network structure that is intrinsic to the problem and present an analysis of the models.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022


We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
Routing algorithms as tools for integrating social distancing with emergency evacuation
Mar 05, 2021

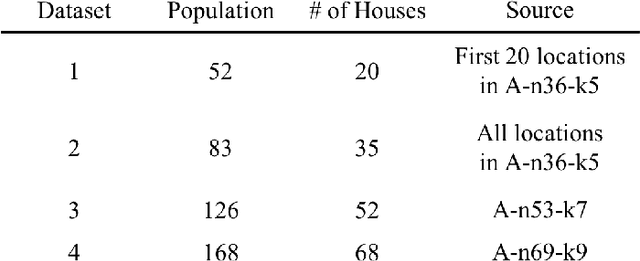
In this study, we explore the implications of integrating social distancing with emergency evacuation when a hurricane approaches a major city during the COVID-19 pandemic. Specifically, we compare DNN (Deep Neural Network)-based and non-DNN methods for generating evacuation strategies that minimize evacuation time while allowing for social distancing in rescue vehicles. A central question is whether a DNN-based method provides sufficient extra efficiency to accommodate social distancing, in a time-constrained evacuation operation. We describe the problem as a Capacitated Vehicle Routing Problem and solve it using one non-DNN solution (Sweep Algorithm) and one DNN-based solution (Deep Reinforcement Learning). DNN-based solution can provide decision-makers with more efficient routing than non-DNN solution. Although DNN-based solution can save considerable time in evacuation routing, it does not come close to compensating for the extra time required for social distancing and its advantage disappears as the vehicle capacity approaches the number of people per household.
Can We Achieve More with Less? Exploring Data Augmentation for Toxic Comment Classification
Jul 02, 2020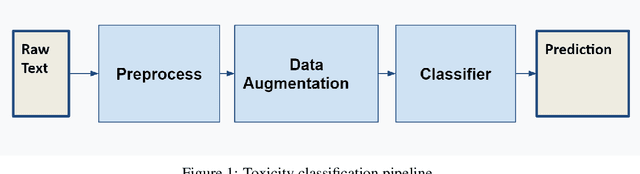
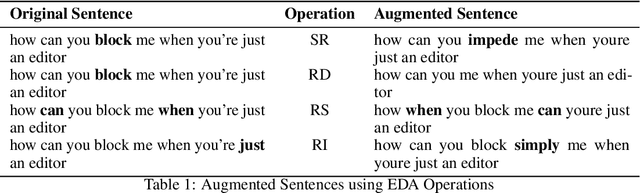
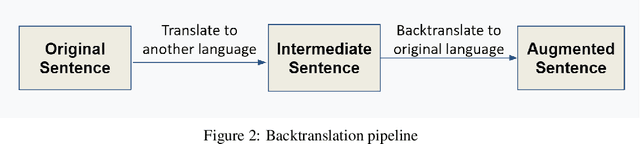

This paper tackles one of the greatest limitations in Machine Learning: Data Scarcity. Specifically, we explore whether high accuracy classifiers can be built from small datasets, utilizing a combination of data augmentation techniques and machine learning algorithms. In this paper, we experiment with Easy Data Augmentation (EDA) and Backtranslation, as well as with three popular learning algorithms, Logistic Regression, Support Vector Machine (SVM), and Bidirectional Long Short-Term Memory Network (Bi-LSTM). For our experimentation, we utilize the Wikipedia Toxic Comments dataset so that in the process of exploring the benefits of data augmentation, we can develop a model to detect and classify toxic speech in comments to help fight back against cyberbullying and online harassment. Ultimately, we found that data augmentation techniques can be used to significantly boost the performance of classifiers and are an excellent strategy to combat lack of data in NLP problems.