 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Pretrained Vision-Language Models with Correlation Information Bottleneck for Robust Visual Question Answering
Sep 14, 2022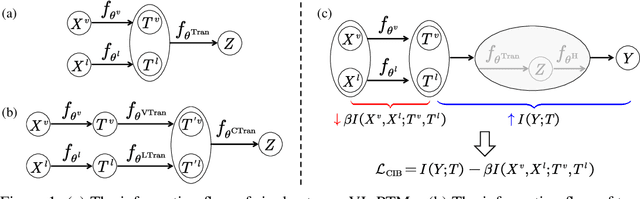
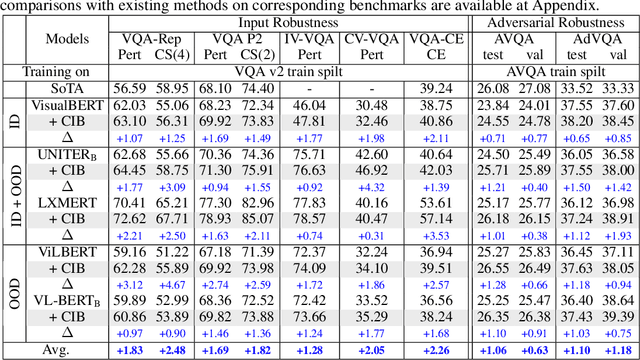
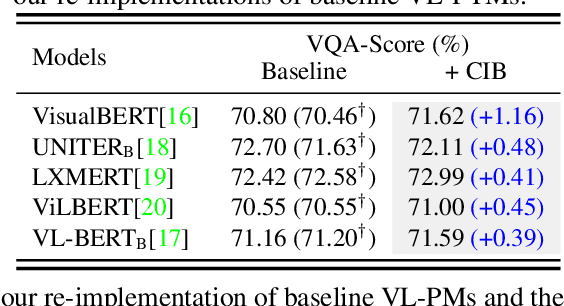

Benefiting from large-scale Pretrained Vision-Language Models (VL-PMs), the performance of Visual Question Answering (VQA) has started to approach human oracle performance. However, finetuning large-scale VL-PMs with limited data for VQA usually faces overfitting and poor generalization issues, leading to a lack of robustness. In this paper, we aim to improve the robustness of VQA systems (ie, the ability of the systems to defend against input variations and human-adversarial attacks) from the perspective of Information Bottleneck when finetuning VL-PMs for VQA. Generally, internal representations obtained by VL-PMs inevitably contain irrelevant and redundant information for the downstream VQA task, resulting in statistically spurious correlations and insensitivity to input variations. To encourage representations to converge to a minimal sufficient statistic in vision-language learning, we propose the Correlation Information Bottleneck (CIB) principle, which seeks a tradeoff between representation compression and redundancy by minimizing the mutual information (MI) between the inputs and internal representations while maximizing the MI between the outputs and the representations. Meanwhile, CIB measures the internal correlations among visual and linguistic inputs and representations by a symmetrized joint MI estimation. Extensive experiments on five VQA benchmarks of input robustness and two VQA benchmarks of human-adversarial robustness demonstrate the effectiveness and superiority of the proposed CIB in improving the robustness of VQA systems.
