 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumina-OmniLV: A Unified Multimodal Framework for General Low-Level Vision
Apr 08, 2025We present Lunima-OmniLV (abbreviated as OmniLV), a universal multimodal multi-task framework for low-level vision that addresses over 100 sub-tasks across four major categories: image restoration, image enhancement, weak-semantic dense prediction, and stylization. OmniLV leverages both textual and visual prompts to offer flexible and user-friendly interactions. Built on Diffusion Transformer (DiT)-based generative priors, our framework supports arbitrary resolutions -- achieving optimal performance at 1K resolution -- while preserving fine-grained details and high fidelity. Through extensive experiments, we demonstrate that separately encoding text and visual instructions, combined with co-training using shallow feature control, is essential to mitigate task ambiguity and enhance multi-task generalization. Our findings also reveal that integrating high-level generative tasks into low-level vision models can compromise detail-sensitive restoration. These insights pave the way for more robust and generalizable low-level vision systems.
Localization and Tracking for Cooperative Users in Multi-RIS-assisted Systems: Theoretical Analysis and Principles of Interpretations
Apr 07, 2025



Localization and tracking (LocTrack) are fundamental enablers for a wide range of emerging applications. Reconfigurable intelligent surfaces (RISs) have emerged as key components for enhancing the LocTrack performance. This paper investigates a multi-RIS-assisted multi-user (MRMU) LocTrack system, where multiple RISs collaboratively reflect the position-bearing signals for information fusion at the base station, leveraging spatial-temporal correlations in user positions. While studies have shown these correlations improve localization accuracy, their trade-offs with system complexity remain unclear. To address this gap, we characterize the effectiveness of spatial-temporal correlation priors (STPs) utilization in MRMU LocTrack systems using a metric, termed efficiency of correlation (EoC). To further elucidate correlation propagation and RIS interactions, we provide a "correlation information routing" interpretation of EoC through random walk theory. EoC provides a principled performance evaluation metric, that enables system designers to balance localization accuracy enhancement against the increased complexity. Additionally, we investigate the error propagation phenomenon, analyzing its convergence and asymptotic behavior in MRMU LocTrack systems. Finally, we validate the theoretical results through extensive numerical simulations.
NCL-CIR: Noise-aware Contrastive Learning for Composed Image Retrieval
Apr 06, 2025Composed Image Retrieval (CIR) seeks to find a target image using a multi-modal query, which combines an image with modification text to pinpoint the target. While recent CIR methods have shown promise, they mainly focus on exploring relationships between the query pairs (image and text) through data augmentation or model design. These methods often assume perfect alignment between queries and target images, an idealized scenario rarely encountered in practice. In reality, pairs are often partially or completely mismatched due to issues like inaccurate modification texts, low-quality target images, and annotation errors. Ignoring these mismatches leads to numerous False Positive Pair (FFPs) denoted as noise pairs in the dataset, causing the model to overfit and ultimately reducing its performance. To address this problem, we propose the Noise-aware Contrastive Learning for CIR (NCL-CIR), comprising two key components: the Weight Compensation Block (WCB) and the Noise-pair Filter Block (NFB). The WCB coupled with diverse weight maps can ensure more stable token representations of multi-modal queries and target images. Meanwhile, the NFB, in conjunction with the Gaussian Mixture Model (GMM) predicts noise pairs by evaluating loss distributions, and generates soft labels correspondingly, allowing for the design of the soft-label based Noise Contrastive Estimation (NCE) loss function. Consequently, the overall architecture helps to mitigate the influence of mismatched and partially matched samples, with experimental results demonstrating that NCL-CIR achieves exceptional performance on the benchmark datasets.
