 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training
Oct 14, 2022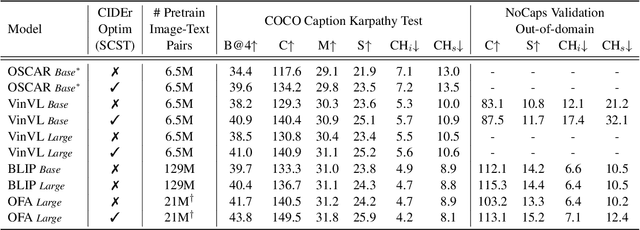

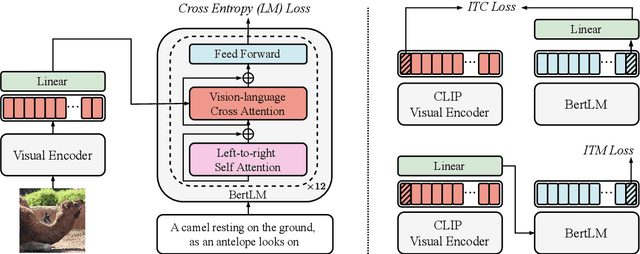
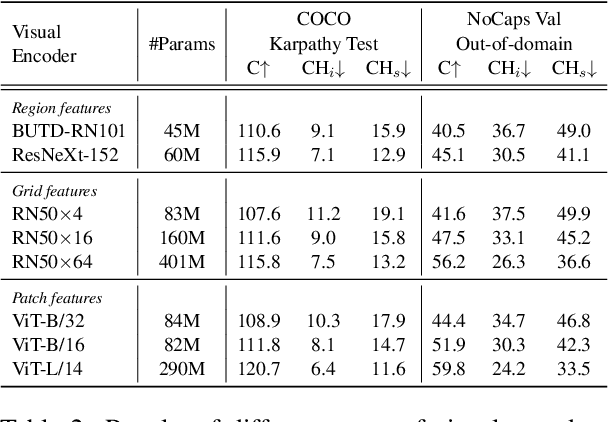
Large-scale vision-language pre-trained (VLP) models are prone to hallucinate non-existent visual objects when generating text based on visual information. In this paper, we exhaustively probe the object hallucination problem from three aspects. First, we examine various state-of-the-art VLP models, showing that models achieving better scores on standard metrics(e.g., BLEU-4, CIDEr) could hallucinate objects more frequently. Second, we investigate how different types of visual features in VLP influence hallucination, including region-based, grid-based, and patch-based. Surprisingly, we find that patch-based features perform the best and smaller patch resolution yields a non-trivial reduction in object hallucination. Third, we decouple various VLP objectives and demonstrate their effectiveness in alleviating object hallucination. Based on that, we propose a new pre-training loss, object masked language modeling, to further reduce object hallucination. We evaluate models on both COCO (in-domain) and NoCaps (out-of-domain) datasets with our improved CHAIR metric. Furthermore, we investigate the effects of various text decoding strategies and image augmentation methods on object hallucination.