DBQ-SSD: Dynamic Ball Query for Efficient 3D Object Detection
Jul 22, 2022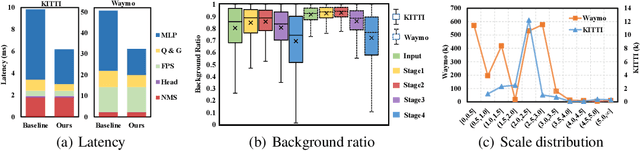
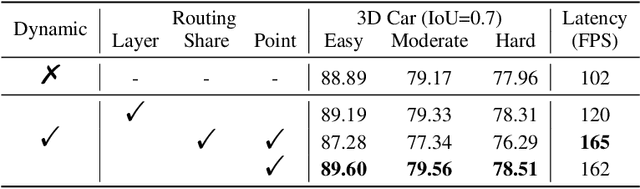
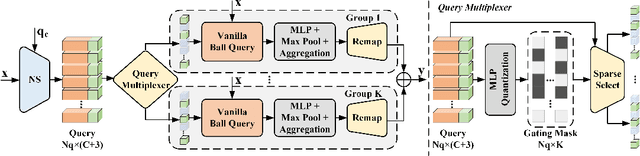
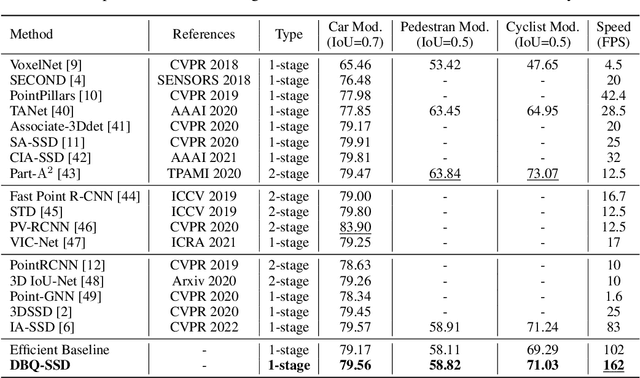
Many point-based 3D detectors adopt point-feature sampling strategies to drop some points for efficient inference. These strategies are typically based on fixed and handcrafted rules, making difficult to handle complicated scenes. Different from them, we propose a Dynamic Ball Query (DBQ) network to adaptively select a subset of input points according to the input features, and assign the feature transform with suitable receptive field for each selected point. It can be embedded into some state-of-the-art 3D detectors and trained in an end-to-end manner, which significantly reduces the computational cost. Extensive experiments demonstrate that our method can reduce latency by 30%-60% on KITTI and Waymo datasets. Specifically, the inference speed of our detector can reach 162 FPS and 30 FPS with negligible performance degradation on KITTI and Waymo datasets, respectively.
Learning to Refactor Action and Co-occurrence Features for Temporal Action Localization
Jun 23, 2022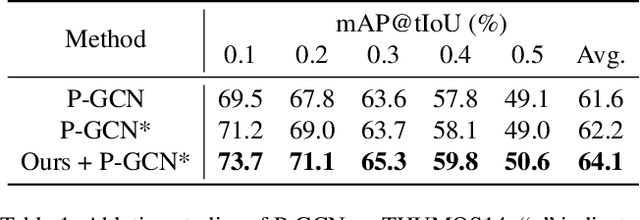
The main challenge of Temporal Action Localization is to retrieve subtle human actions from various co-occurring ingredients, e.g., context and background, in an untrimmed video. While prior approaches have achieved substantial progress through devising advanced action detectors, they still suffer from these co-occurring ingredients which often dominate the actual action content in videos. In this paper, we explore two orthogonal but complementary aspects of a video snippet, i.e., the action features and the co-occurrence features. Especially, we develop a novel auxiliary task by decoupling these two types of features within a video snippet and recombining them to generate a new feature representation with more salient action information for accurate action localization. We term our method RefactorNet, which first explicitly factorizes the action content and regularizes its co-occurrence features, and then synthesizes a new action-dominated video representation. Extensive experimental results and ablation studies on THUMOS14 and ActivityNet v1.3 demonstrate that our new representation, combined with a simple action detector, can significantly improve the action localization performance.
