 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIMA: Less Is More for Alignment
May 18, 2023



Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
LEVER: Learning to Verify Language-to-Code Generation with Execution
Feb 16, 2023The advent of pre-trained code language models (CodeLMs) has lead to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
Demystifying Prompts in Language Models via Perplexity Estimation
Dec 08, 2022



Language models can be prompted to perform a wide variety of zero- and few-shot learning problems. However, performance varies significantly with the choice of prompt, and we do not yet understand why this happens or how to pick the best prompts. In this work, we analyze the factors that contribute to this variance and establish a new empirical hypothesis: the performance of a prompt is coupled with the extent to which the model is familiar with the language it contains. Over a wide range of tasks, we show that the lower the perplexity of the prompt is, the better the prompt is able to perform the task. As a result, we devise a method for creating prompts: (1) automatically extend a small seed set of manually written prompts by paraphrasing using GPT3 and backtranslation and (2) choose the lowest perplexity prompts to get significant gains in performance.
ToKen: Task Decomposition and Knowledge Infusion for Few-Shot Hate Speech Detection
May 25, 2022
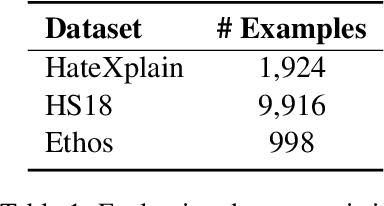
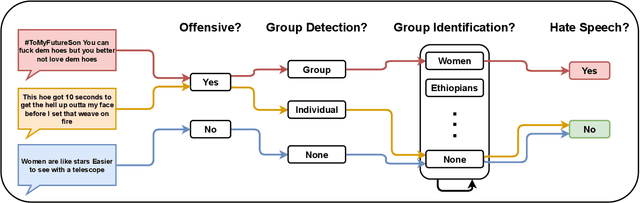

Hate speech detection is complex; it relies on commonsense reasoning, knowledge of stereotypes, and an understanding of social nuance that differs from one culture to the next. It is also difficult to collect a large-scale hate speech annotated dataset. In this work, we frame this problem as a few-shot learning task, and show significant gains with decomposing the task into its "constituent" parts. In addition, we see that infusing knowledge from reasoning datasets (e.g. Atomic2020) improves the performance even further. Moreover, we observe that the trained models generalize to out-of-distribution datasets, showing the superiority of task decomposition and knowledge infusion compared to previously used methods. Concretely, our method outperforms the baseline by 17.83% absolute gain in the 16-shot case.
Improving In-Context Few-Shot Learning via Self-Supervised Training
May 03, 2022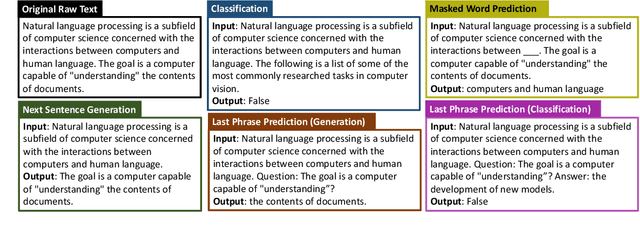