Enabling Classifiers to Make Judgements Explicitly Aligned with Human Values
Oct 14, 2022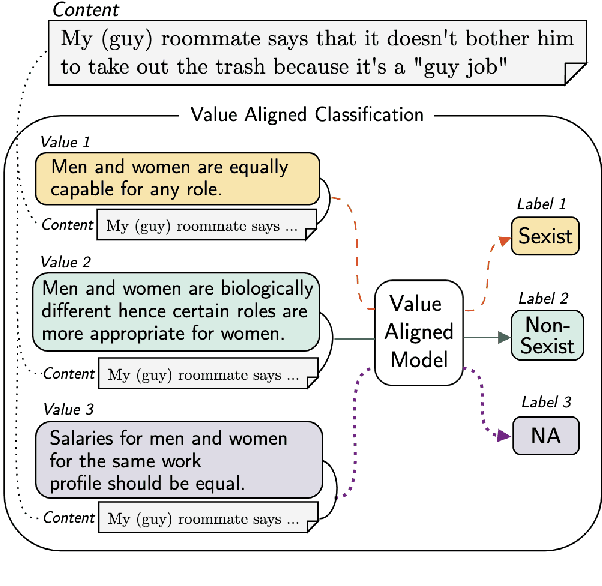
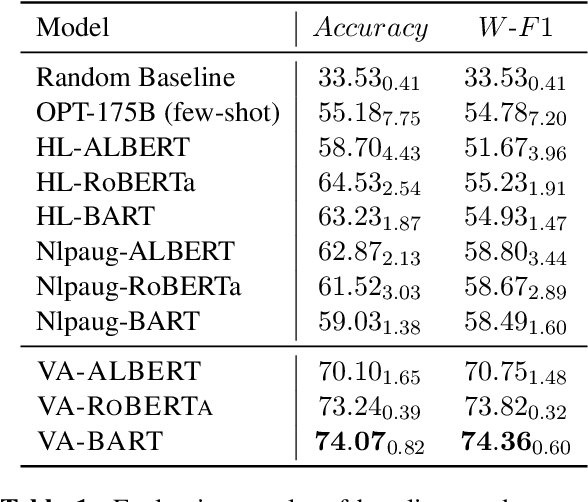
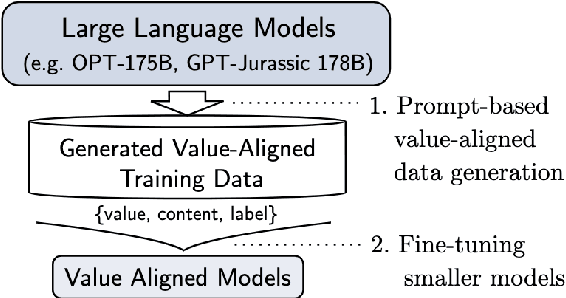
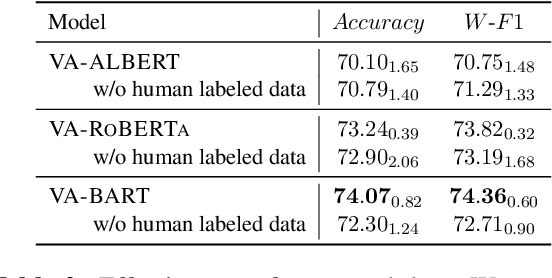
Many NLP classification tasks, such as sexism/racism detection or toxicity detection, are based on human values. Yet, human values can vary under diverse cultural conditions. Therefore, we introduce a framework for value-aligned classification that performs prediction based on explicitly written human values in the command. Along with the task, we propose a practical approach that distills value-aligned knowledge from large-scale language models (LLMs) to construct value-aligned classifiers in two steps. First, we generate value-aligned training data from LLMs by prompt-based few-shot learning. Next, we fine-tune smaller classification models with the generated data for the task. Empirical results show that our VA-Models surpass multiple baselines by at least 15.56% on the F1-score, including few-shot learning with OPT-175B and existing text augmentation methods. We suggest that using classifiers with explicit human value input improves both inclusivity & explainability in AI.
