 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-aware Selective Prompting for Hallucination Mitigation in Large Vision-Language Models
May 27, 2026Prompt-based verification is widely used to mitigate hallucinations in large vision-language models (LVLMs), yet when it helps remains poorly understood. We systematically study verification prompting across two representative LVLM architectures and hallucination benchmarks, and find that it is a risk-bearing intervention: its corrections increase with input difficulty, while newly introduced errors persist across difficulty levels. As a result, always-on prompting helps on hard inputs but offers little benefit -- and can harm -- easier ones. Our analysis further shows that this behavior is associated with a conservative output shift. Verification prompts redistribute attention from visual tokens toward instruction tokens and induce a distinct middle-layer entropy pattern absent in a neutral-prompt control, suggesting instruction-conditioned attention redistribution rather than uniformly improved visual grounding. Motivated by this input-dependent risk, we propose Risk-aware Selective Prompting (RSP), a training-free approach that uses pre-generation uncertainty signals to trigger verification selectively. RSP mitigates the degradation of always-on prompting while preserving baseline performance, and reveals that effective selection signals vary across architectures.
CLLMFS: A Contrastive Learning enhanced Large Language Model Framework for Few-Shot Named Entity Recognition
Aug 23, 2024Few-shot Named Entity Recognition (NER), the task of identifying named entities with only a limited amount of labeled data, has gained increasing significance in natural language processing. While existing methodologies have shown some effectiveness, such as enriching label semantics through various prompting modes or employing metric learning techniques, their performance exhibits limited robustness across diverse domains due to the lack of rich knowledge in their pre-trained models. To address this issue, we propose CLLMFS, a Contrastive Learning enhanced Large Language Model (LLM) Framework for Few-Shot Named Entity Recognition, achieving promising results with limited training data. Considering the impact of LLM's internal representations on downstream tasks, CLLMFS integrates Low-Rank Adaptation (LoRA) and contrastive learning mechanisms specifically tailored for few-shot NER. By enhancing the model's internal representations, CLLMFS effectively improves both entity boundary awareness ability and entity recognition accuracy. Our method has achieved state-of-the-art performance improvements on F1-score ranging from 2.58\% to 97.74\% over existing best-performing methods across several recognized benchmarks. Furthermore, through cross-domain NER experiments conducted on multiple datasets, we have further validated the robust generalization capability of our method. Our code will be released in the near future.
