 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Towards Domain Generalization in Object Detection
Mar 27, 2022
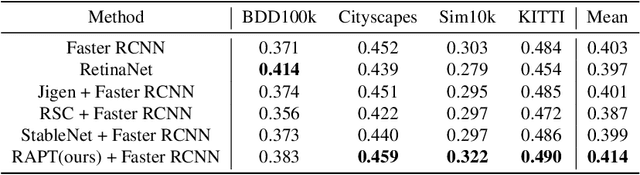
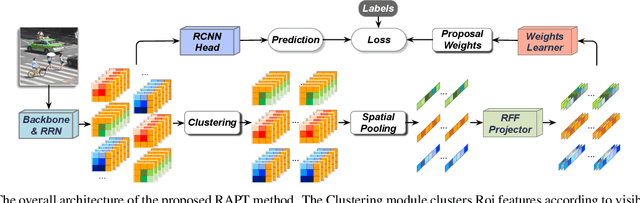
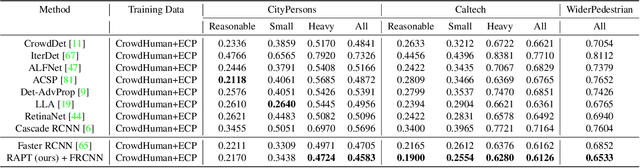
Despite the striking performance achieved by modern detectors when training and test data are sampled from the same or similar distribution, the generalization ability of detectors under unknown distribution shifts remains hardly studied. Recently several works discussed the detectors' adaptation ability to a specific target domain which are not readily applicable in real-world applications since detectors may encounter various environments or situations while pre-collecting all of them before training is inconceivable. In this paper, we study the critical problem, domain generalization in object detection (DGOD), where detectors are trained with source domains and evaluated on unknown target domains. To thoroughly evaluate detectors under unknown distribution shifts, we formulate the DGOD problem and propose a comprehensive evaluation benchmark to fill the vacancy. Moreover, we propose a novel method named Region Aware Proposal reweighTing (RAPT) to eliminate dependence within RoI features. Extensive experiments demonstrate that current DG methods fail to address the DGOD problem and our method outperforms other state-of-the-art counterparts.
ZIN: When and How to Learn Invariance by Environment Inference?
Mar 11, 2022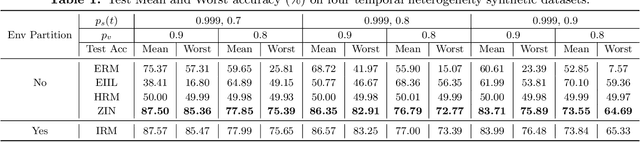
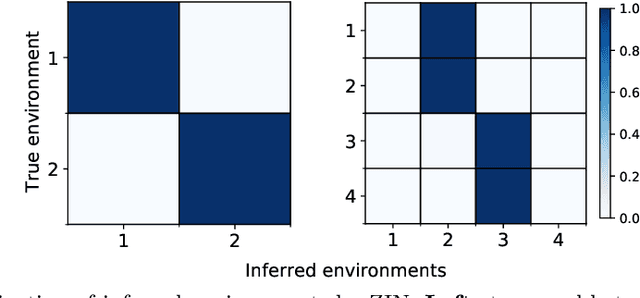
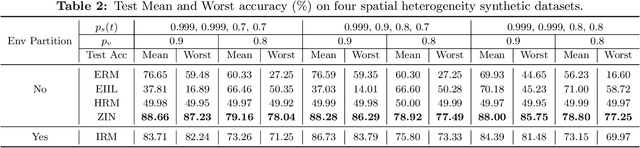
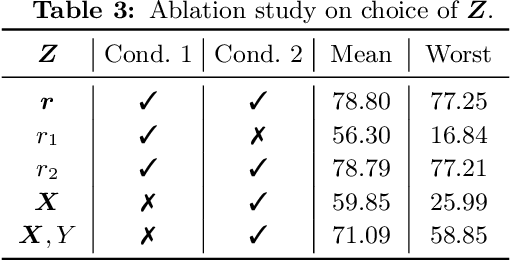
It is commonplace to encounter heterogeneous data, of which some aspects of the data distribution may vary but the underlying causal mechanisms remain constant. When data are divided into distinct environments according to the heterogeneity, recent invariant learning methods have proposed to learn robust and invariant models based on this environment partition. It is hence tempting to utilize the inherent heterogeneity even when environment partition is not provided. Unfortunately, in this work, we show that learning invariant features under this circumstance is fundamentally impossible without further inductive biases or additional information. Then, we propose a framework to jointly learn environment partition and invariant representation, assisted by additional auxiliary information. We derive sufficient and necessary conditions for our framework to provably identify invariant features under a fairly general setting. Experimental results on both synthetic and real world datasets validate our analysis and demonstrate an improved performance of the proposed framework over existing methods. Finally, our results also raise the need of making the role of inductive biases more explicit in future works, when considering learning invariant models without environment partition.