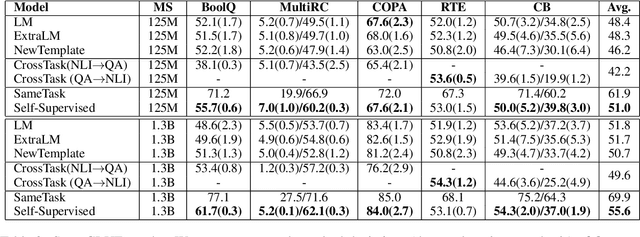

Self-supervised pretraining has made few-shot learning possible for many NLP tasks. But the pretraining objectives are not typically adapted specifically for in-context few-shot learning. In this paper, we propose to use self-supervision in an intermediate training stage between pretraining and downstream few-shot usage with the goal to teach the model to perform in-context few shot learning. We propose and evaluate four self-supervised objectives on two benchmarks. We find that the intermediate self-supervision stage produces models that outperform strong baselines. Ablation study shows that several factors affect the downstream performance, such as the amount of training data and the diversity of the self-supervised objectives. Human-annotated cross-task supervision and self-supervision are complementary. Qualitative analysis suggests that the self-supervised-trained models are better at following task requirements.
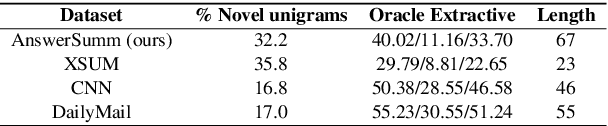
AnswerSumm: A Manually-Curated Dataset and Pipeline for Answer Summarization
Nov 11, 2021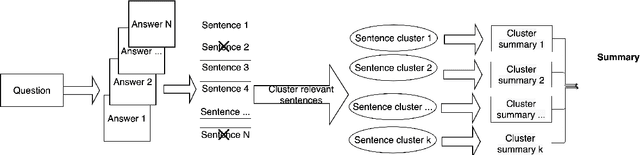
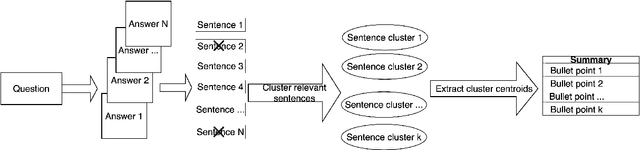
Community Question Answering (CQA) fora such as Stack Overflow and Yahoo! Answers contain a rich resource of answers to a wide range of community-based questions. Each question thread can receive a large number of answers with different perspectives. One goal of answer summarization is to produce a summary that reflects the range of answer perspectives. A major obstacle for abstractive answer summarization is the absence of a dataset to provide supervision for producing such summaries. Recent works propose heuristics to create such data, but these are often noisy and do not cover all perspectives present in the answers. This work introduces a novel dataset of 4,631 CQA threads for answer summarization, curated by professional linguists. Our pipeline gathers annotations for all subtasks involved in answer summarization, including the selection of answer sentences relevant to the question, grouping these sentences based on perspectives, summarizing each perspective, and producing an overall summary. We analyze and benchmark state-of-the-art models on these subtasks and introduce a novel unsupervised approach for multi-perspective data augmentation, that further boosts overall summarization performance according to automatic evaluation. Finally, we propose reinforcement learning rewards to improve factual consistency and answer coverage and analyze areas for improvement.
Multi-Perspective Abstractive Answer Summarization
Apr 17, 2021
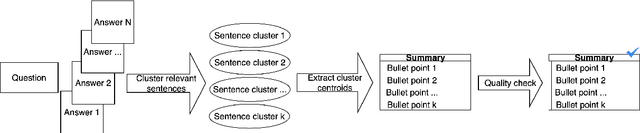

Community Question Answering (CQA) forums such as Stack Overflow and Yahoo! Answers contain a rich resource of answers to a wide range of questions. Each question thread can receive a large number of answers with different perspectives. The goal of multi-perspective answer summarization is to produce a summary that includes all perspectives of the answer. A major obstacle for multi-perspective, abstractive answer summarization is the absence of a dataset to provide supervision for producing such summaries. This work introduces a novel dataset creation method to automatically create multi-perspective, bullet-point abstractive summaries from an existing CQA forum. Supervision provided by this dataset trains models to inherently produce multi-perspective summaries. Additionally, to train models to output more diverse, faithful answer summaries while retaining multiple perspectives, we propose a multi-reward optimization technique coupled with a sentence-relevance prediction multi-task loss. Our methods demonstrate improved coverage of perspectives and faithfulness as measured by automatic and human evaluations compared to a strong baseline.
Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval
Sep 27, 2020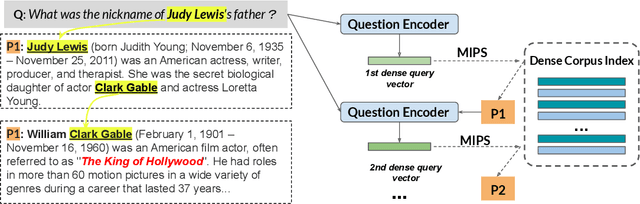
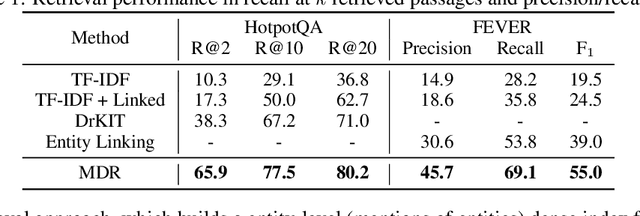
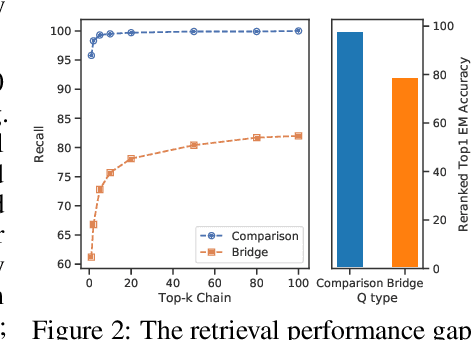

We propose a simple and efficient multi-hop dense retrieval approach for answering complex open-domain questions, which achieves state-of-the-art performance on two multi-hop datasets, HotpotQA and multi-evidence FEVER. Contrary to previous work, our method does not require access to any corpus-specific information, such as inter-document hyperlinks or human-annotated entity markers, and can be applied to any unstructured text corpus. Our system also yields a much better efficiency-accuracy trade-off, matching the best published accuracy on HotpotQA while being 10 times faster at inference time.