Social Interpretable Tree for Pedestrian Trajectory Prediction
May 26, 2022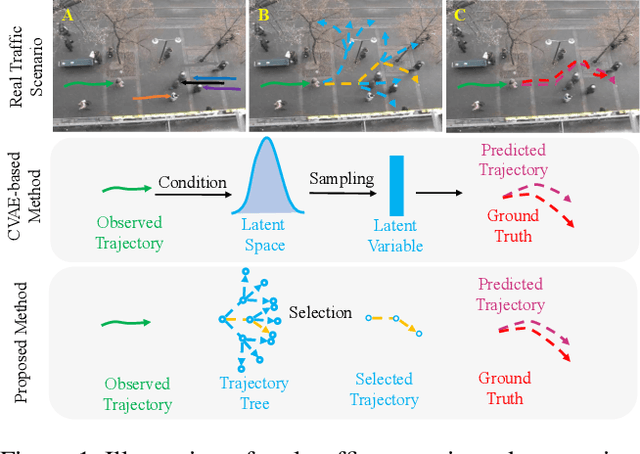
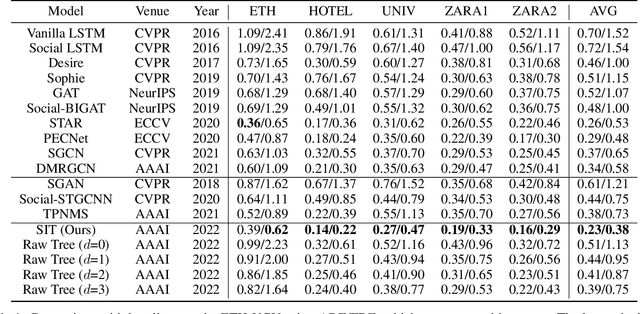
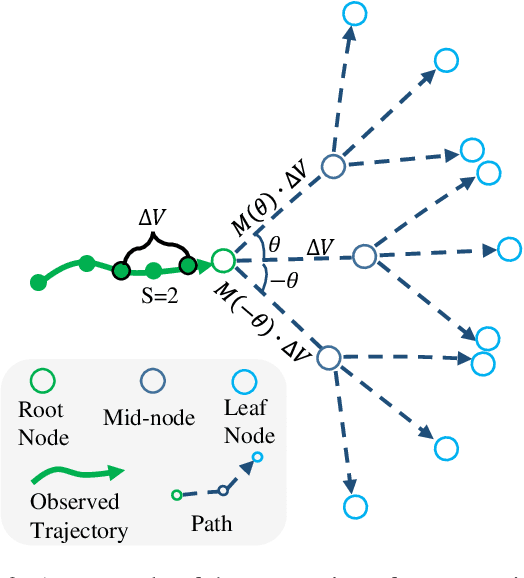
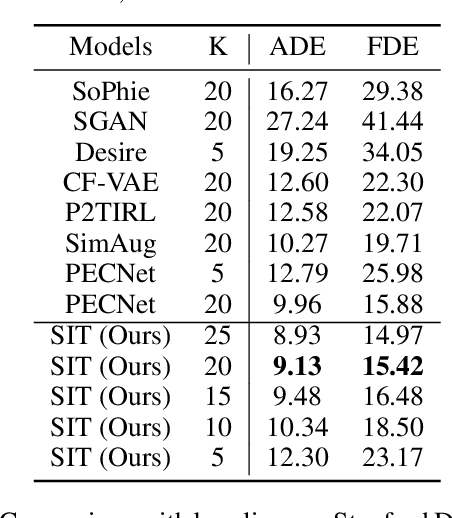
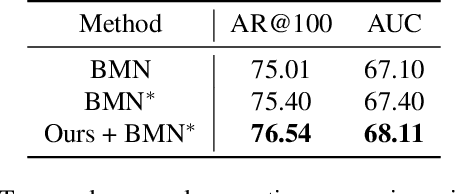
Understanding the multiple socially-acceptable future behaviors is an essential task for many vision applications. In this paper, we propose a tree-based method, termed as Social Interpretable Tree (SIT), to address this multi-modal prediction task, where a hand-crafted tree is built depending on the prior information of observed trajectory to model multiple future trajectories. Specifically, a path in the tree from the root to leaf represents an individual possible future trajectory. SIT employs a coarse-to-fine optimization strategy, in which the tree is first built by high-order velocity to balance the complexity and coverage of the tree and then optimized greedily to encourage multimodality. Finally, a teacher-forcing refining operation is used to predict the final fine trajectory. Compared with prior methods which leverage implicit latent variables to represent possible future trajectories, the path in the tree can explicitly explain the rough moving behaviors (e.g., go straight and then turn right), and thus provides better interpretability. Despite the hand-crafted tree, the experimental results on ETH-UCY and Stanford Drone datasets demonstrate that our method is capable of matching or exceeding the performance of state-of-the-art methods. Interestingly, the experiments show that the raw built tree without training outperforms many prior deep neural network based approaches. Meanwhile, our method presents sufficient flexibility in long-term prediction and different best-of-$K$ predictions.
