 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025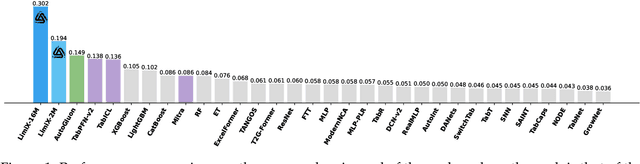
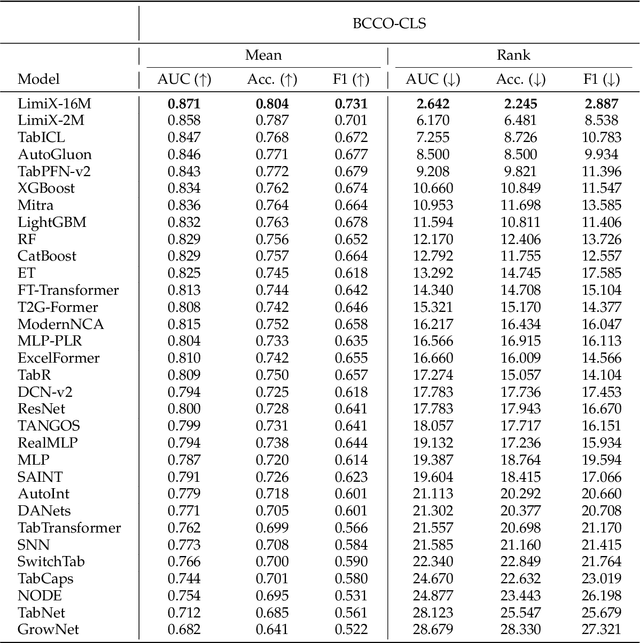
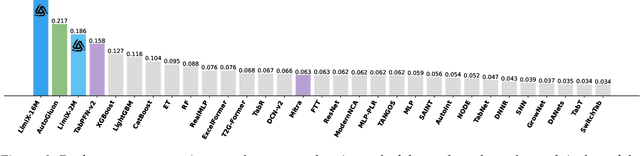
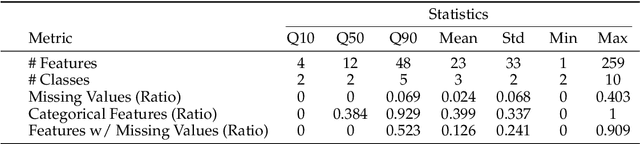
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Graph Fairness Learning under Distribution Shifts
Jan 30, 2024



Graph neural networks (GNNs) have achieved remarkable performance on graph-structured data. However, GNNs may inherit prejudice from the training data and make discriminatory predictions based on sensitive attributes, such as gender and race. Recently, there has been an increasing interest in ensuring fairness on GNNs, but all of them are under the assumption that the training and testing data are under the same distribution, i.e., training data and testing data are from the same graph. Will graph fairness performance decrease under distribution shifts? How does distribution shifts affect graph fairness learning? All these open questions are largely unexplored from a theoretical perspective. To answer these questions, we first theoretically identify the factors that determine bias on a graph. Subsequently, we explore the factors influencing fairness on testing graphs, with a noteworthy factor being the representation distances of certain groups between the training and testing graph. Motivated by our theoretical analysis, we propose our framework FatraGNN. Specifically, to guarantee fairness performance on unknown testing graphs, we propose a graph generator to produce numerous graphs with significant bias and under different distributions. Then we minimize the representation distances for each certain group between the training graph and generated graphs. This empowers our model to achieve high classification and fairness performance even on generated graphs with significant bias, thereby effectively handling unknown testing graphs. Experiments on real-world and semi-synthetic datasets demonstrate the effectiveness of our model in terms of both accuracy and fairness.
Graph Contrastive Invariant Learning from the Causal Perspective
Jan 23, 2024



Graph contrastive learning (GCL), learning the node representation by contrasting two augmented graphs in a self-supervised way, has attracted considerable attention. GCL is usually believed to learn the invariant representation. However, does this understanding always hold in practice? In this paper, we first study GCL from the perspective of causality. By analyzing GCL with the structural causal model (SCM), we discover that traditional GCL may not well learn the invariant representations due to the non-causal information contained in the graph. How can we fix it and encourage the current GCL to learn better invariant representations? The SCM offers two requirements and motives us to propose a novel GCL method. Particularly, we introduce the spectral graph augmentation to simulate the intervention upon non-causal factors. Then we design the invariance objective and independence objective to better capture the causal factors. Specifically, (i) the invariance objective encourages the encoder to capture the invariant information contained in causal variables, and (ii) the independence objective aims to reduce the influence of confounders on the causal variables. Experimental results demonstrate the effectiveness of our approach on node classification tasks.