CausPref: Causal Preference Learning for Out-of-Distribution Recommendation
Feb 09, 2022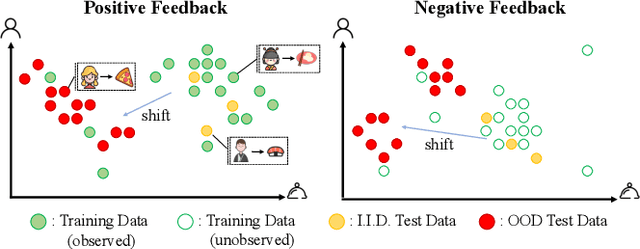
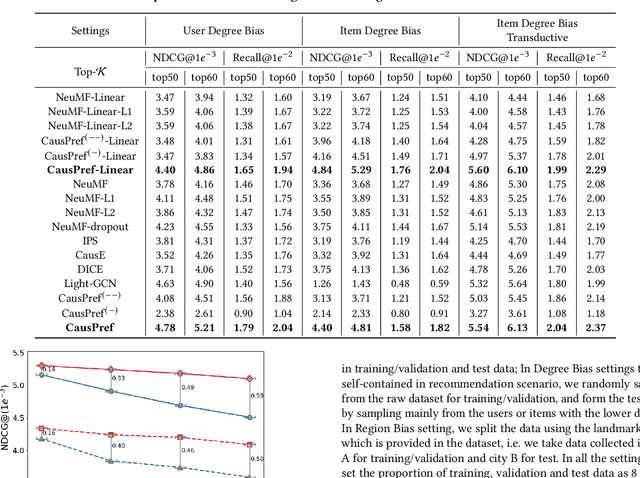
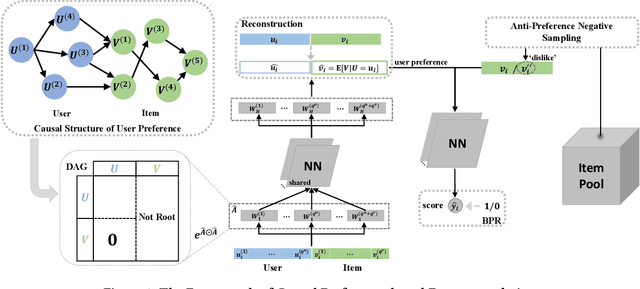
In spite of the tremendous development of recommender system owing to the progressive capability of machine learning recently, the current recommender system is still vulnerable to the distribution shift of users and items in realistic scenarios, leading to the sharp decline of performance in testing environments. It is even more severe in many common applications where only the implicit feedback from sparse data is available. Hence, it is crucial to promote the performance stability of recommendation method in different environments. In this work, we first make a thorough analysis of implicit recommendation problem from the viewpoint of out-of-distribution (OOD) generalization. Then under the guidance of our theoretical analysis, we propose to incorporate the recommendation-specific DAG learner into a novel causal preference-based recommendation framework named CausPref, mainly consisting of causal learning of invariant user preference and anti-preference negative sampling to deal with implicit feedback. Extensive experimental results from real-world datasets clearly demonstrate that our approach surpasses the benchmark models significantly under types of out-of-distribution settings, and show its impressive interpretability.