Test-time Batch Normalization
May 20, 2022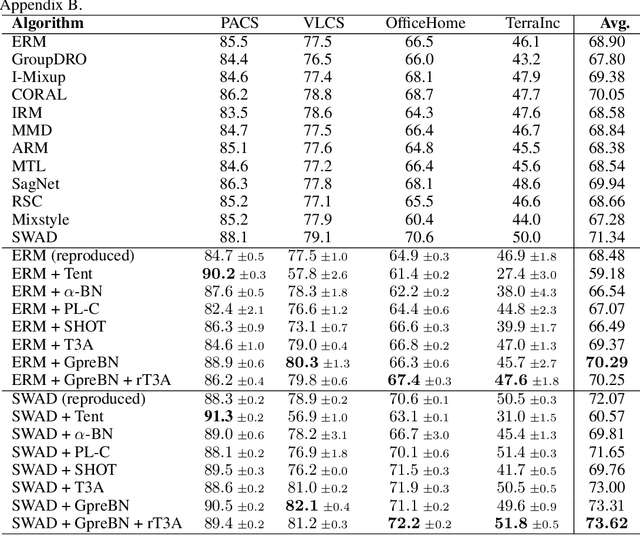

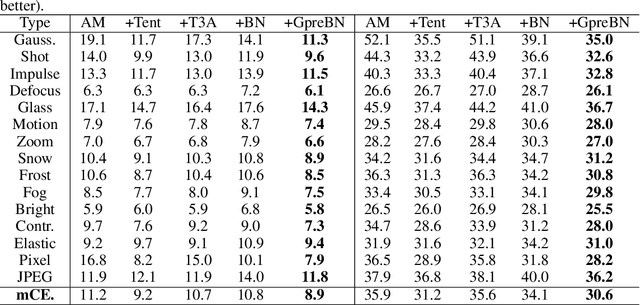
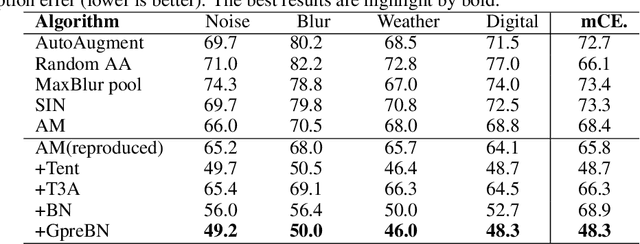
Deep neural networks often suffer the data distribution shift between training and testing, and the batch statistics are observed to reflect the shift. In this paper, targeting of alleviating distribution shift in test time, we revisit the batch normalization (BN) in the training process and reveals two key insights benefiting test-time optimization: $(i)$ preserving the same gradient backpropagation form as training, and $(ii)$ using dataset-level statistics for robust optimization and inference. Based on the two insights, we propose a novel test-time BN layer design, GpreBN, which is optimized during testing by minimizing Entropy loss. We verify the effectiveness of our method on two typical settings with distribution shift, i.e., domain generalization and robustness tasks. Our GpreBN significantly improves the test-time performance and achieves the state of the art results.
Visual Concepts Tokenization
May 20, 2022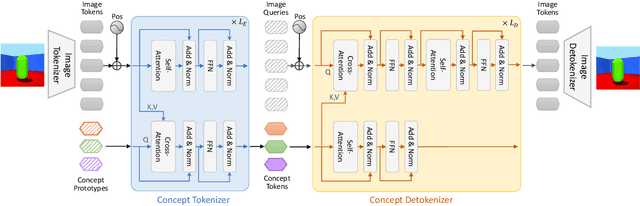
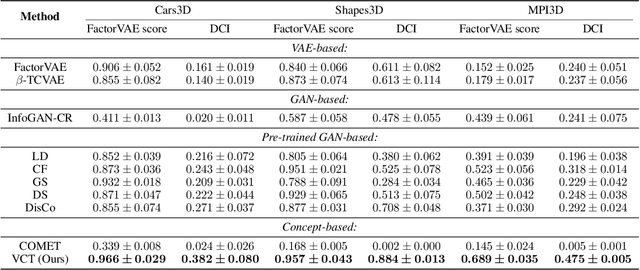
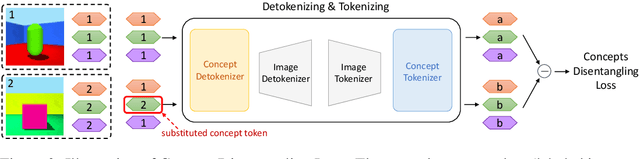
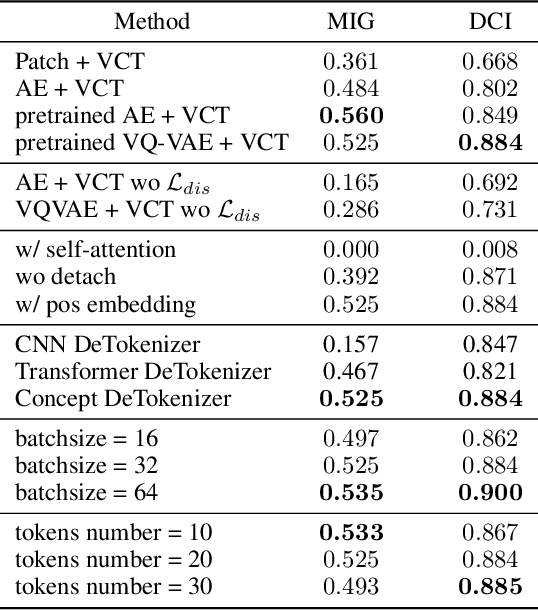
Obtaining the human-like perception ability of abstracting visual concepts from concrete pixels has always been a fundamental and important target in machine learning research fields such as disentangled representation learning and scene decomposition. Towards this goal, we propose an unsupervised transformer-based Visual Concepts Tokenization framework, dubbed VCT, to perceive an image into a set of disentangled visual concept tokens, with each concept token responding to one type of independent visual concept. Particularly, to obtain these concept tokens, we only use cross-attention to extract visual information from the image tokens layer by layer without self-attention between concept tokens, preventing information leakage across concept