Directed Acyclic Graph Structure Learning from Dynamic Graphs
Nov 30, 2022



Estimating the structure of directed acyclic graphs (DAGs) of features (variables) plays a vital role in revealing the latent data generation process and providing causal insights in various applications. Although there have been many studies on structure learning with various types of data, the structure learning on the dynamic graph has not been explored yet, and thus we study the learning problem of node feature generation mechanism on such ubiquitous dynamic graph data. In a dynamic graph, we propose to simultaneously estimate contemporaneous relationships and time-lagged interaction relationships between the node features. These two kinds of relationships form a DAG, which could effectively characterize the feature generation process in a concise way. To learn such a DAG, we cast the learning problem as a continuous score-based optimization problem, which consists of a differentiable score function to measure the validity of the learned DAGs and a smooth acyclicity constraint to ensure the acyclicity of the learned DAGs. These two components are translated into an unconstraint augmented Lagrangian objective which could be minimized by mature continuous optimization techniques. The resulting algorithm, named GraphNOTEARS, outperforms baselines on simulated data across a wide range of settings that may encounter in real-world applications. We also apply the proposed approach on two dynamic graphs constructed from the real-world Yelp dataset, demonstrating our method could learn the connections between node features, which conforms with the domain knowledge.
Debiasing Graph Neural Networks via Learning Disentangled Causal Substructure
Sep 28, 2022
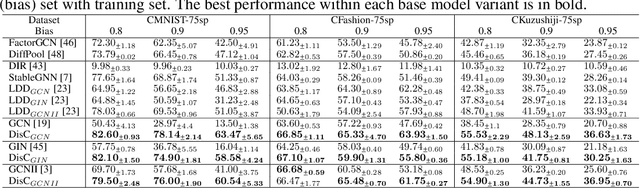
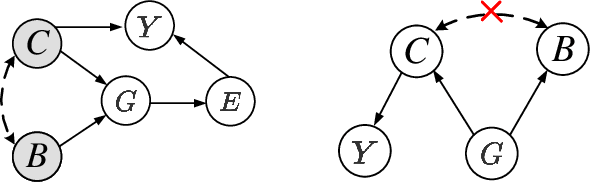
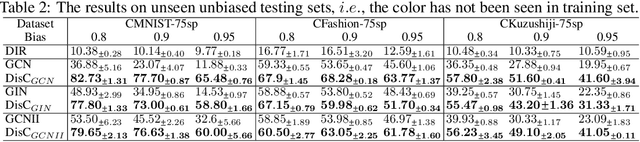
Most Graph Neural Networks (GNNs) predict the labels of unseen graphs by learning the correlation between the input graphs and labels. However, by presenting a graph classification investigation on the training graphs with severe bias, surprisingly, we discover that GNNs always tend to explore the spurious correlations to make decision, even if the causal correlation always exists. This implies that existing GNNs trained on such biased datasets will suffer from poor generalization capability. By analyzing this problem in a causal view, we find that disentangling and decorrelating the causal and bias latent variables from the biased graphs are both crucial for debiasing. Inspiring by this, we propose a general disentangled GNN framework to learn the causal substructure and bias substructure, respectively. Particularly, we design a parameterized edge mask generator to explicitly split the input graph into causal and bias subgraphs. Then two GNN modules supervised by causal/bias-aware loss functions respectively are trained to encode causal and bias subgraphs into their corresponding representations. With the disentangled representations, we synthesize the counterfactual unbiased training samples to further decorrelate causal and bias variables. Moreover, to better benchmark the severe bias problem, we construct three new graph datasets, which have controllable bias degrees and are easier to visualize and explain. Experimental results well demonstrate that our approach achieves superior generalization performance over existing baselines. Furthermore, owing to the learned edge mask, the proposed model has appealing interpretability and transferability. Code and data are available at: https://github.com/googlebaba/DisC.
