 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
Jun 25, 2026Speculative decoding (SD) accelerates autoregressive Large Language Models (LLMs) by drafting multiple tokens and verifying them in parallel, but it faces a scaling limitation: increasing the draft budget improves speed only when acceptance remains high and drafting overhead stays low. This ceiling has been difficult to break because prior head-based SD methods face a causality-efficiency dilemma. Autoregressive drafters produce path-conditioned candidates that are effective for tree speculative decoding with higher acceptance length, but their drafting cost grows with tree depth. Bidirectional block-diffusion drafters generate all positions in one pass, but their branch-agnostic marginals can form individually plausible yet mutually inconsistent trees, wasting budget and reducing acceptance. We propose JetSpec, a head-based SD framework that combines one-forward drafting efficiency with branch-wise causal conditioning. JetSpec trains a causal parallel draft head over fused hidden states from the frozen target model, producing candidate trees whose scores align with the target model's autoregressive factorization. This enables JetSpec to convert larger draft budgets into longer accepted prefixes and higher end-to-end speedup. Across math, coding, and chat benchmarks on dense and MoE Qwen3 models, JetSpec consistently outperforms bidirectional-head and tree-based SD baselines. On H100 GPUs, JetSpec achieves up to 9.64x speedup on MATH-500 and 4.58x on open-ended conversational workloads, with further latency gains demonstrated through vLLM integration under realistic serving loads. Our code and models are available at https://github.com/hao-ai-lab/JetSpec.
JetFlow: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
Jun 16, 2026Speculative decoding (SD) accelerates autoregressive Large Language Models (LLMs) by drafting multiple tokens and verifying them in parallel, but it faces a scaling limitation: increasing the draft budget improves speed only when acceptance remains high and drafting overhead stays low. This ceiling has been difficult to break because prior head-based SD methods face a causality-efficiency dilemma. Autoregressive drafters produce path-conditioned candidates that are effective for tree speculative decoding with higher acceptance length, but their drafting cost grows with tree depth. Bidirectional block-diffusion drafters generate all positions in one pass, but their branch-agnostic marginals can form individually plausible yet mutually inconsistent trees, wasting budget and reducing acceptance. We propose JetFlow, a head-based SD framework that combines one-forward drafting efficiency with branch-wise causal conditioning. JetFlow trains a causal parallel draft head over fused hidden states from the frozen target model, producing candidate trees whose scores align with the target model's autoregressive factorization. This enables JetFlow to convert larger draft budgets into longer accepted prefixes and higher end-to-end speedup. Across math, coding, and chat benchmarks on dense and MoE Qwen3 models, JetFlow consistently outperforms bidirectional-head and tree-based SD baselines. On H100 GPUs, JetFlow achieves up to 9.64x speedup on MATH-500 and 4.58x on open-ended conversational workloads, with further latency gains demonstrated through vLLM integration under realistic serving loads. Our code and models are available at https://github.com/hao-ai-lab/JetFlow.
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications
Feb 26, 2026Large Language Models (LLMs) are deployed as autonomous agents in increasingly complex applications, where enabling long-horizon memory is critical for achieving strong performance. However, a significant gap exists between practical applications and current evaluation standards for agent memory: existing benchmarks primarily focus on dialogue-centric, human-agent interactions. In reality, agent memory consists of a continuous stream of agent-environment interactions that are primarily composed of machine-generated representations. To bridge this gap, we introduce AMA-Bench (Agent Memory with Any length), which evaluates long-horizon memory for LLMs in real agentic applications. It features two key components: (1) a set of real-world agentic trajectories across representative agentic applications, paired with expert-curated QA, and (2) a set of synthetic agentic trajectories that scale to arbitrary horizons, paired with rule-based QA. Our comprehensive study shows that existing memory systems underperform on AMA-Bench primarily because they lack causality and objective information and are constrained by the lossy nature of similarity-based retrieval employed by many memory systems. To address these limitations, we propose AMA-Agent, an effective memory system featuring a causality graph and tool-augmented retrieval. Our results demonstrate that AMA-Agent achieves 57.22% average accuracy on AMA-Bench, surpassing the strongest memory system baselines by 11.16%.