tokens. We further propose a Concept Disentangling Loss to facilitate that different concept tokens represent independent visual concepts. The cross-attention and disentangling loss play the role of induction and mutual exclusion for the concept tokens, respectively. Extensive experiments on several popular datasets verify the effectiveness of VCT on the tasks of disentangled representation learning and scene decomposition. VCT achieves the state of the art results by a large margin.
Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models
Mar 07, 2022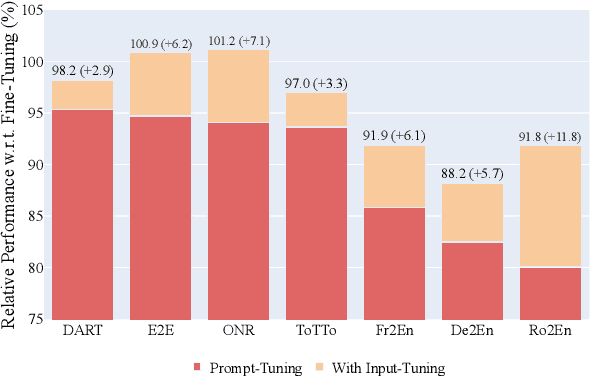

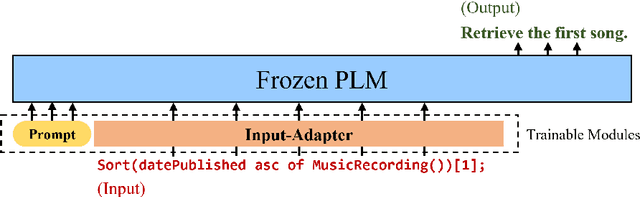
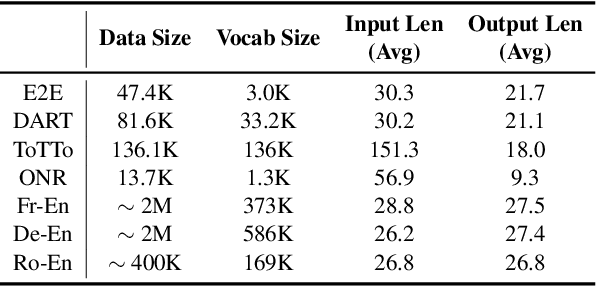
Recently the prompt-tuning paradigm has attracted significant attention. By only tuning continuous prompts with a frozen pre-trained language model (PLM), prompt-tuning takes a step towards deploying a shared frozen PLM to serve numerous downstream tasks. Although prompt-tuning shows good performance on certain natural language understanding (NLU) tasks, its effectiveness on natural language generation (NLG) tasks is still under-explored. In this paper, we argue that one of the factors hindering the development of prompt-tuning on NLG tasks is the unfamiliar inputs (i.e., inputs are linguistically different from the pretraining corpus). For example, our preliminary exploration reveals a large performance gap between prompt-tuning and fine-tuning when unfamiliar inputs occur frequently in NLG tasks. This motivates us to propose input-tuning, which fine-tunes both the continuous prompts and the input representations, leading to a more effective way to adapt unfamiliar inputs to frozen PLMs. Our proposed input-tuning is conceptually simple and empirically powerful. Experimental results on seven NLG tasks demonstrate that input-tuning is significantly and consistently better than prompt-tuning. Furthermore, on three of these tasks, input-tuning can achieve a comparable or even better performance than fine-tuning.