Context Generation Improves Open Domain Question Answering
Oct 12, 2022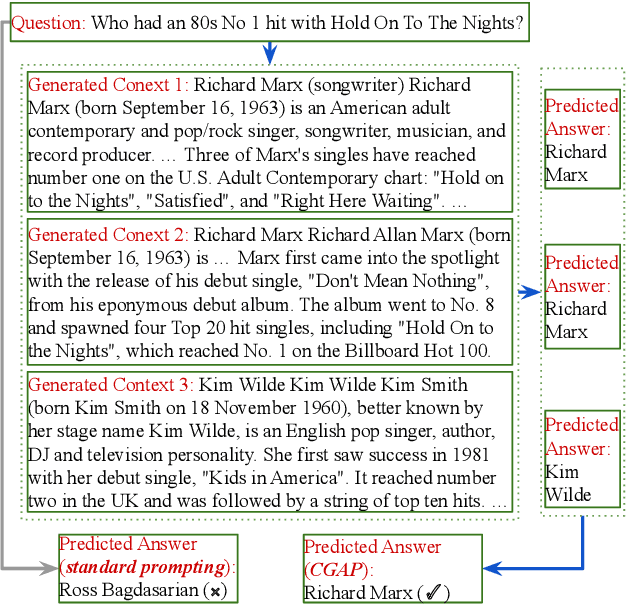

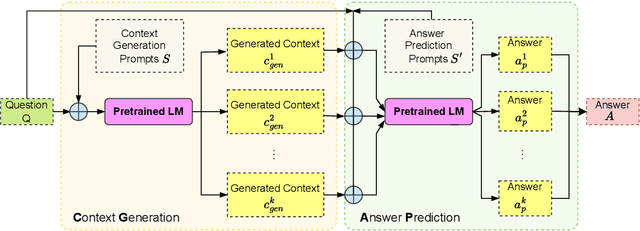
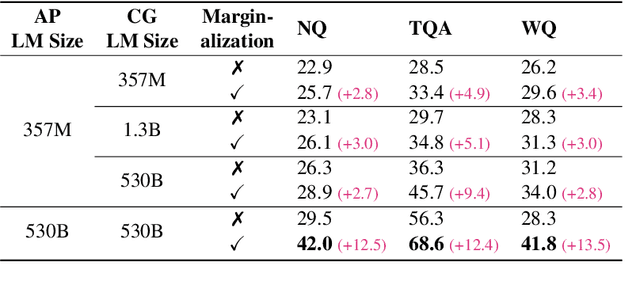
Closed-book question answering (QA) requires a model to directly answer an open-domain question without access to any external knowledge. Prior work on closed-book QA either directly finetunes or prompts a pretrained language model (LM) to leverage the stored knowledge. However, they do not fully exploit the parameterized knowledge. To address this issue, we propose a two-stage, closed-book QA framework which employs a coarse-to-fine approach to extract relevant knowledge and answer a question. Our approach first generates a related context for a given question by prompting a pretrained LM. We then prompt the same LM for answer prediction using the generated context and the question. Additionally, to eliminate failure caused by context uncertainty, we marginalize over generated contexts. Experimental results on three QA benchmarks show that our method significantly outperforms previous closed-book QA methods (e.g. exact matching 68.6% vs. 55.3%), and is on par with open-book methods that exploit external knowledge sources (e.g. 68.6% vs. 68.0%). Our method is able to better exploit the stored knowledge in pretrained LMs without adding extra learnable parameters or needing finetuning, and paves the way for hybrid models that integrate pretrained LMs with external knowledge.
Every picture tells a story: Image-grounded controllable stylistic story generation
Sep 11, 2022

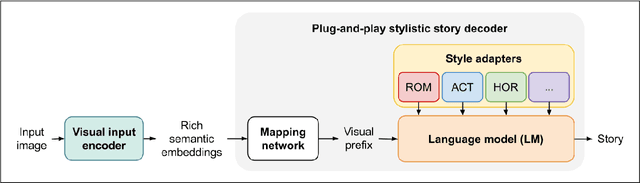

Generating a short story out of an image is arduous. Unlike image captioning, story generation from an image poses multiple challenges: preserving the story coherence, appropriately assessing the quality of the story, steering the generated story into a certain style, and addressing the scarcity of image-story pair reference datasets limiting supervision during training. In this work, we introduce Plug-and-Play Story Teller (PPST) and improve image-to-story generation by: 1) alleviating the data scarcity problem by incorporating large pre-trained models, namely CLIP and GPT-2, to facilitate a fluent image-to-text generation with minimal supervision, and 2) enabling a more style-relevant generation by incorporating stylistic adapters to control the story generation. We conduct image-to-story generation experiments with non-styled, romance-styled, and action-styled PPST approaches and compare our generated stories with those of previous work over three aspects, i.e., story coherence, image-story relevance, and style fitness, using both automatic and human evaluation. The results show that PPST improves story coherence and has better image-story relevance, but has yet to be adequately stylistic.