Debiased Graph Neural Networks with Agnostic Label Selection Bias
Jan 25, 2022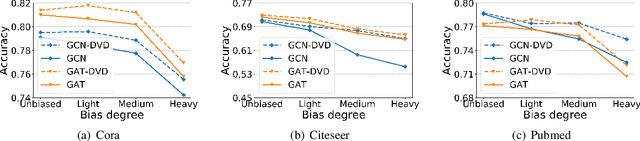
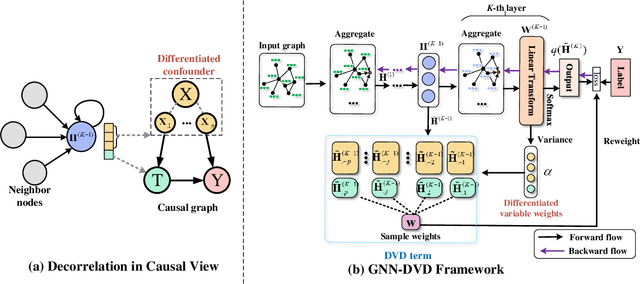
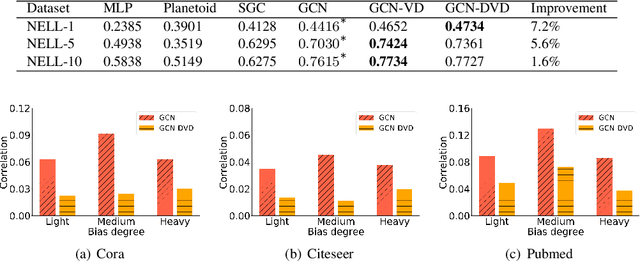
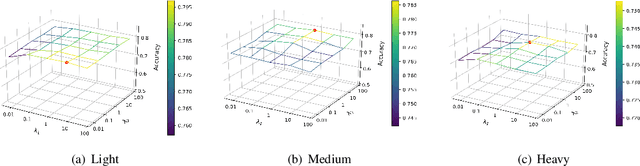
Most existing Graph Neural Networks (GNNs) are proposed without considering the selection bias in data, i.e., the inconsistent distribution between the training set with test set. In reality, the test data is not even available during the training process, making selection bias agnostic. Training GNNs with biased selected nodes leads to significant parameter estimation bias and greatly impacts the generalization ability on test nodes. In this paper, we first present an experimental investigation, which clearly shows that the selection bias drastically hinders the generalization ability of GNNs, and theoretically prove that the selection bias will cause the biased estimation on GNN parameters. Then to remove the bias in GNN estimation, we propose a novel Debiased Graph Neural Networks (DGNN) with a differentiated decorrelation regularizer. The differentiated decorrelation regularizer estimates a sample weight for each labeled node such that the spurious correlation of learned embeddings could be eliminated. We analyze the regularizer in causal view and it motivates us to differentiate the weights of the variables based on their contribution on the confounding bias. Then, these sample weights are used for reweighting GNNs to eliminate the estimation bias, thus help to improve the stability of prediction on unknown test nodes. Comprehensive experiments are conducted on several challenging graph datasets with two kinds of label selection biases. The results well verify that our proposed model outperforms the state-of-the-art methods and DGNN is a flexible framework to enhance existing GNNs.
Generalizing Graph Neural Networks on Out-Of-Distribution Graphs
Nov 23, 2021
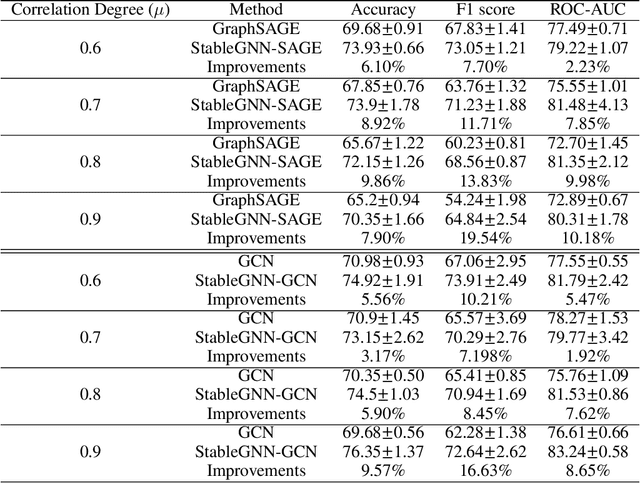
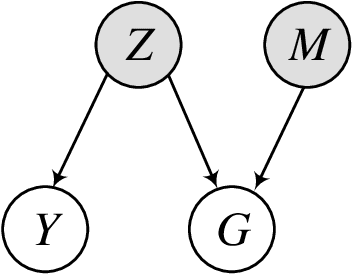
Graph Neural Networks (GNNs) are proposed without considering the agnostic distribution shifts between training and testing graphs, inducing the degeneration of the generalization ability of GNNs on Out-Of-Distribution (OOD) settings. The fundamental reason for such degeneration is that most GNNs are developed based on the I.I.D hypothesis. In such a setting, GNNs tend to exploit subtle statistical correlations existing in the training set for predictions, even though it is a spurious correlation. However, such spurious correlations may change in testing environments, leading to the failure of GNNs. Therefore, eliminating the impact of spurious correlations is crucial for stable GNNs. To this end, we propose a general causal representation framework, called StableGNN. The main idea is to extract high-level representations from graph data first and resort to the distinguishing ability of causal inference to help the model get rid of spurious correlations. Particularly, we exploit a graph pooling layer to extract subgraph-based representations as high-level representations. Furthermore, we propose a causal variable distinguishing regularizer to correct the biased training distribution. Hence, GNNs would concentrate more on the stable correlations. Extensive experiments on both synthetic and real-world OOD graph datasets well verify the effectiveness, flexibility and interpretability of the proposed framework.