Trajectory Forecasting from Detection with Uncertainty-Aware Motion Encoding
Feb 10, 2022Trajectory forecasting is critical for autonomous platforms to make safe planning and actions. Currently, most trajectory forecasting methods assume that object trajectories have been extracted and directly develop trajectory predictors based on the ground truth trajectories. However, this assumption does not hold in practical situations. Trajectories obtained from object detection and tracking are inevitably noisy, which could cause serious forecasting errors to predictors built on ground truth trajectories. In this paper, we propose a trajectory predictor directly based on detection results without relying on explicitly formed trajectories. Different from the traditional methods which encode the motion cue of an agent based on its clearly defined trajectory, we extract the motion information only based on the affinity cues among detection results, in which an affinity-aware state update mechanism is designed to take the uncertainty of association into account. In addition, considering that there could be multiple plausible matching candidates, we aggregate the states of them. This design relaxes the undesirable effect of noisy trajectory obtained from data association. Extensive ablation experiments validate the effectiveness of our method and its generalization ability on different detectors. Cross-comparison to other forecasting schemes further proves the superiority of our method. Code will be released upon acceptance.
LiVLR: A Lightweight Visual-Linguistic Reasoning Framework for Video Question Answering
Nov 30, 2021
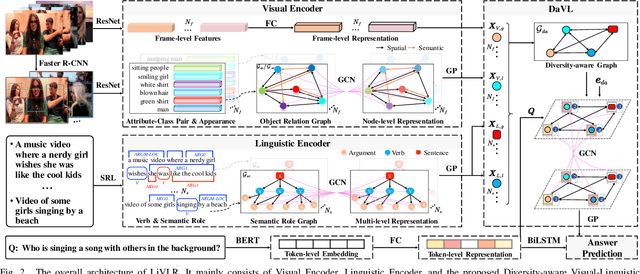
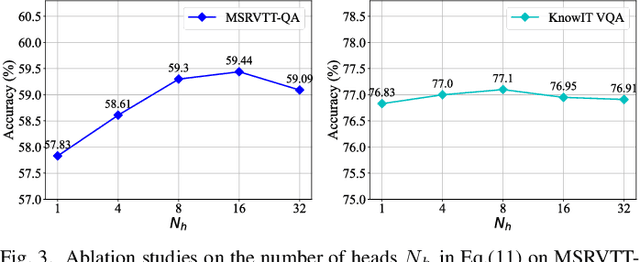
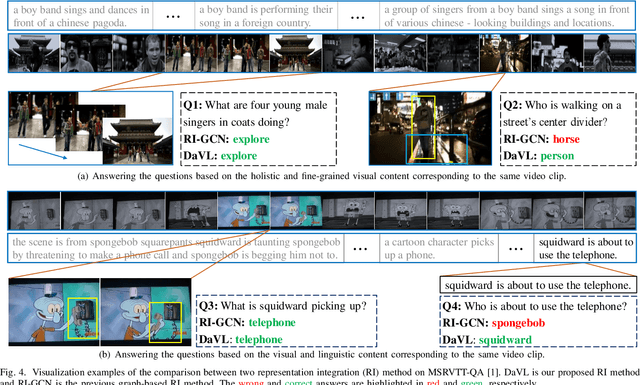
Video Question Answering (VideoQA), aiming to correctly answer the given question based on understanding multi-modal video content, is challenging due to the rich video content. From the perspective of video understanding, a good VideoQA framework needs to understand the video content at different semantic levels and flexibly integrate the diverse video content to distill question-related content. To this end, we propose a Lightweight Visual-Linguistic Reasoning framework named LiVLR. Specifically, LiVLR first utilizes the graph-based Visual and Linguistic Encoders to obtain multi-grained visual and linguistic representations. Subsequently, the obtained representations are integrated with the devised Diversity-aware Visual-Linguistic Reasoning module (DaVL). The DaVL considers the difference between the different types of representations and can flexibly adjust the importance of different types of representations when generating the question-related joint representation, which is an effective and general representation integration method. The proposed LiVLR is lightweight and shows its performance advantage on two VideoQA benchmarks, MRSVTT-QA and KnowIT VQA. Extensive ablation studies demonstrate the effectiveness of LiVLR key components.