d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation
Jan 12, 2026Diffusion large language models (dLLMs) offer capabilities beyond those of autoregressive (AR) LLMs, such as parallel decoding and random-order generation. However, realizing these benefits in practice is non-trivial, as dLLMs inherently face an accuracy-parallelism trade-off. Despite increasing interest, existing methods typically focus on only one-side of the coin, targeting either efficiency or performance. To address this limitation, we propose d3LLM (Pseudo-Distilled Diffusion Large Language Model), striking a balance between accuracy and parallelism: (i) during training, we introduce pseudo-trajectory distillation to teach the model which tokens can be decoded confidently at early steps, thereby improving parallelism; (ii) during inference, we employ entropy-based multi-block decoding with a KV-cache refresh mechanism to achieve high parallelism while maintaining accuracy. To better evaluate dLLMs, we also introduce AUP (Accuracy Under Parallelism), a new metric that jointly measures accuracy and parallelism. Experiments demonstrate that our d3LLM achieves up to 10$\times$ speedup over vanilla LLaDA/Dream and 5$\times$ speedup over AR models without much accuracy drop. Our code is available at https://github.com/hao-ai-lab/d3LLM.
Fast and Accurate Causal Parallel Decoding using Jacobi Forcing
Dec 16, 2025Multi-token generation has emerged as a promising paradigm for accelerating transformer-based large model inference. Recent efforts primarily explore diffusion Large Language Models (dLLMs) for parallel decoding to reduce inference latency. To achieve AR-level generation quality, many techniques adapt AR models into dLLMs to enable parallel decoding. However, they suffer from limited speedup compared to AR models due to a pretrain-to-posttrain mismatch. Specifically, the masked data distribution in post-training deviates significantly from the real-world data distribution seen during pretraining, and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse. To address this, we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories, smoothly shifting AR models into efficient parallel decoders while preserving their pretrained causal inference property. The models trained under this paradigm, Jacobi Forcing Model, achieves 3.8x wall-clock speedup on coding and math benchmarks with minimal loss in performance. Based on Jacobi Forcing Models' trajectory characteristics, we introduce multi-block decoding with rejection recycling, which enables up to 4.5x higher token acceptance count per iteration and nearly 4.0x wall-clock speedup, effectively trading additional compute for lower inference latency. Our code is available at https://github.com/hao-ai-lab/JacobiForcing.
Towards Interpretable and Inference-Optimal COT Reasoning with Sparse Autoencoder-Guided Generation
Oct 02, 2025

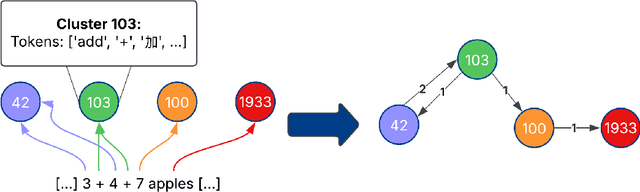

We propose a novel method that leverages sparse autoencoders (SAEs) and clustering techniques to analyze the internal token representations of large language models (LLMs) and guide generations in mathematical reasoning tasks. Our approach first trains an SAE to generate sparse vector representations for training tokens, then applies k-means clustering to construct a graph where vertices represent token clusters and weighted edges capture sequential token transitions. Using this graph, we define an edge-weight based reward function to quantify adherence to established reasoning traces, thereby identifying exploitative reasoning trajectories. Additionally, we measure generation diversity from clustering to assess the extent of exploration. Our findings indicate that balancing both exploitation and exploration is crucial for achieving high accuracy in mathematical reasoning tasks. During generation, the SAE can serve as a scalable reward model to guide generations, ensuring a balanced trade-off between exploitation and exploration. This prevents extreme behaviors in either direction, ultimately fostering a higher-quality reasoning process in LLMs.
