 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Tractability of Off-policy Evaluation of History-dependent Policies in POMDPs
Mar 03, 2025We investigate off-policy evaluation (OPE), a central and fundamental problem in reinforcement learning (RL), in the challenging setting of Partially Observable Markov Decision Processes (POMDPs) with large observation spaces. Recent works of Uehara et al. (2023a); Zhang & Jiang (2024) developed a model-free framework and identified important coverage assumptions (called belief and outcome coverage) that enable accurate OPE of memoryless policies with polynomial sample complexities, but handling more general target policies that depend on the entire observable history remained an open problem. In this work, we prove information-theoretic hardness for model-free OPE of history-dependent policies in several settings, characterized by additional assumptions imposed on the behavior policy (memoryless vs. history-dependent) and/or the state-revealing property of the POMDP (single-step vs. multi-step revealing). We further show that some hardness can be circumvented by a natural model-based algorithm -- whose analysis has surprisingly eluded the literature despite the algorithm's simplicity -- demonstrating provable separation between model-free and model-based OPE in POMDPs.
An Exact Solver for Satisfiability Modulo Counting with Probabilistic Circuits
Mar 02, 2025



Satisfiability Modulo Counting (SMC) is a recently proposed general language to reason about problems integrating statistical and symbolic artificial intelligence. An SMC formula is an extended SAT formula in which the truth values of a few Boolean variables are determined by probabilistic inference. Existing approximate solvers optimize surrogate objectives, which lack formal guarantees. Current exact solvers directly integrate SAT solvers and probabilistic inference solvers resulting in slow performance because of many back-and-forth invocations of both solvers. We propose KOCO-SMC, an integrated exact SMC solver that efficiently tracks lower and upper bounds in the probabilistic inference process. It enhances computational efficiency by enabling early estimation of probabilistic inference using only partial variable assignments, whereas existing methods require full variable assignments. In the experiment, we compare KOCO-SMC with currently available approximate and exact SMC solvers on large-scale datasets and real-world applications. Our approach delivers high-quality solutions with high efficiency.
Self-rewarding correction for mathematical reasoning
Feb 26, 2025We study self-rewarding reasoning large language models (LLMs), which can simultaneously generate step-by-step reasoning and evaluate the correctness of their outputs during the inference time-without external feedback. This integrated approach allows a single model to independently guide its reasoning process, offering computational advantages for model deployment. We particularly focus on the representative task of self-correction, where models autonomously detect errors in their responses, revise outputs, and decide when to terminate iterative refinement loops. To enable this, we propose a two-staged algorithmic framework for constructing self-rewarding reasoning models using only self-generated data. In the first stage, we employ sequential rejection sampling to synthesize long chain-of-thought trajectories that incorporate both self-rewarding and self-correction mechanisms. Fine-tuning models on these curated data allows them to learn the patterns of self-rewarding and self-correction. In the second stage, we further enhance the models' ability to assess response accuracy and refine outputs through reinforcement learning with rule-based signals. Experiments with Llama-3 and Qwen-2.5 demonstrate that our approach surpasses intrinsic self-correction capabilities and achieves performance comparable to systems that rely on external reward models.
Improving LLM General Preference Alignment via Optimistic Online Mirror Descent
Feb 24, 2025


Reinforcement learning from human feedback (RLHF) has demonstrated remarkable effectiveness in aligning large language models (LLMs) with human preferences. Many existing alignment approaches rely on the Bradley-Terry (BT) model assumption, which assumes the existence of a ground-truth reward for each prompt-response pair. However, this assumption can be overly restrictive when modeling complex human preferences. In this paper, we drop the BT model assumption and study LLM alignment under general preferences, formulated as a two-player game. Drawing on theoretical insights from learning in games, we integrate optimistic online mirror descent into our alignment framework to approximate the Nash policy. Theoretically, we demonstrate that our approach achieves an $O(T^{-1})$ bound on the duality gap, improving upon the previous $O(T^{-1/2})$ result. More importantly, we implement our method and show through experiments that it outperforms state-of-the-art RLHF algorithms across multiple representative benchmarks.
Model Selection for Off-policy Evaluation: New Algorithms and Experimental Protocol
Feb 11, 2025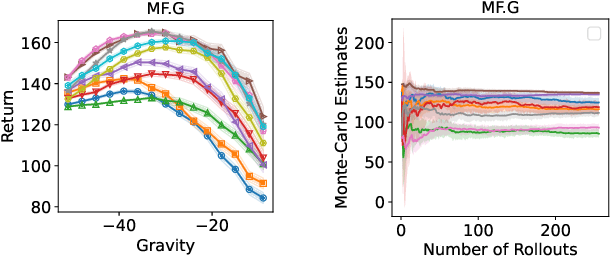