Multi-Scale Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
Nov 07, 2021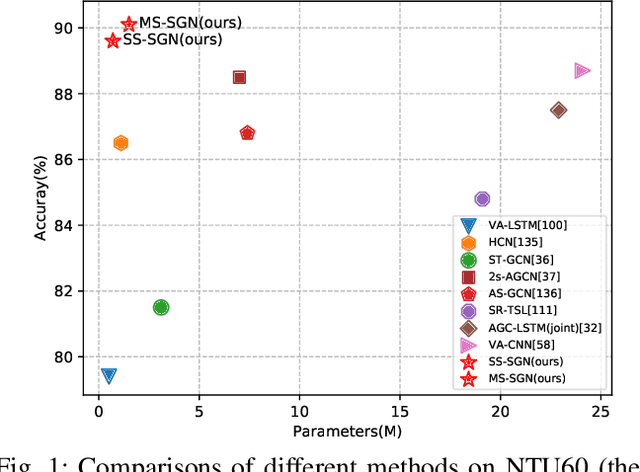

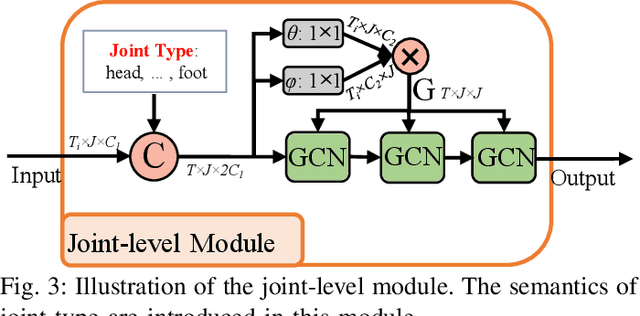
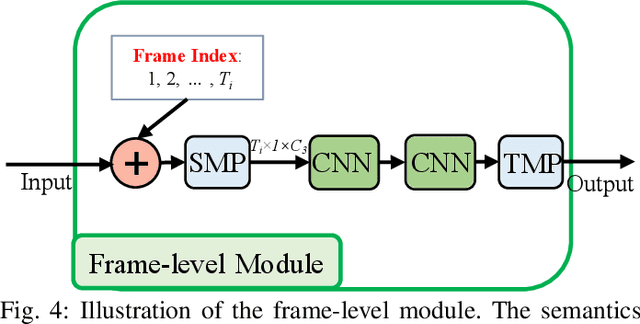
Skeleton data is of low dimension. However, there is a trend of using very deep and complicated feedforward neural networks to model the skeleton sequence without considering the complexity in recent year. In this paper, a simple yet effective multi-scale semantics-guided neural network (MS-SGN) is proposed for skeleton-based action recognition. We explicitly introduce the high level semantics of joints (joint type and frame index) into the network to enhance the feature representation capability of joints. Moreover, a multi-scale strategy is proposed to be robust to the temporal scale variations. In addition, we exploit the relationship of joints hierarchically through two modules, i.e., a joint-level module for modeling the correlations of joints in the same frame and a frame-level module for modeling the temporal dependencies of frames. With an order of magnitude smaller model size than most previous methods, MSSGN achieves the state-of-the-art performance on the NTU60, NTU120, and SYSU datasets.