Regulatory Instruments for Fair Personalized Pricing
Feb 09, 2022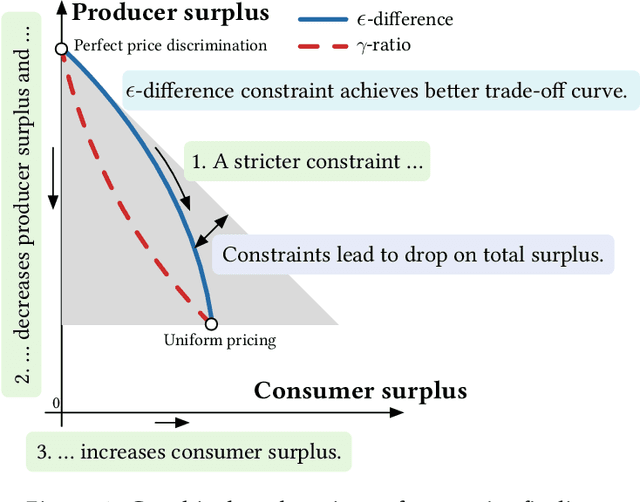

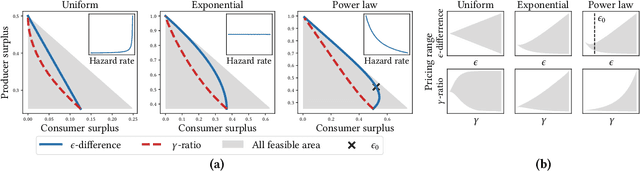
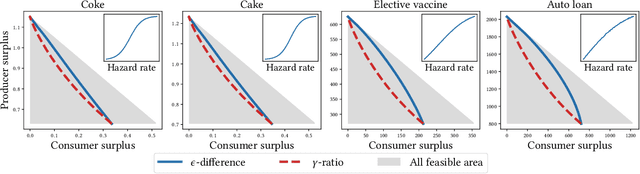
Personalized pricing is a business strategy to charge different prices to individual consumers based on their characteristics and behaviors. It has become common practice in many industries nowadays due to the availability of a growing amount of high granular consumer data. The discriminatory nature of personalized pricing has triggered heated debates among policymakers and academics on how to design regulation policies to balance market efficiency and equity. In this paper, we propose two sound policy instruments, i.e., capping the range of the personalized prices or their ratios. We investigate the optimal pricing strategy of a profit-maximizing monopoly under both regulatory constraints and the impact of imposing them on consumer surplus, producer surplus, and social welfare. We theoretically prove that both proposed constraints can help balance consumer surplus and producer surplus at the expense of total surplus for common demand distributions, such as uniform, logistic, and exponential distributions. Experiments on both simulation and real-world datasets demonstrate the correctness of these theoretical results. Our findings and insights shed light on regulatory policy design for the increasingly monopolized business in the digital era.
Causal Disentanglement for Semantics-Aware Intent Learning in Recommendation
Feb 05, 2022

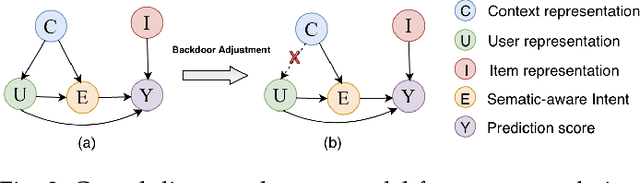
Traditional recommendation models trained on observational interaction data have generated large impacts in a wide range of applications, it faces bias problems that cover users' true intent and thus deteriorate the recommendation effectiveness. Existing methods tracks this problem as eliminating bias for the robust recommendation, e.g., by re-weighting training samples or learning disentangled representation. The disentangled representation methods as the state-of-the-art eliminate bias through revealing cause-effect of the bias generation. However, how to design the semantics-aware and unbiased representation for users true intents is largely unexplored. To bridge the gap, we are the first to propose an unbiased and semantics-aware disentanglement learning called CaDSI (Causal Disentanglement for Semantics-Aware Intent Learning) from a causal perspective. Particularly, CaDSI explicitly models the causal relations underlying recommendation task, and thus produces semantics-aware representations via disentangling users true intents aware of specific item context. Moreover, the causal intervention mechanism is designed to eliminate confounding bias stemmed from context information, which further to align the semantics-aware representation with users true intent. Extensive experiments and case studies both validate the robustness and interpretability of our proposed model.
Revisiting Transformation Invariant Geometric Deep Learning: Are Initial Representations All You Need?