A Survey on Heterogeneous Graph Embedding: Methods, Techniques, Applications and Sources
Nov 30, 2020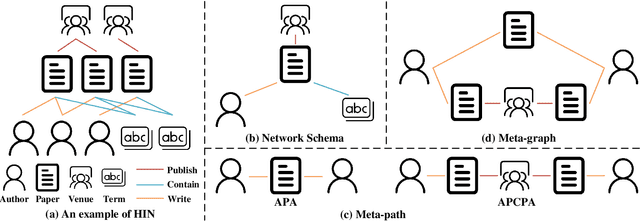

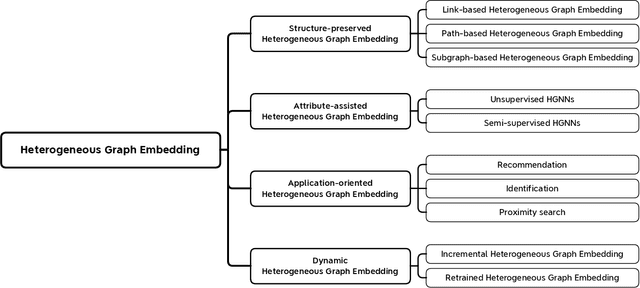
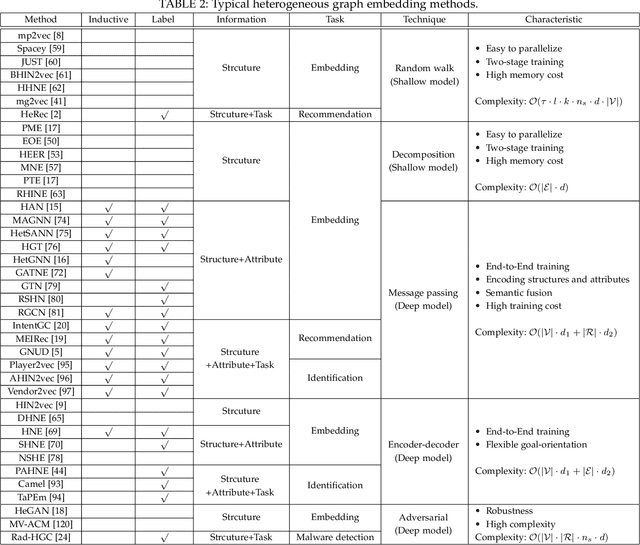
Heterogeneous graphs (HGs) also known as heterogeneous information networks have become ubiquitous in real-world scenarios; therefore, HG embedding, which aims to learn representations in a lower-dimension space while preserving the heterogeneous structures and semantics for downstream tasks (e.g., node/graph classification, node clustering, link prediction), has drawn considerable attentions in recent years. In this survey, we perform a comprehensive review of the recent development on HG embedding methods and techniques. We first introduce the basic concepts of HG and discuss the unique challenges brought by the heterogeneity for HG embedding in comparison with homogeneous graph representation learning; and then we systemically survey and categorize the state-of-the-art HG embedding methods based on the information they used in the learning process to address the challenges posed by the HG heterogeneity. In particular, for each representative HG embedding method, we provide detailed introduction and further analyze its pros and cons; meanwhile, we also explore the transformativeness and applicability of different types of HG embedding methods in the real-world industrial environments for the first time. In addition, we further present several widely deployed systems that have demonstrated the success of HG embedding techniques in resolving real-world application problems with broader impacts. To facilitate future research and applications in this area, we also summarize the open-source code, existing graph learning platforms and benchmark datasets. Finally, we explore the additional issues and challenges of HG embedding and forecast the future research directions in this field.
