 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Parameters: A Technical Survey of Contextual Enrichment in Large Language Models: From In-Context Prompting to Causal Retrieval-Augmented Generation
Apr 03, 2026Large language models (LLMs) encode vast world knowledge in their parameters, yet they remain fundamentally limited by static knowledge, finite context windows, and weakly structured causal reasoning. This survey provides a unified account of augmentation strategies along a single axis: the degree of structured context supplied at inference time. We cover in-context learning and prompt engineering, Retrieval-Augmented Generation (RAG), GraphRAG, and CausalRAG. Beyond conceptual comparison, we provide a transparent literature-screening protocol, a claim-audit framework, and a structured cross-paper evidence synthesis that distinguishes higher-confidence findings from emerging results. The paper concludes with a deployment-oriented decision framework and concrete research priorities for trustworthy retrieval-augmented NLP.
Lightweight Query Routing for Adaptive RAG: A Baseline Study on RAGRouter-Bench
Apr 03, 2026Retrieval-Augmented Generation pipelines span a wide range of retrieval strategies that differ substantially in token cost and capability. Selecting the right strategy per query is a practical efficiency problem, yet no routing classifiers have been trained on RAGRouter-Bench \citep{wang2026ragrouterbench}, a recently released benchmark of $7,727$ queries spanning four knowledge domains, each annotated with one of three canonical query types: factual, reasoning, and summarization. We present the first systematic evaluation of lightweight classifier-based routing on this benchmark. Five classical classifiers are evaluated under three feature regimes, namely, TF-IDF, MiniLM sentence embeddings \citep{reimers2019sbert}, and hand-crafted structural features, yielding 15 classifier feature combinations. Our best configuration, TF-IDF with an SVM, achieves a macro-averaged F1 of $\mathbf{0.928}$ and an accuracy of $\mathbf{93.2\%}$, while simulating $\mathbf{28.1\%}$ token savings relative to always using the most expensive paradigm. Lexical TF-IDF features outperform semantic sentence embeddings by $3.1$ macro-F1 points, suggesting that surface keyword patterns are strong predictors of query-type complexity. Domain-level analysis reveals that medical queries are hardest to route and legal queries most tractable. These results establish a reproducible query-side baseline and highlight the gap that corpus-aware routing must close.
Model Selection for Off-policy Evaluation: New Algorithms and Experimental Protocol
Feb 11, 2025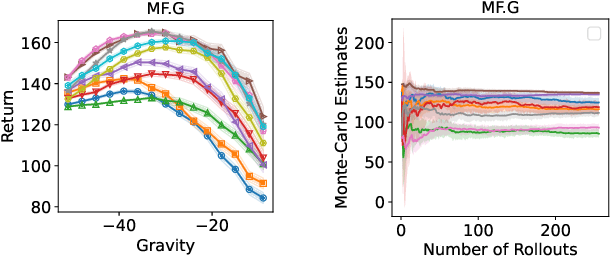

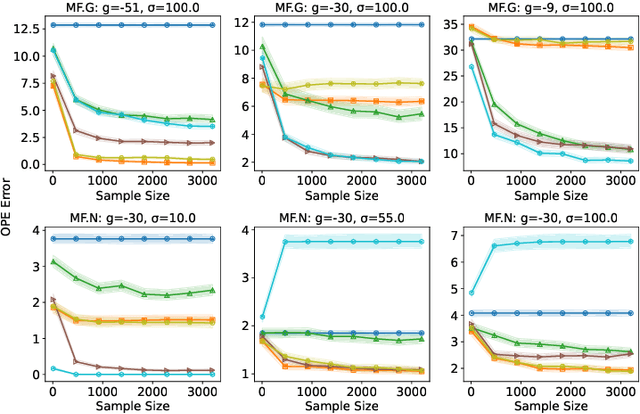
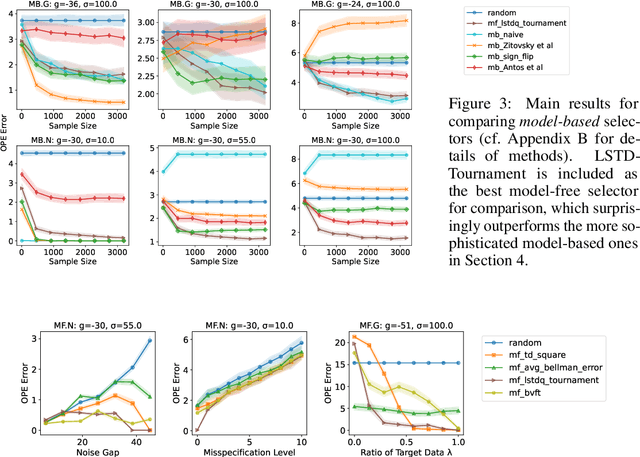
Holdout validation and hyperparameter tuning from data is a long-standing problem in offline reinforcement learning (RL). A standard framework is to use off-policy evaluation (OPE) methods to evaluate and select the policies, but OPE either incurs exponential variance (e.g., importance sampling) or has hyperparameters on their own (e.g., FQE and model-based). In this work we focus on hyperparameter tuning for OPE itself, which is even more under-investigated. Concretely, we select among candidate value functions ("model-free") or dynamics ("model-based") to best assess the performance of a target policy. Our contributions are two fold. We develop: (1) new model-free and model-based selectors with theoretical guarantees, and (2) a new experimental protocol for empirically evaluating them. Compared to the model-free protocol in prior works, our new protocol allows for more stable generation of candidate value functions, better control of misspecification, and evaluation of model-free and model-based methods alike. We exemplify the protocol on a Gym environment, and find that our new model-free selector, LSTD-Tournament, demonstrates promising empirical performance.