Video Generation with Consistency Tuning
Mar 11, 2024


Currently, various studies have been exploring generation of long videos. However, the generated frames in these videos often exhibit jitter and noise. Therefore, in order to generate the videos without these noise, we propose a novel framework composed of four modules: separate tuning module, average fusion module, combined tuning module, and inter-frame consistency module. By applying our newly proposed modules subsequently, the consistency of the background and foreground in each video frames is optimized. Besides, the experimental results demonstrate that videos generated by our method exhibit a high quality in comparison of the state-of-the-art methods.
Product Ranking for Revenue Maximization with Multiple Purchases
Oct 15, 2022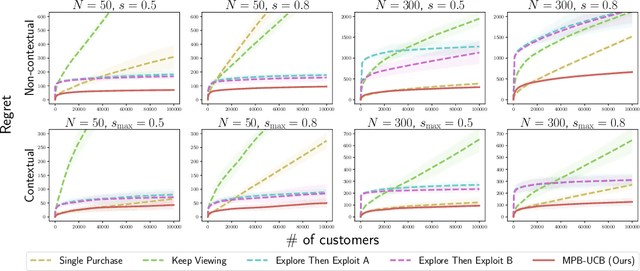
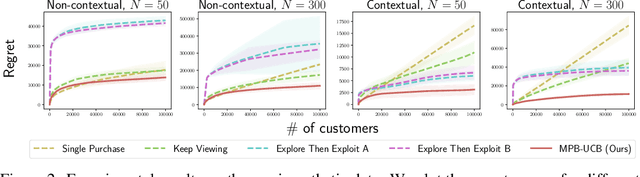
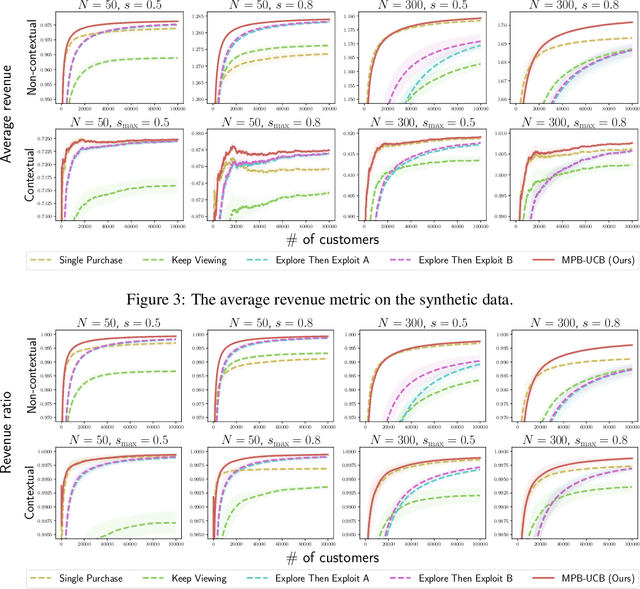
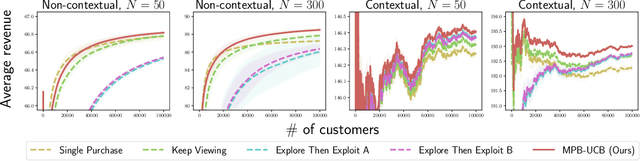
Product ranking is the core problem for revenue-maximizing online retailers. To design proper product ranking algorithms, various consumer choice models are proposed to characterize the consumers' behaviors when they are provided with a list of products. However, existing works assume that each consumer purchases at most one product or will keep viewing the product list after purchasing a product, which does not agree with the common practice in real scenarios. In this paper, we assume that each consumer can purchase multiple products at will. To model consumers' willingness to view and purchase, we set a random attention span and purchase budget, which determines the maximal amount of products that he/she views and purchases, respectively. Under this setting, we first design an optimal ranking policy when the online retailer can precisely model consumers' behaviors. Based on the policy, we further develop the Multiple-Purchase-with-Budget UCB (MPB-UCB) algorithms with $\~O(\sqrt{T})$ regret that estimate consumers' behaviors and maximize revenue simultaneously in online settings. Experiments on both synthetic and semi-synthetic datasets prove the effectiveness of the proposed algorithms.
CausPref: Causal Preference Learning for Out-of-Distribution Recommendation
Feb 09, 2022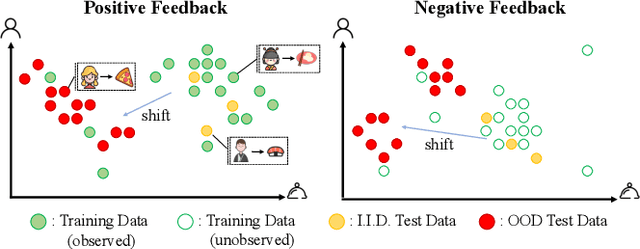
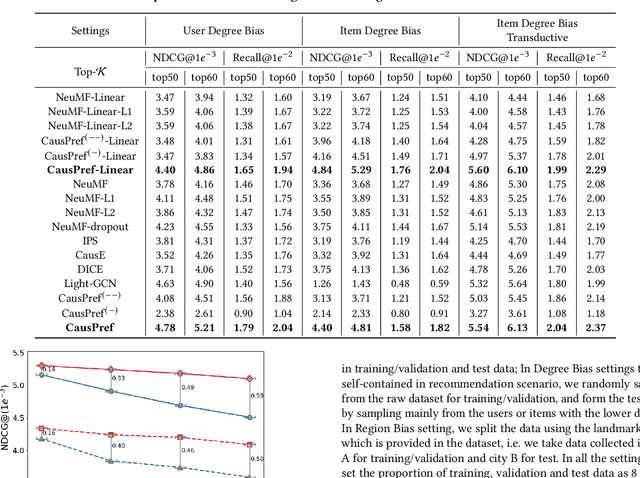
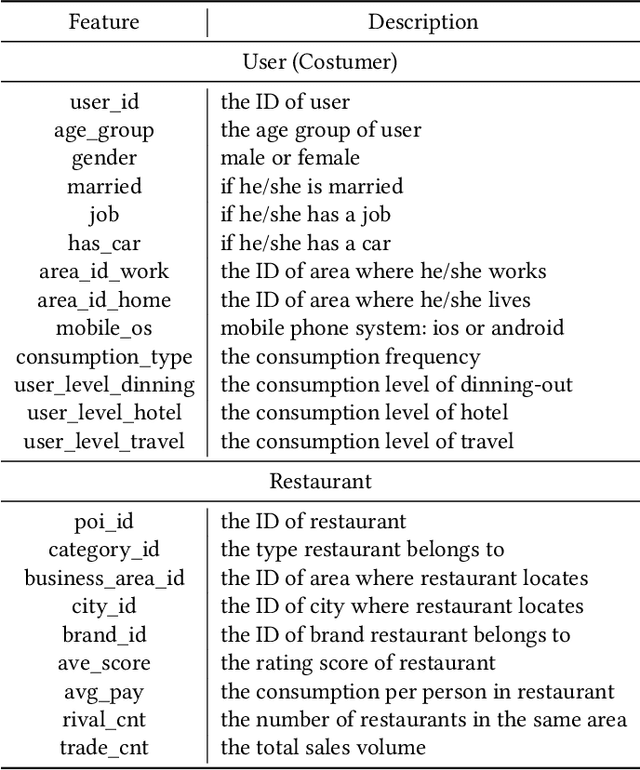
