 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect and Improve: Understanding the Mechanics of Post-Training for Reasoning
Jun 11, 2026Reinforcement learning has rapidly emerged as a key component in the training of reasoning and coding models, yet it remains poorly understood from a mechanistic perspective. We study how and through what underlying processes capabilities are acquired or enhanced via reinforcement learning post-training. Our analysis, based on controlled math reasoning experiments with Qwen-2.5-1.5B, reveals two core mechanisms: strategy selection and strategy improvement. Our results highlight the role of SFT data and reinforcement learning data in activating these mechanisms, in particular showing how supervising the model on diverse reasoning strategies can enable strategy selection and how increasing difficulty in reinforcement learning data can enable strategy improvement. Taken together, our results provide mechanistic insight into RL training and suggest practical interventions to continue scaling reasoning capabilities.
Learning to Reason with Curriculum I: Provable Benefits of Autocurriculum
Mar 18, 2026Chain-of-thought reasoning, where language models expend additional computation by producing thinking tokens prior to final responses, has driven significant advances in model capabilities. However, training these reasoning models is extremely costly in terms of both data and compute, as it involves collecting long traces of reasoning behavior from humans or synthetic generators and further post-training the model via reinforcement learning. Are these costs fundamental, or can they be reduced through better algorithmic design? We show that autocurriculum, where the model uses its own performance to decide which problems to focus training on, provably improves upon standard training recipes for both supervised fine-tuning (SFT) and reinforcement learning (RL). For SFT, we show that autocurriculum requires exponentially fewer reasoning demonstrations than non-adaptive fine-tuning, by focusing teacher supervision on prompts where the current model struggles. For RL fine-tuning, autocurriculum decouples the computational cost from the quality of the reference model, reducing the latter to a burn-in cost that is nearly independent of the target accuracy. These improvements arise purely from adaptive data selection, drawing on classical techniques from boosting and learning from counterexamples, and requiring no assumption on the distribution or difficulty of prompts.
A Unifying View of Coverage in Linear Off-Policy Evaluation
Jan 26, 2026Off-policy evaluation (OPE) is a fundamental task in reinforcement learning (RL). In the classic setting of linear OPE, finite-sample guarantees often take the form $$ \textrm{Evaluation error} \le \textrm{poly}(C^π, d, 1/n,\log(1/δ)), $$ where $d$ is the dimension of the features and $C^π$ is a coverage parameter that characterizes the degree to which the visited features lie in the span of the data distribution. While such guarantees are well-understood for several popular algorithms under stronger assumptions (e.g. Bellman completeness), the understanding is lacking and fragmented in the minimal setting where only the target value function is linearly realizable in the features. Despite recent interest in tight characterizations of the statistical rate in this setting, the right notion of coverage remains unclear, and candidate definitions from prior analyses have undesirable properties and are starkly disconnected from more standard definitions in the literature. We provide a novel finite-sample analysis of a canonical algorithm for this setting, LSTDQ. Inspired by an instrumental-variable view, we develop error bounds that depend on a novel coverage parameter, the feature-dynamics coverage, which can be interpreted as linear coverage in an induced dynamical system for feature evolution. With further assumptions -- such as Bellman-completeness -- our definition successfully recovers the coverage parameters specialized to those settings, finally yielding a unified understanding for coverage in linear OPE.
Is Best-of-N the Best of Them? Coverage, Scaling, and Optimality in Inference-Time Alignment
Mar 27, 2025



Inference-time computation provides an important axis for scaling language model performance, but naively scaling compute through techniques like Best-of-$N$ sampling can cause performance to degrade due to reward hacking. Toward a theoretical understanding of how to best leverage additional computation, we focus on inference-time alignment which we formalize as the problem of improving a pre-trained policy's responses for a prompt of interest, given access to an imperfect reward model. We analyze the performance of inference-time alignment algorithms in terms of (i) response quality, and (ii) compute, and provide new results that highlight the importance of the pre-trained policy's coverage over high-quality responses for performance and compute scaling: 1. We show that Best-of-$N$ alignment with an ideal choice for $N$ can achieve optimal performance under stringent notions of coverage, but provably suffers from reward hacking when $N$ is large, and fails to achieve tight guarantees under more realistic coverage conditions. 2. We introduce $\texttt{InferenceTimePessimism}$, a new algorithm which mitigates reward hacking through deliberate use of inference-time compute, implementing the principle of pessimism in the face of uncertainty via rejection sampling; we prove that its performance is optimal and does not degrade with $N$, meaning it is scaling-monotonic. We complement our theoretical results with an experimental evaluation that demonstrate the benefits of $\texttt{InferenceTimePessimism}$ across a variety of tasks and models.