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025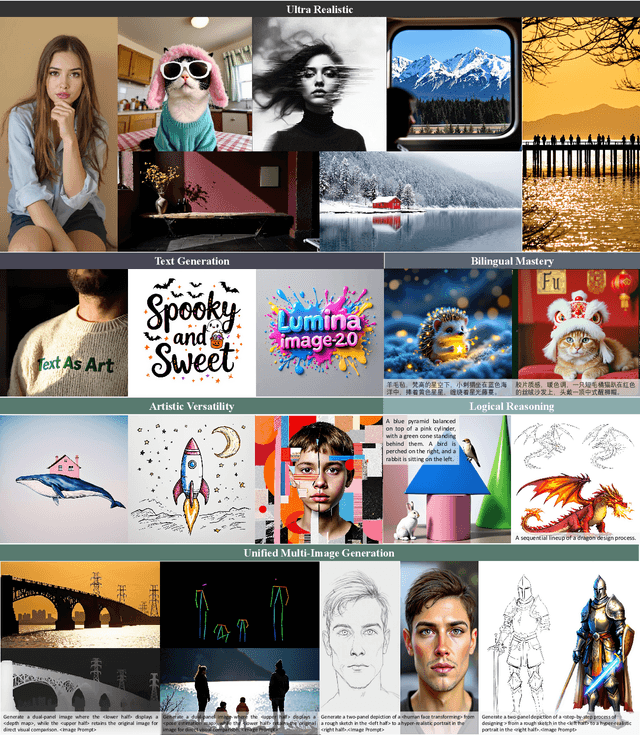
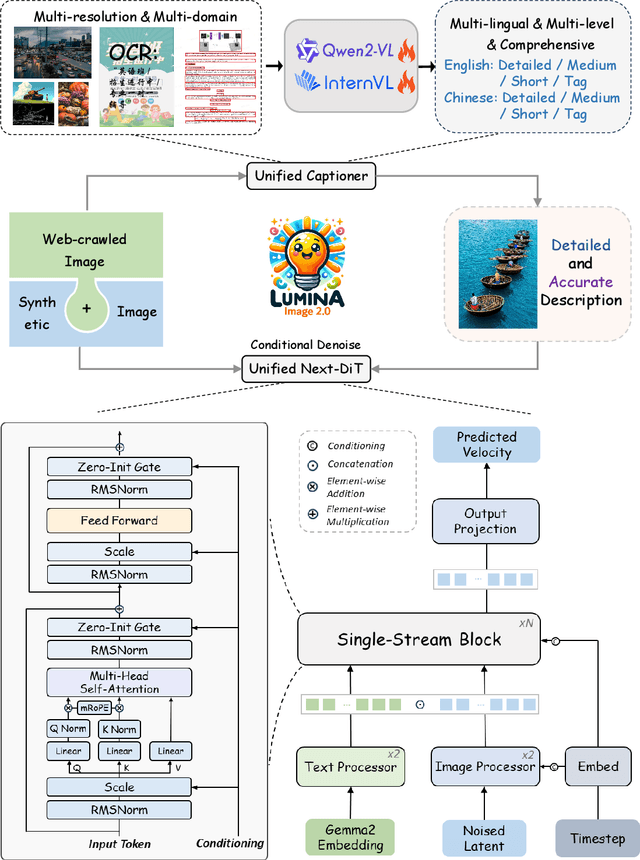

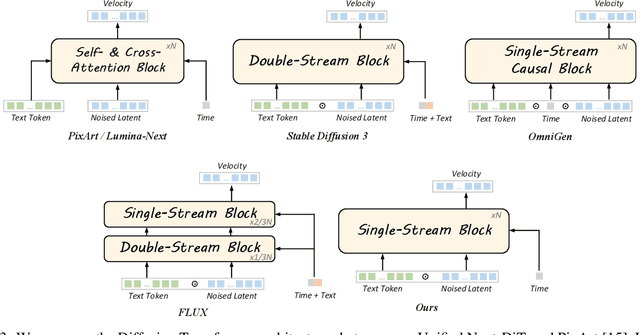
We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
3DAxisPrompt: Promoting the 3D Grounding and Reasoning in GPT-4o
Mar 17, 2025Multimodal Large Language Models (MLLMs) exhibit impressive capabilities across a variety of tasks, especially when equipped with carefully designed visual prompts. However, existing studies primarily focus on logical reasoning and visual understanding, while the capability of MLLMs to operate effectively in 3D vision remains an ongoing area of exploration. In this paper, we introduce a novel visual prompting method, called 3DAxisPrompt, to elicit the 3D understanding capabilities of MLLMs in real-world scenes. More specifically, our method leverages the 3D coordinate axis and masks generated from the Segment Anything Model (SAM) to provide explicit geometric priors to MLLMs and then extend their impressive 2D grounding and reasoning ability to real-world 3D scenarios. Besides, we first provide a thorough investigation of the potential visual prompting formats and conclude our findings to reveal the potential and limits of 3D understanding capabilities in GPT-4o, as a representative of MLLMs. Finally, we build evaluation environments with four datasets, i.e., ScanRefer, ScanNet, FMB, and nuScene datasets, covering various 3D tasks. Based on this, we conduct extensive quantitative and qualitative experiments, which demonstrate the effectiveness of the proposed method. Overall, our study reveals that MLLMs, with the help of 3DAxisPrompt, can effectively perceive an object's 3D position in real-world scenarios. Nevertheless, a single prompt engineering approach does not consistently achieve the best outcomes for all 3D tasks. This study highlights the feasibility of leveraging MLLMs for 3D vision grounding/reasoning with prompt engineering techniques.