Dec 23, 2021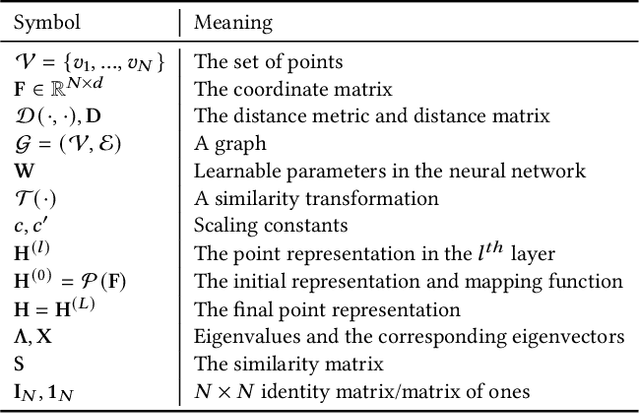
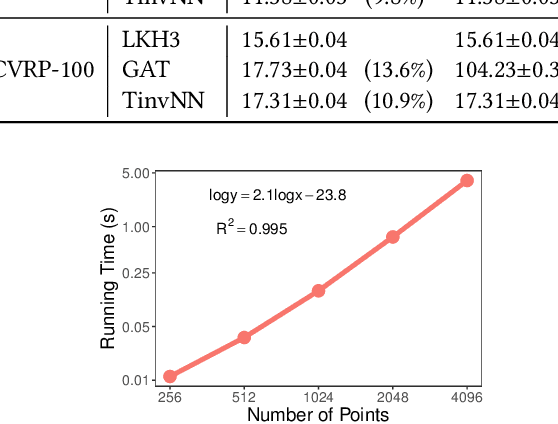
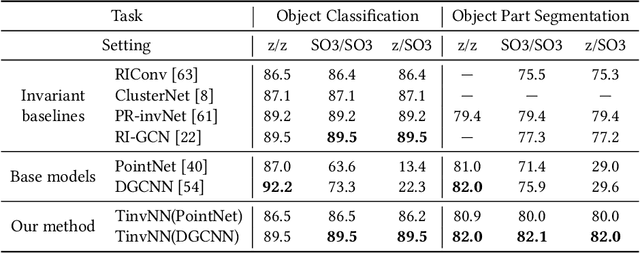
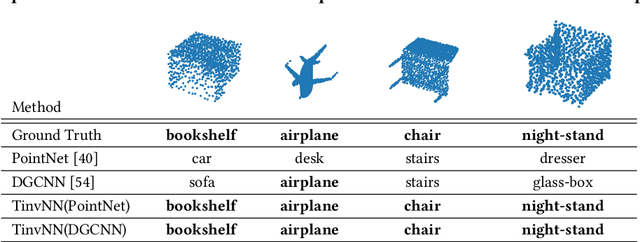
Geometric deep learning, i.e., designing neural networks to handle the ubiquitous geometric data such as point clouds and graphs, have achieved great successes in the last decade. One critical inductive bias is that the model can maintain invariance towards various transformations such as translation, rotation, and scaling. The existing graph neural network (GNN) approaches can only maintain permutation-invariance, failing to guarantee invariance with respect to other transformations. Besides GNNs, other works design sophisticated transformation-invariant layers, which are computationally expensive and difficult to be extended. To solve this problem, we revisit why the existing neural networks cannot maintain transformation invariance when handling geometric data. Our findings show that transformation-invariant and distance-preserving initial representations are sufficient to achieve transformation invariance rather than needing sophisticated neural layer designs. Motivated by these findings, we propose Transformation Invariant Neural Networks (TinvNN), a straightforward and general framework for geometric data. Specifically, we realize transformation-invariant and distance-preserving initial point representations by modifying multi-dimensional scaling before feeding the representations into neural networks. We prove that TinvNN can strictly guarantee transformation invariance, being general and flexible enough to be combined with the existing neural networks. Extensive experimental results on point cloud analysis and combinatorial optimization demonstrate the effectiveness and general applicability of our proposed method. Based on the experimental results, we advocate that TinvNN should be considered a new starting point and an essential baseline for further studies of transformation-invariant geometric deep learning.