Computational-Statistical Tradeoffs at the Next-Token Prediction Barrier: Autoregressive and Imitation Learning under Misspecification
Feb 18, 2025Next-token prediction with the logarithmic loss is a cornerstone of autoregressive sequence modeling, but, in practice, suffers from error amplification, where errors in the model compound and generation quality degrades as sequence length $H$ increases. From a theoretical perspective, this phenomenon should not appear in well-specified settings, and, indeed, a growing body of empirical work hypothesizes that misspecification, where the learner is not sufficiently expressive to represent the target distribution, may be the root cause. Under misspecification -- where the goal is to learn as well as the best-in-class model up to a multiplicative approximation factor $C\geq 1$ -- we confirm that $C$ indeed grows with $H$ for next-token prediction, lending theoretical support to this empirical hypothesis. We then ask whether this mode of error amplification is avoidable algorithmically, computationally, or information-theoretically, and uncover inherent computational-statistical tradeoffs. We show: (1) Information-theoretically, one can avoid error amplification and achieve $C=O(1)$. (2) Next-token prediction can be made robust so as to achieve $C=\tilde O(H)$, representing moderate error amplification, but this is an inherent barrier: any next-token prediction-style objective must suffer $C=\Omega(H)$. (3) For the natural testbed of autoregressive linear models, no computationally efficient algorithm can achieve sub-polynomial approximation factor $C=e^{(\log H)^{1-\Omega(1)}}$; however, at least for binary token spaces, one can smoothly trade compute for statistical power and improve on $C=\Omega(H)$ in sub-exponential time. Our results have consequences in the more general setting of imitation learning, where the widely-used behavior cloning algorithm generalizes next-token prediction.
Model Selection for Off-policy Evaluation: New Algorithms and Experimental Protocol
Feb 11, 2025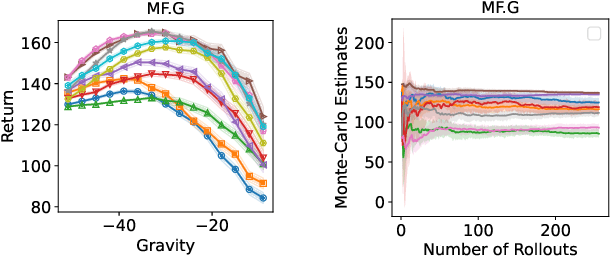

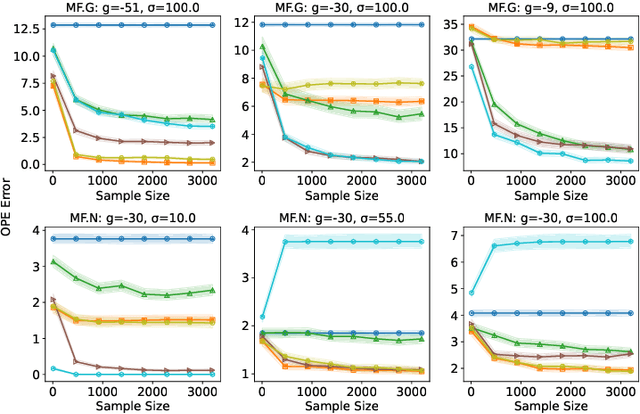
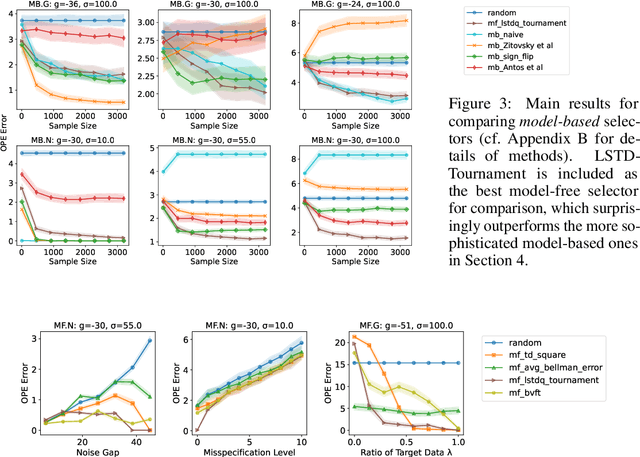
Holdout validation and hyperparameter tuning from data is a long-standing problem in offline reinforcement learning (RL). A standard framework is to use off-policy evaluation (OPE) methods to evaluate and select the policies, but OPE either incurs exponential variance (e.g., importance sampling) or has hyperparameters on their own (e.g., FQE and model-based). In this work we focus on hyperparameter tuning for OPE itself, which is even more under-investigated. Concretely, we select among candidate value functions ("model-free") or dynamics ("model-based") to best assess the performance of a target policy. Our contributions are two fold. We develop: (1) new model-free and model-based selectors with theoretical guarantees, and (2) a new experimental protocol for empirically evaluating them. Compared to the model-free protocol in prior works, our new protocol allows for more stable generation of candidate value functions, better control of misspecification, and evaluation of model-free and model-based methods alike. We exemplify the protocol on a Gym environment, and find that our new model-free selector, LSTD-Tournament, demonstrates promising empirical performance.