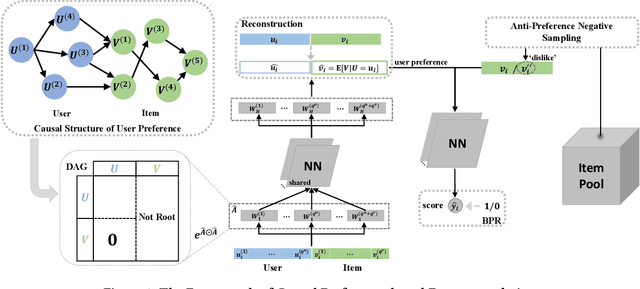
In spite of the tremendous development of recommender system owing to the progressive capability of machine learning recently, the current recommender system is still vulnerable to the distribution shift of users and items in realistic scenarios, leading to the sharp decline of performance in testing environments. It is even more severe in many common applications where only the implicit feedback from sparse data is available. Hence, it is crucial to promote the performance stability of recommendation method in different environments. In this work, we first make a thorough analysis of implicit recommendation problem from the viewpoint of out-of-distribution (OOD) generalization. Then under the guidance of our theoretical analysis, we propose to incorporate the recommendation-specific DAG learner into a novel causal preference-based recommendation framework named CausPref, mainly consisting of causal learning of invariant user preference and anti-preference negative sampling to deal with implicit feedback. Extensive experimental results from real-world datasets clearly demonstrate that our approach surpasses the benchmark models significantly under types of out-of-distribution settings, and show its impressive interpretability.
CANS-Net: Context-Aware Non-Successive Modeling Network for Next Point-of-Interest Recommendation
Apr 06, 2021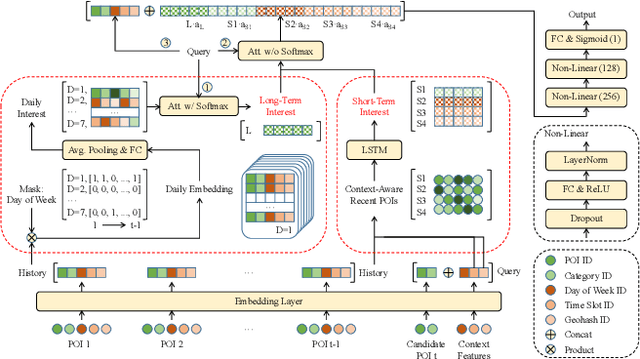
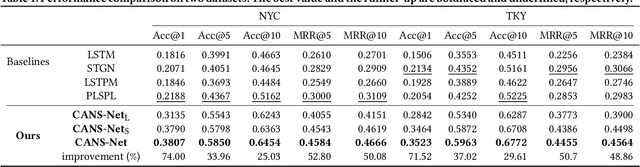
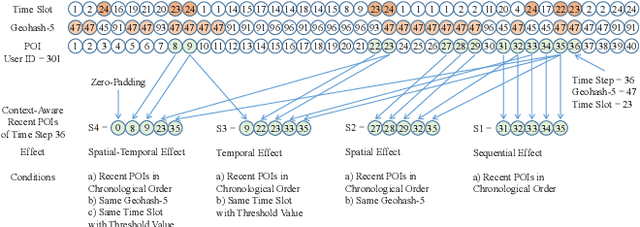
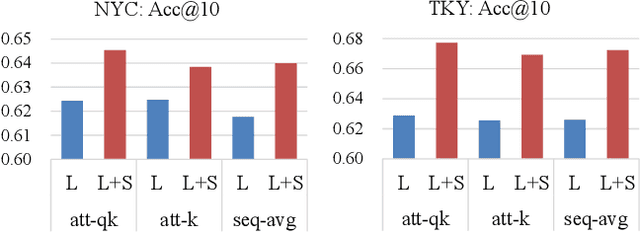
Point-of-Interest (POI) recommendation is an important task in location-based social networks. It facilitates the sharing between users and locations. Recently, researchers tend to recommend POIs by long- and short-term interests. However, existing models are mostly based on sequential modeling of successive POIs to capture transitional regularities. A few works try to acquire user's mobility periodicity or POI's geographical influence, but they omit some other spatial-temporal factors. To this end, we propose to jointly model various spatial-temporal factors by context-aware non-successive modeling. In the long-term module, we split user's all historical check-ins into seven sequences by day of week to obtain daily interest, then we combine them by attention. This will capture temporal effect. In the short-term module, we construct four short-term sequences to acquire sequential, spatial, temporal, and spatial-temporal effects, respectively. Attention of interest-level is used to combine all factors and interests. Experiments on two real-world datasets demonstrate the state-of-the-art performance of our method.