Generalizing Graph Neural Networks on Out-Of-Distribution Graphs
Nov 23, 2021
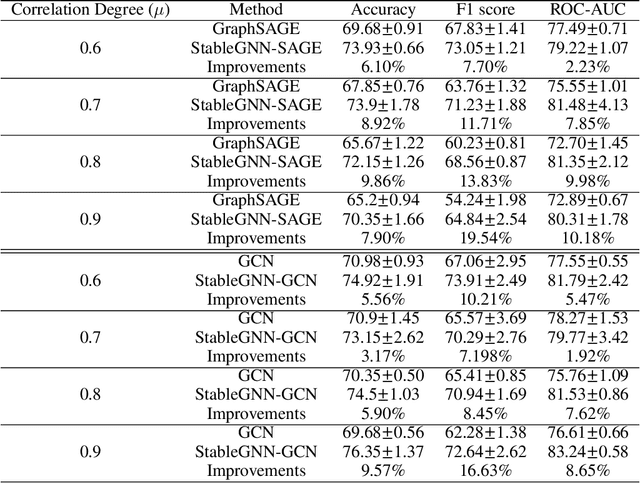
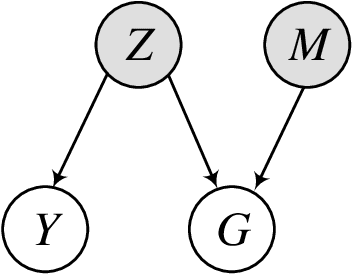
Graph Neural Networks (GNNs) are proposed without considering the agnostic distribution shifts between training and testing graphs, inducing the degeneration of the generalization ability of GNNs on Out-Of-Distribution (OOD) settings. The fundamental reason for such degeneration is that most GNNs are developed based on the I.I.D hypothesis. In such a setting, GNNs tend to exploit subtle statistical correlations existing in the training set for predictions, even though it is a spurious correlation. However, such spurious correlations may change in testing environments, leading to the failure of GNNs. Therefore, eliminating the impact of spurious correlations is crucial for stable GNNs. To this end, we propose a general causal representation framework, called StableGNN. The main idea is to extract high-level representations from graph data first and resort to the distinguishing ability of causal inference to help the model get rid of spurious correlations. Particularly, we exploit a graph pooling layer to extract subgraph-based representations as high-level representations. Furthermore, we propose a causal variable distinguishing regularizer to correct the biased training distribution. Hence, GNNs would concentrate more on the stable correlations. Extensive experiments on both synthetic and real-world OOD graph datasets well verify the effectiveness, flexibility and interpretability of the proposed framework.
Why Stable Learning Works? A Theory of Covariate Shift Generalization
Nov 03, 2021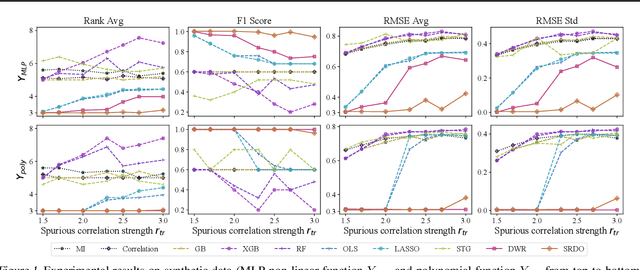
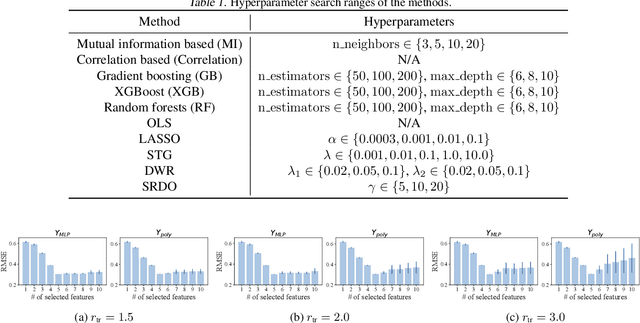
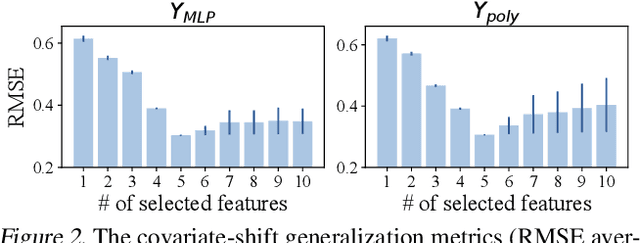
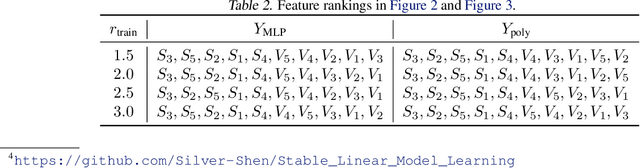
Covariate shift generalization, a typical case in out-of-distribution (OOD) generalization, requires a good performance on the unknown testing distribution, which varies from the accessible training distribution in the form of covariate shift. Recently, stable learning algorithms have shown empirical effectiveness to deal with covariate shift generalization on several learning models involving regression algorithms and deep neural networks. However, the theoretical explanations for such effectiveness are still missing. In this paper, we take a step further towards the theoretical analysis of stable learning algorithms by explaining them as feature selection processes. We first specify a set of variables, named minimal stable variable set, that is minimal and optimal to deal with covariate shift generalization for common loss functions, including the mean squared loss and binary cross entropy loss. Then we prove that under ideal conditions, stable learning algorithms could identify the variables in this set. Further analysis on asymptotic properties and error propagation are also provided. These theories shed light on why stable learning works for covariate shift generalization.