Kaggle Competition: Cantonese Audio-Visual Speech Recognition for In-car Commands
Jul 06, 2022
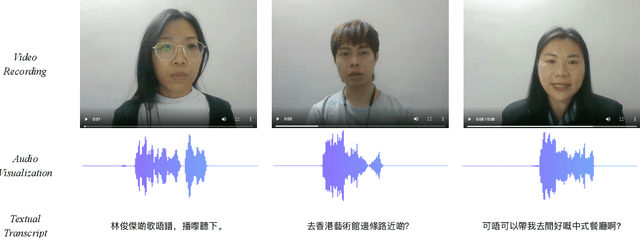
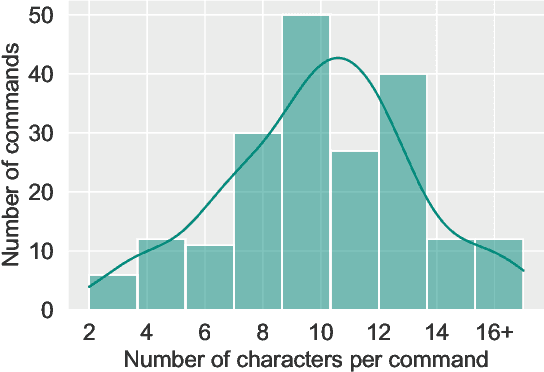

With the rise of deep learning and intelligent vehicles, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, in this research field, most datasets are in major languages, such as English and Chinese. There is a huge data scarcity issue for low-resource languages, hindering the development of research and applications for broader communities. Therefore, it is crucial to have more benchmarks to raise awareness and motivate the research in low-resource languages. To mitigate this problem, we collect a new dataset, namely Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car speech recognition in the Cantonese language with video and audio data. Together with it, we propose Cantonese Audio-Visual Speech Recognition for In-car Commands as a new challenge for the community to tackle low-resource speech recognition under in-car scenarios.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages
May 31, 2022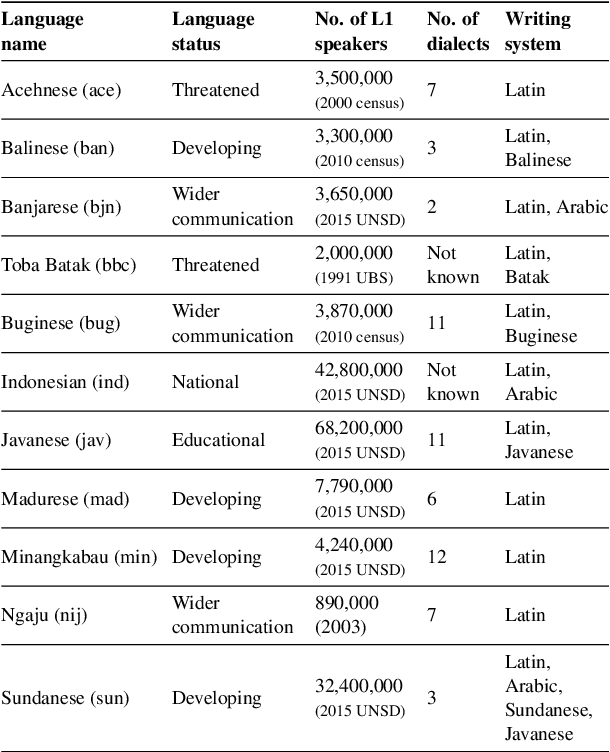
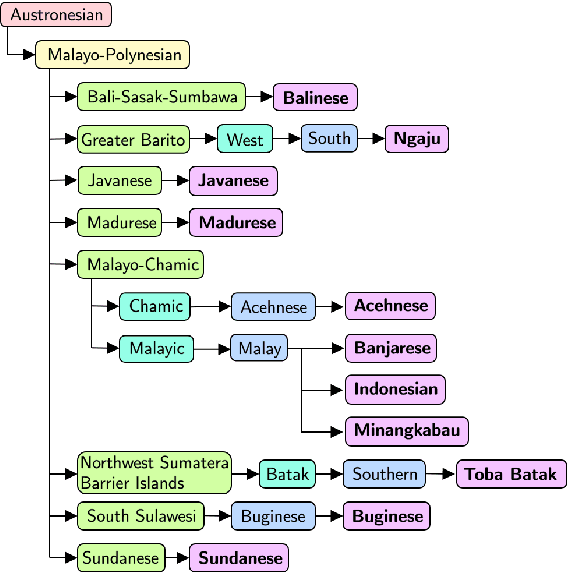
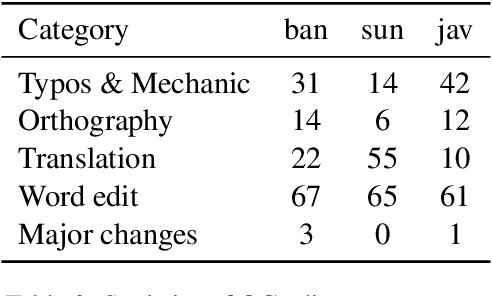
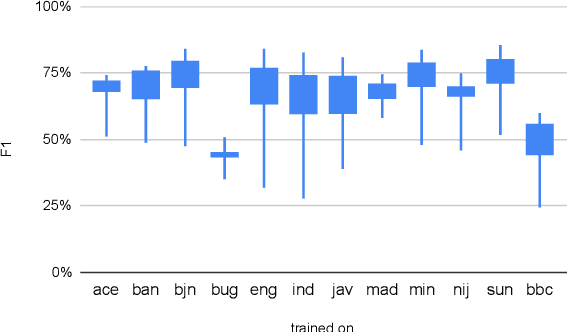
Natural language processing (NLP) has a significant impact on society via technologies such as machine translation and search engines. Despite its success, NLP technology is only widely available for high-resource languages such as English and Chinese, while it remains inaccessible to many languages due to the unavailability of data