Learning Estimates At The Edge Using Intermittent And Aged Measurement Updates
Jan 20, 2022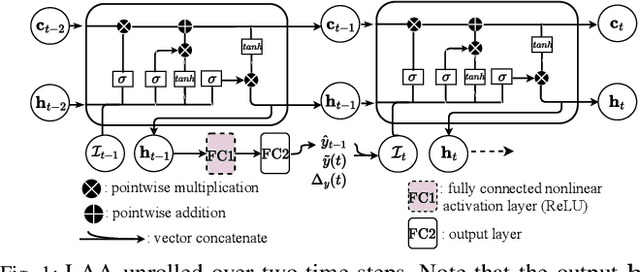
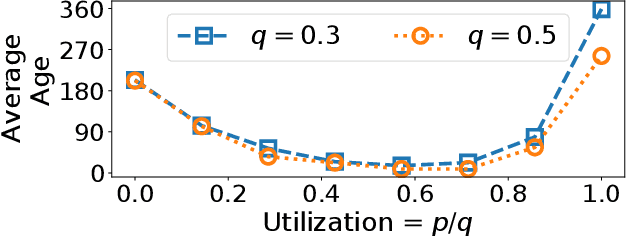
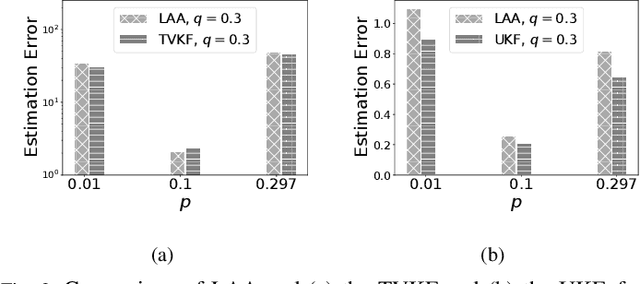
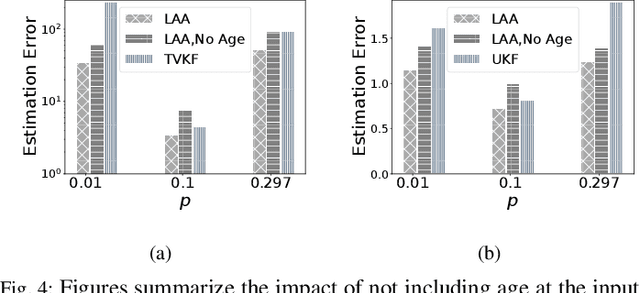
Cyber Physical Systems (CPS) applications have agents that actuate in their local vicinity, while requiring measurements that capture the state of their larger environment to make actuation choices. These measurements are made by sensors and communicated over a network as update packets. Network resource constraints dictate that updates arrive at an agent intermittently and be aged on their arrival. This can be alleviated by providing an agent with a fast enough rate of estimates of the measurements. Often works on estimation assume knowledge of the dynamic model of the system being measured. However, as CPS applications become pervasive, such information may not be available in practice. In this work, we propose a novel deep neural network architecture that leverages Long Short Term Memory (LSTM) networks to learn estimates in a model-free setting using only updates received over the network. We detail an online algorithm that enables training of our architecture. The architecture is shown to provide good estimates of measurements of both a linear and a non-linear dynamic system. It learns good estimates even when the learning proceeds over a generic network setting in which the distributions that govern the rate and age of received measurements may change significantly over time. We demonstrate the efficacy of the architecture by comparing it with the baselines of the Time-varying Kalman Filter and the Unscented Kalman Filter. The architecture enables empirical insights with regards to maintaining the ages of updates at the estimator, which are used by it and also the baselines.