Decorrelated Clustering with Data Selection Bias
Jul 02, 2020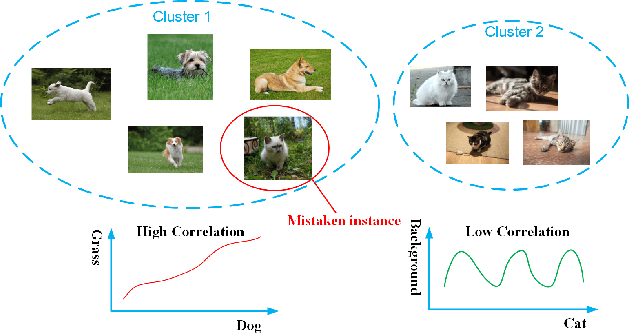
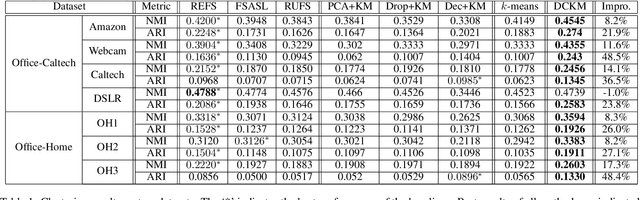
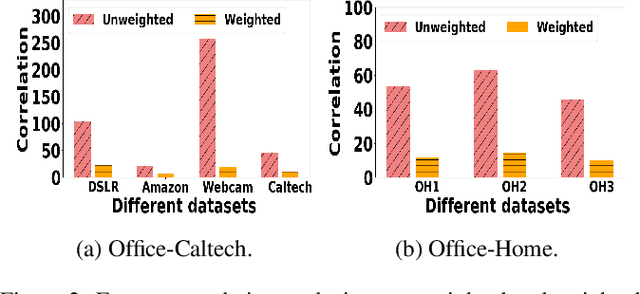
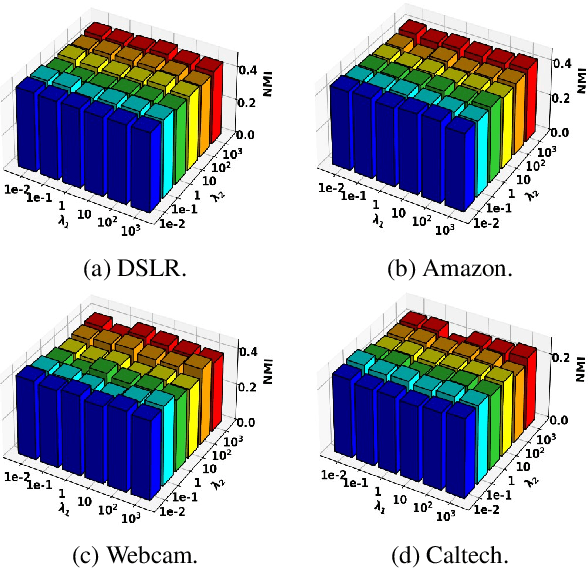
Most of existing clustering algorithms are proposed without considering the selection bias in data. In many real applications, however, one cannot guarantee the data is unbiased. Selection bias might bring the unexpected correlation between features and ignoring those unexpected correlations will hurt the performance of clustering algorithms. Therefore, how to remove those unexpected correlations induced by selection bias is extremely important yet largely unexplored for clustering. In this paper, we propose a novel Decorrelation regularized K-Means algorithm (DCKM) for clustering with data selection bias. Specifically, the decorrelation regularizer aims to learn the global sample weights which are capable of balancing the sample distribution, so as to remove unexpected correlations among features. Meanwhile, the learned weights are combined with k-means, which makes the reweighted k-means cluster on the inherent data distribution without unexpected correlation influence. Moreover, we derive the updating rules to effectively infer the parameters in DCKM. Extensive experiments results on real world datasets well demonstrate that our DCKM algorithm achieves significant performance gains, indicating the necessity of removing unexpected feature correlations induced by selection bias when clustering.