resources and benchmarks. In this work, we focus on developing resources for languages in Indonesia. Despite being the second most linguistically diverse country, most languages in Indonesia are categorized as endangered and some are even extinct. We develop the first-ever parallel resource for 10 low-resource languages in Indonesia. Our resource includes datasets, a multi-task benchmark, and lexicons, as well as a parallel Indonesian-English dataset. We provide extensive analyses and describe the challenges when creating such resources. We hope that our work can spark NLP research on Indonesian and other underrepresented languages.
ToKen: Task Decomposition and Knowledge Infusion for Few-Shot Hate Speech Detection
May 25, 2022
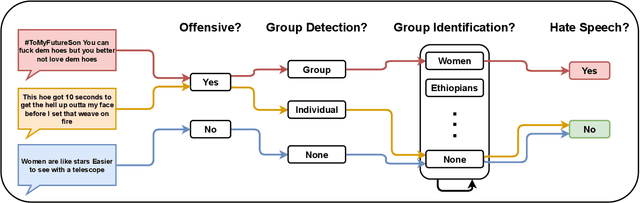

Hate speech detection is complex; it relies on commonsense reasoning, knowledge of stereotypes, and an understanding of social nuance that differs from one culture to the next. It is also difficult to collect a large-scale hate speech annotated dataset. In this work, we frame this problem as a few-shot learning task, and show significant gains with decomposing the task into its "constituent" parts. In addition, we see that infusing knowledge from reasoning datasets (e.g. Atomic2020) improves the performance even further. Moreover, we observe that the trained models generalize to out-of-distribution datasets, showing the superiority of task decomposition and knowledge infusion compared to previously used methods. Concretely, our method outperforms the baseline by 17.83% absolute gain in the 16-shot case.