Conditional Attention Networks for Distilling Knowledge Graphs in Recommendation
Nov 03, 2021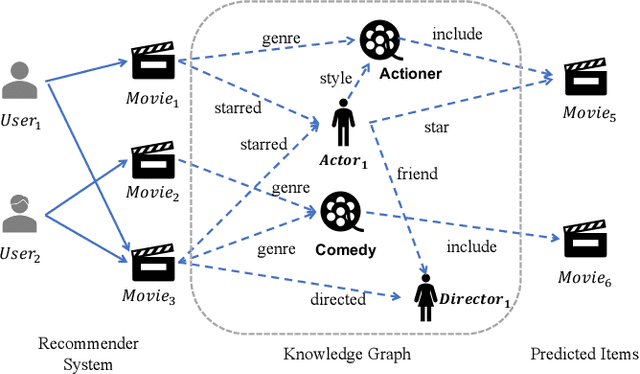
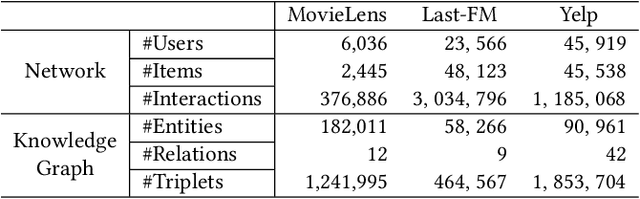
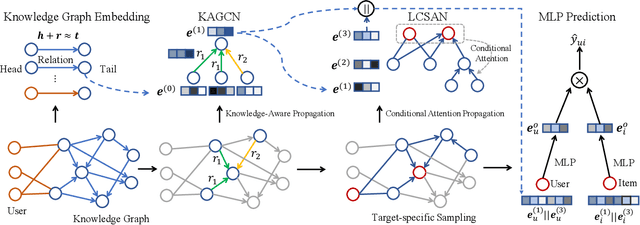
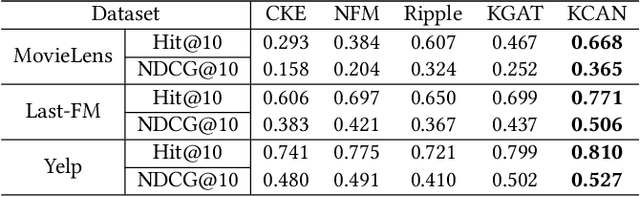
Knowledge graph is generally incorporated into recommender systems to improve overall performance. Due to the generalization and scale of the knowledge graph, most knowledge relationships are not helpful for a target user-item prediction. To exploit the knowledge graph to capture target-specific knowledge relationships in recommender systems, we need to distill the knowledge graph to reserve the useful information and refine the knowledge to capture the users' preferences. To address the issues, we propose Knowledge-aware Conditional Attention Networks (KCAN), which is an end-to-end model to incorporate knowledge graph into a recommender system. Specifically, we use a knowledge-aware attention propagation manner to obtain the node representation first, which captures the global semantic similarity on the user-item network and the knowledge graph. Then given a target, i.e., a user-item pair, we automatically distill the knowledge graph into the target-specific subgraph based on the knowledge-aware attention. Afterward, by applying a conditional attention aggregation on the subgraph, we refine the knowledge graph to obtain target-specific node representations. Therefore, we can gain both representability and personalization to achieve overall performance. Experimental results on real-world datasets demonstrate the effectiveness of our framework over the state-of-the-art algorithms.