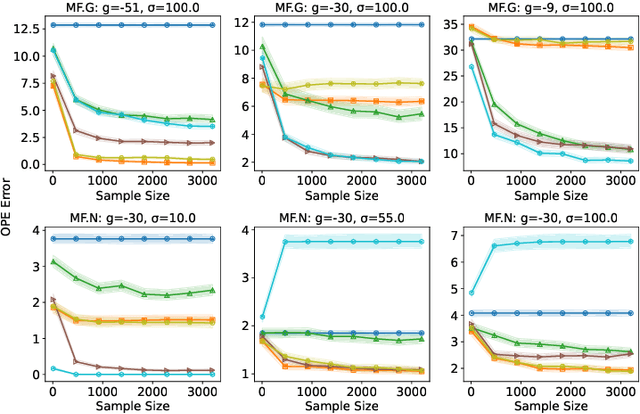
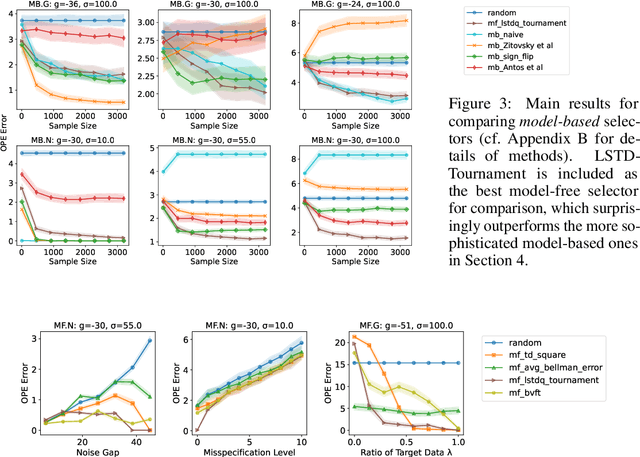
Holdout validation and hyperparameter tuning from data is a long-standing problem in offline reinforcement learning (RL). A standard framework is to use off-policy evaluation (OPE) methods to evaluate and select the policies, but OPE either incurs exponential variance (e.g., importance sampling) or has hyperparameters on their own (e.g., FQE and model-based). In this work we focus on hyperparameter tuning for OPE itself, which is even more under-investigated. Concretely, we select among candidate value functions ("model-free") or dynamics ("model-based") to best assess the performance of a target policy. Our contributions are two fold. We develop: (1) new model-free and model-based selectors with theoretical guarantees, and (2) a new experimental protocol for empirically evaluating them. Compared to the model-free protocol in prior works, our new protocol allows for more stable generation of candidate value functions, better control of misspecification, and evaluation of model-free and model-based methods alike. We exemplify the protocol on a Gym environment, and find that our new model-free selector, LSTD-Tournament, demonstrates promising empirical performance.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
MLLM-as-a-Judge for Image Safety without Human Labeling
Dec 31, 2024



Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image generation models are capable of producing harmful content, such as images containing sexual or violent material. Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities. Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive. Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)? Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models. To address these challenges, we propose a MLLM-based method includes objectifying safety rules, assessing the relevance between rules and images, making quick judgments based on debiased token probabilities with logically complete yet simplified precondition chains for safety rules, and conducting more in-depth reasoning with cascaded chain-of-thought processes if necessary. Experiment results demonstrate that our method is highly effective for zero-shot image safety judgment tasks.
GAS: Generative Auto-bidding with Post-training Search
Dec 22, 2024



Auto-bidding is essential in facilitating online advertising by automatically placing bids on behalf of advertisers. Generative auto-bidding, which generates bids based on an adjustable condition using models like transformers and diffusers, has recently emerged as a new trend due to its potential to learn optimal strategies directly from data and adjust flexibly to preferences. However, generative models suffer from low-quality data leading to a mismatch between condition, return to go, and true action value, especially in long sequential decision-making. Besides, the majority preference in the dataset may hinder models' generalization ability on minority advertisers' preferences. While it is possible to collect high-quality data and retrain multiple models for different preferences, the high cost makes it unaffordable, hindering the advancement of auto-bidding into the era of large foundation models. To address this, we propose a flexible and practical Generative Auto-bidding scheme using post-training Search, termed GAS, to refine a base policy model's output and adapt to various preferences. We use weak-to-strong search alignment by training small critics for different preferences and an MCTS-inspired search to refine the model's output. Specifically, a novel voting mechanism with transformer-based critics trained with policy indications could enhance search alignment performance. Additionally, utilizing the search, we provide a fine-tuning method for high-frequency preference scenarios considering computational efficiency. Extensive experiments conducted on the real-world dataset and online A/B test on the Kuaishou advertising platform demonstrate the effectiveness of GAS, achieving significant improvements, e.g., 1.554% increment of target cost.
GameArena: Evaluating LLM Reasoning through Live Computer Games
Dec 09, 2024



Evaluating the reasoning abilities of large language models (LLMs) is challenging. Existing benchmarks often depend on static datasets, which are vulnerable to data contamination and may get saturated over time, or on binary live human feedback that conflates reasoning with other abilities. As the most prominent dynamic benchmark, Chatbot Arena evaluates open-ended questions in real-world settings, but lacks the granularity in assessing specific reasoning capabilities. We introduce GameArena, a dynamic benchmark designed to evaluate LLM reasoning capabilities through interactive gameplay with humans. GameArena consists of three games designed to test specific reasoning capabilities (e.g., deductive and inductive reasoning), while keeping participants entertained and engaged. We analyze the gaming data retrospectively to uncover the underlying reasoning processes of LLMs and measure their fine-grained reasoning capabilities. We collect over 2000 game sessions and provide detailed assessments of various reasoning capabilities for five state-of-the-art LLMs. Our user study with 100 participants suggests that GameArena improves user engagement compared to Chatbot Arena. For the first time, GameArena enables the collection of step-by-step LLM reasoning data in the wild.
Commit0: Library Generation from Scratch
Dec 02, 2024With the goal of benchmarking generative systems beyond expert software development ability, we introduce Commit0, a benchmark that challenges AI agents to write libraries from scratch. Agents are provided with a specification document outlining the library's API as well as a suite of interactive unit tests, with the goal of producing an implementation of this API accordingly. The implementation is validated through running these unit tests. As a benchmark, Commit0 is designed to move beyond static one-shot code generation towards agents that must process long-form natural language specifications, adapt to multi-stage feedback, and generate code with complex dependencies. Commit0 also offers an interactive environment where models receive static analysis and execution feedback on the code they generate. Our experiments demonstrate that while current agents can pass some unit tests, none can yet fully reproduce full libraries. Results also show that interactive feedback is quite useful for models to generate code that passes more unit tests, validating the benchmarks that facilitate its use.