Self-Improvement in Language Models: The Sharpening Mechanism
Dec 02, 2024



Recent work in language modeling has raised the possibility of self-improvement, where a language models evaluates and refines its own generations to achieve higher performance without external feedback. It is impossible for this self-improvement to create information that is not already in the model, so why should we expect that this will lead to improved capabilities? We offer a new perspective on the capabilities of self-improvement through a lens we refer to as sharpening. Motivated by the observation that language models are often better at verifying response quality than they are at generating correct responses, we formalize self-improvement as using the model itself as a verifier during post-training in order to ``sharpen'' the model to one placing large mass on high-quality sequences, thereby amortizing the expensive inference-time computation of generating good sequences. We begin by introducing a new statistical framework for sharpening in which the learner aims to sharpen a pre-trained base policy via sample access, and establish fundamental limits. Then we analyze two natural families of self-improvement algorithms based on SFT and RLHF.
Correcting the Mythos of KL-Regularization: Direct Alignment without Overparameterization via Chi-squared Preference Optimization
Jul 18, 2024


Language model alignment methods, such as reinforcement learning from human feedback (RLHF), have led to impressive advances in language model capabilities, but existing techniques are limited by a widely observed phenomenon known as overoptimization, where the quality of the language model plateaus or degrades over the course of the alignment process. Overoptimization is often attributed to overfitting to an inaccurate reward model, and while it can be mitigated through online data collection, this is infeasible in many settings. This raises a fundamental question: Do existing offline alignment algorithms make the most of the data they have, or can their sample-efficiency be improved further? We address this question with a new algorithm for offline alignment, $\chi^2$-Preference Optimization ($\chi$PO). $\chi$PO is a one-line change to Direct Preference Optimization (DPO; Rafailov et al., 2023), which only involves modifying the logarithmic link function in the DPO objective. Despite this minimal change, $\chi$PO implicitly implements the principle of pessimism in the face of uncertainty via regularization with the $\chi^2$-divergence -- which quantifies uncertainty more effectively than KL-regularization -- and provably alleviates overoptimization, achieving sample-complexity guarantees based on single-policy concentrability -- the gold standard in offline reinforcement learning. $\chi$PO's simplicity and strong guarantees make it the first practical and general-purpose offline alignment algorithm that is provably robust to overoptimization.
Reinforcement Learning in Low-Rank MDPs with Density Features
Feb 04, 2023
MDPs with low-rank transitions -- that is, the transition matrix can be factored into the product of two matrices, left and right -- is a highly representative structure that enables tractable learning. The left matrix enables expressive function approximation for value-based learning and has been studied extensively. In this work, we instead investigate sample-efficient learning with density features, i.e., the right matrix, which induce powerful models for state-occupancy distributions. This setting not only sheds light on leveraging unsupervised learning in RL, but also enables plug-in solutions for convex RL. In the offline setting, we propose an algorithm for off-policy estimation of occupancies that can handle non-exploratory data. Using this as a subroutine, we further devise an online algorithm that constructs exploratory data distributions in a level-by-level manner. As a central technical challenge, the additive error of occupancy estimation is incompatible with the multiplicative definition of data coverage. In the absence of strong assumptions like reachability, this incompatibility easily leads to exponential error blow-up, which we overcome via novel technical tools. Our results also readily extend to the representation learning setting, when the density features are unknown and must be learned from an exponentially large candidate set.
Beyond the Return: Off-policy Function Estimation under User-specified Error-measuring Distributions
Oct 27, 2022Off-policy evaluation often refers to two related tasks: estimating the expected return of a policy and estimating its value function (or other functions of interest, such as density ratios). While recent works on marginalized importance sampling (MIS) show that the former can enjoy provable guarantees under realizable function approximation, the latter is only known to be feasible under much stronger assumptions such as prohibitively expressive discriminators. In this work, we provide guarantees for off-policy function estimation under only realizability, by imposing proper regularization on the MIS objectives. Compared to commonly used regularization in MIS, our regularizer is much more flexible and can account for an arbitrary user-specified distribution, under which the learned function will be close to the groundtruth. We provide exact characterization of the optimal dual solution that needs to be realized by the discriminator class, which determines the data-coverage assumption in the case of value-function learning. As another surprising observation, the regularizer can be altered to relax the data-coverage requirement, and completely eliminate it in the ideal case with strong side information.