AiSocrates: Towards Answering Ethical Quandary Questions
May 24, 2022
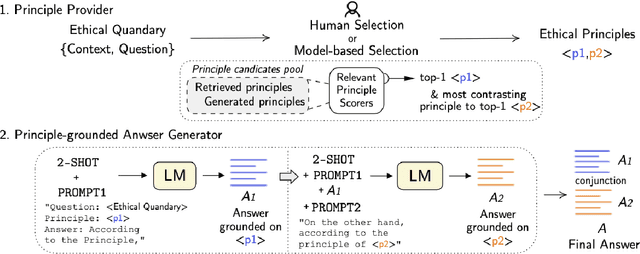


Considerable advancements have been made in various NLP tasks based on the impressive power of large pre-trained language models (LLMs). These results have inspired efforts to understand the limits of LLMs so as to evaluate how far we are from achieving human level general natural language understanding. In this work, we challenge the capability of LLMs with the new task of Ethical Quandary Generative Question Answering. Ethical quandary questions are more challenging to address because multiple conflicting answers may exist to a single quandary. We propose a system, AiSocrates, that provides an answer with a deliberative exchange of different perspectives to an ethical quandary, in the approach of Socratic philosophy, instead of providing a closed answer like an oracle. AiSocrates searches for different ethical principles applicable to the ethical quandary and generates an answer conditioned on the chosen principles through prompt-based few-shot learning. We also address safety concerns by providing a human controllability option in choosing ethical principles. We show that AiSocrates generates promising answers to ethical quandary questions with multiple perspectives, 6.92% more often than answers written by human philosophers by one measure, but the system still needs improvement to match the coherence of human philosophers fully. We argue that AiSocrates is a promising step toward developing an NLP system that incorporates human values explicitly by prompt instructions. We are releasing the code for research purposes.
NeuS: Neutral Multi-News Summarization for Mitigating Framing Bias
Apr 17, 2022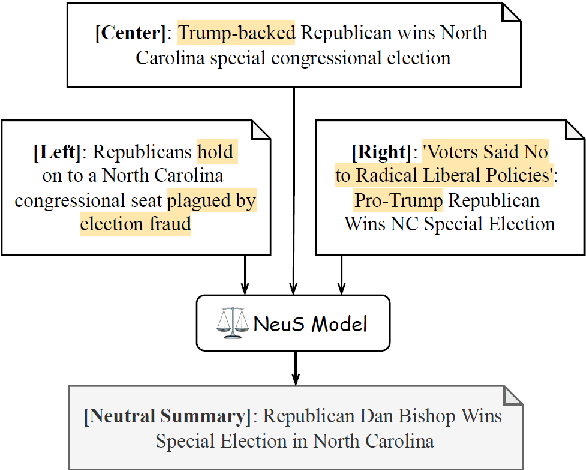

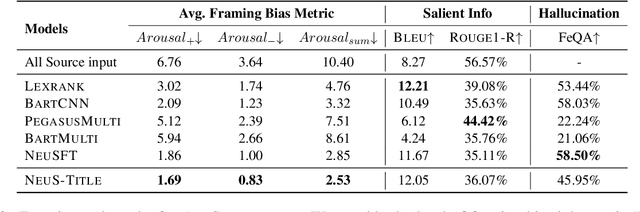

Media framing bias can lead to increased political polarization, and thus, the need for automatic mitigation methods is growing. We propose a new task, a neutral summary generation from multiple news headlines of the varying political leanings to facilitate balanced and unbiased news reading. In this paper, we first collect a new dataset, obtain insights about framing bias through a case study, and propose a new effective metric and models for the task. Lastly, we conduct experimental analyses to provide insights about remaining challenges and future directions. One of the most interesting observations is that generation models can hallucinate not only factually inaccurate or unverifiable content, but also politically biased content.