TIDE : Temporal-Aware Sparse Autoencoders for Interpretable Diffusion Transformers in Image Generation
Mar 10, 2025Diffusion Transformers (DiTs) are a powerful yet underexplored class of generative models compared to U-Net-based diffusion models. To bridge this gap, we introduce TIDE (Temporal-aware Sparse Autoencoders for Interpretable Diffusion transformErs), a novel framework that enhances temporal reconstruction within DiT activation layers across denoising steps. TIDE employs Sparse Autoencoders (SAEs) with a sparse bottleneck layer to extract interpretable and hierarchical features, revealing that diffusion models inherently learn hierarchical features at multiple levels (e.g., 3D, semantic, class) during generative pre-training. Our approach achieves state-of-the-art reconstruction performance, with a mean squared error (MSE) of 1e-3 and a cosine similarity of 0.97, demonstrating superior accuracy in capturing activation dynamics along the denoising trajectory. Beyond interpretability, we showcase TIDE's potential in downstream applications such as sparse activation-guided image editing and style transfer, enabling improved controllability for generative systems. By providing a comprehensive training and evaluation protocol tailored for DiTs, TIDE contributes to developing more interpretable, transparent, and trustworthy generative models.
CAML: Collaborative Auxiliary Modality Learning for Multi-Agent Systems
Feb 25, 2025Multi-modality learning has become a crucial technique for improving the performance of machine learning applications across domains such as autonomous driving, robotics, and perception systems. While existing frameworks such as Auxiliary Modality Learning (AML) effectively utilize multiple data sources during training and enable inference with reduced modalities, they primarily operate in a single-agent context. This limitation is particularly critical in dynamic environments, such as connected autonomous vehicles (CAV), where incomplete data coverage can lead to decision-making blind spots. To address these challenges, we propose Collaborative Auxiliary Modality Learning ($\textbf{CAML}$), a novel multi-agent multi-modality framework that enables agents to collaborate and share multimodal data during training while allowing inference with reduced modalities per agent during testing. We systematically analyze the effectiveness of $\textbf{CAML}$ from the perspective of uncertainty reduction and data coverage, providing theoretical insights into its advantages over AML. Experimental results in collaborative decision-making for CAV in accident-prone scenarios demonstrate that \ours~achieves up to a ${\bf 58.13}\%$ improvement in accident detection. Additionally, we validate $\textbf{CAML}$ on real-world aerial-ground robot data for collaborative semantic segmentation, achieving up to a ${\bf 10.61}\%$ improvement in mIoU.
AUKT: Adaptive Uncertainty-Guided Knowledge Transfer with Conformal Prediction
Feb 25, 2025Knowledge transfer between teacher and student models has proven effective across various machine learning applications. However, challenges arise when the teacher's predictions are noisy, or the data domain during student training shifts from the teacher's pretraining data. In such scenarios, blindly relying on the teacher's predictions can lead to suboptimal knowledge transfer. To address these challenges, we propose a novel and universal framework, Adaptive Uncertainty-guided Knowledge Transfer ($\textbf{AUKT}$), which leverages Conformal Prediction (CP) to dynamically adjust the student's reliance on the teacher's guidance based on the teacher's prediction uncertainty. CP is a distribution-free, model-agnostic approach that provides reliable prediction sets with statistical coverage guarantees and minimal computational overhead. This adaptive mechanism mitigates the risk of learning undesirable or incorrect knowledge. We validate the proposed framework across diverse applications, including image classification, imitation-guided reinforcement learning, and autonomous driving. Experimental results consistently demonstrate that our approach improves performance, robustness and transferability, offering a promising direction for enhanced knowledge transfer in real-world applications.
Bandwidth-Adaptive Spatiotemporal Correspondence Identification for Collaborative Perception
Feb 17, 2025Correspondence identification (CoID) is an essential capability in multi-robot collaborative perception, which enables a group of robots to consistently refer to the same objects within their respective fields of view. In real-world applications, such as connected autonomous driving, vehicles face challenges in directly sharing raw observations due to limited communication bandwidth. In order to address this challenge, we propose a novel approach for bandwidth-adaptive spatiotemporal CoID in collaborative perception. This approach allows robots to progressively select partial spatiotemporal observations and share with others, while adapting to communication constraints that dynamically change over time. We evaluate our approach across various scenarios in connected autonomous driving simulations. Experimental results validate that our approach enables CoID and adapts to dynamic communication bandwidth changes. In addition, our approach achieves 8%-56% overall improvements in terms of covisible object retrieval for CoID and data sharing efficiency, which outperforms previous techniques and achieves the state-of-the-art performance. More information is available at: https://gaopeng5.github.io/acoid.