General Modular Harness for LLM Agents in Multi-Turn Gaming Environments
Jul 15, 2025We introduce a modular harness design for LLM agents that composes of perception, memory, and reasoning components, enabling a single LLM or VLM backbone to tackle a wide spectrum of multi turn gaming environments without domain-specific engineering. Using classic and modern game suites as low-barrier, high-diversity testbeds, our framework provides a unified workflow for analyzing how each module affects performance across dynamic interactive settings. Extensive experiments demonstrate that the harness lifts gameplay performance consistently over un-harnessed baselines and reveals distinct contribution patterns, for example, memory dominates in long-horizon puzzles while perception is critical in vision noisy arcades. These findings highlight the effectiveness of our modular harness design in advancing general-purpose agent, given the familiarity and ubiquity of games in everyday human experience.
lmgame-Bench: How Good are LLMs at Playing Games?
May 21, 2025Playing video games requires perception, memory, and planning, exactly the faculties modern large language model (LLM) agents are expected to master. We study the major challenges in using popular video games to evaluate modern LLMs and find that directly dropping LLMs into games cannot make an effective evaluation, for three reasons -- brittle vision perception, prompt sensitivity, and potential data contamination. We introduce lmgame-Bench to turn games into reliable evaluations. lmgame-Bench features a suite of platformer, puzzle, and narrative games delivered through a unified Gym-style API and paired with lightweight perception and memory scaffolds, and is designed to stabilize prompt variance and remove contamination. Across 13 leading models, we show lmgame-Bench is challenging while still separating models well. Correlation analysis shows that every game probes a unique blend of capabilities often tested in isolation elsewhere. More interestingly, performing reinforcement learning on a single game from lmgame-Bench transfers both to unseen games and to external planning tasks. Our evaluation code is available at https://github.com/lmgame-org/GamingAgent/lmgame-bench.
SensorChat: Answering Qualitative and Quantitative Questions during Long-Term Multimodal Sensor Interactions
Feb 05, 2025Natural language interaction with sensing systems is crucial for enabling all users to comprehend sensor data and its impact on their everyday lives. However, existing systems, which typically operate in a Question Answering (QA) manner, are significantly limited in terms of the duration and complexity of sensor data they can handle. In this work, we introduce SensorChat, the first end-to-end QA system designed for long-term sensor monitoring with multimodal and high-dimensional data including time series. SensorChat effectively answers both qualitative (requiring high-level reasoning) and quantitative (requiring accurate responses derived from sensor data) questions in real-world scenarios. To achieve this, SensorChat uses an innovative three-stage pipeline that includes question decomposition, sensor data query, and answer assembly. The first and third stages leverage Large Language Models (LLMs) for intuitive human interactions and to guide the sensor data query process. Unlike existing multimodal LLMs, SensorChat incorporates an explicit query stage to precisely extract factual information from long-duration sensor data. We implement SensorChat and demonstrate its capability for real-time interactions on a cloud server while also being able to run entirely on edge platforms after quantization. Comprehensive QA evaluations show that SensorChat achieves up to 26% higher answer accuracy than state-of-the-art systems on quantitative questions. Additionally, a user study with eight volunteers highlights SensorChat's effectiveness in handling qualitative and open-ended questions.
SensorQA: A Question Answering Benchmark for Daily-Life Monitoring
Jan 10, 2025



With the rapid growth in sensor data, effectively interpreting and interfacing with these data in a human-understandable way has become crucial. While existing research primarily focuses on learning classification models, fewer studies have explored how end users can actively extract useful insights from sensor data, often hindered by the lack of a proper dataset. To address this gap, we introduce SensorQA, the first human-created question-answering (QA) dataset for long-term time-series sensor data for daily life monitoring. SensorQA is created by human workers and includes 5.6K diverse and practical queries that reflect genuine human interests, paired with accurate answers derived from sensor data. We further establish benchmarks for state-of-the-art AI models on this dataset and evaluate their performance on typical edge devices. Our results reveal a gap between current models and optimal QA performance and efficiency, highlighting the need for new contributions. The dataset and code are available at: \url{https://github.com/benjamin-reichman/SensorQA}.