 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoBERT: Self-Supervised Speech Representation Learning Through Code Representation Learning
Oct 08, 2022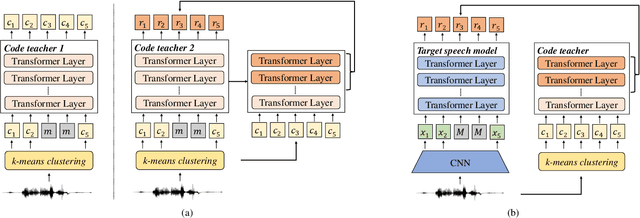
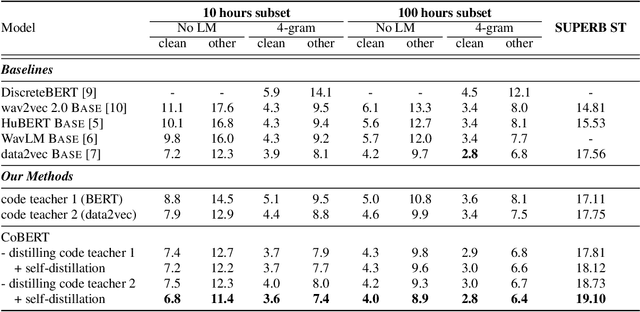
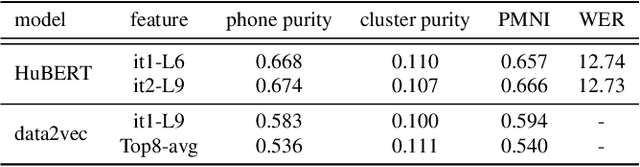
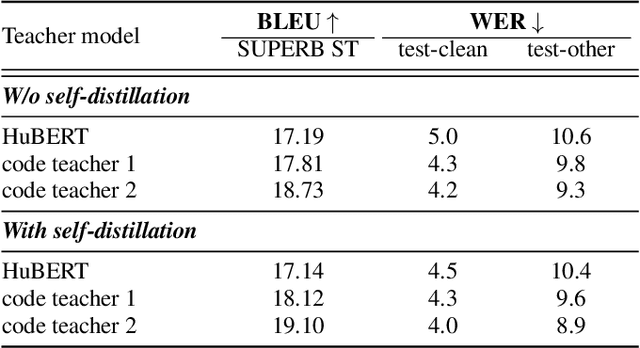
Speech is the surface form of a finite set of phonetic units, which can be represented by discrete codes. We propose the Code BERT (CoBERT) approach for self-supervised speech representation learning. The idea is to convert an utterance to a sequence of discrete codes, and perform code representation learning, where we predict the code representations based on a masked view of the original speech input. Unlike the prior self-distillation approaches of which the teacher and the student are of the same modality, our target model predicts representations from a different modality. CoBERT outperforms the most recent state-of-the-art performance on the ASR task and brings significant improvements on the SUPERB speech translation (ST) task.
PARAGEN : A Parallel Generation Toolkit
Oct 07, 2022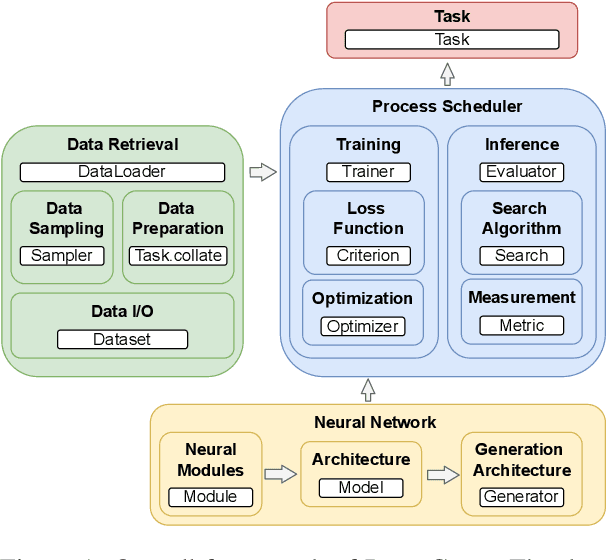

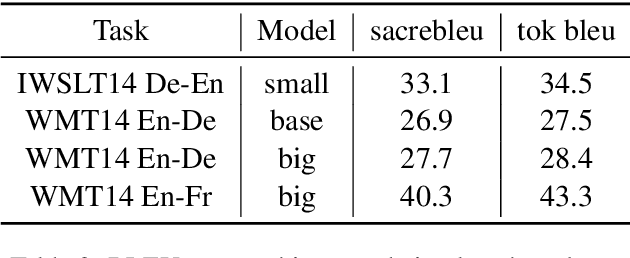
PARAGEN is a PyTorch-based NLP toolkit for further development on parallel generation. PARAGEN provides thirteen types of customizable plugins, helping users to experiment quickly with novel ideas across model architectures, optimization, and learning strategies. We implement various features, such as unlimited data loading and automatic model selection, to enhance its industrial usage. ParaGen is now deployed to support various research and industry applications at ByteDance. PARAGEN is available at https://github.com/bytedance/ParaGen.
Zero-shot Domain Adaptation for Neural Machine Translation with Retrieved Phrase-level Prompts
Sep 23, 2022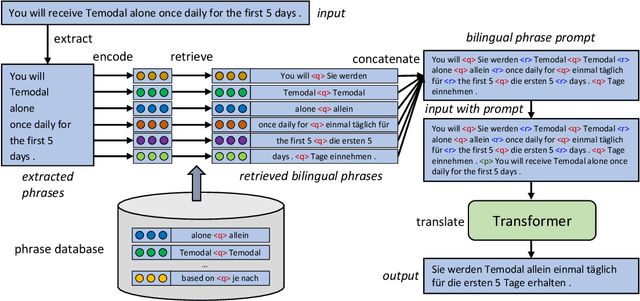

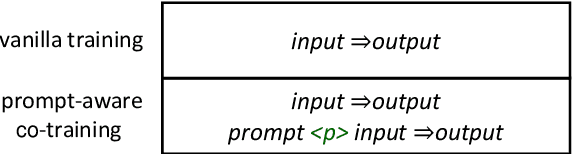

Domain adaptation is an important challenge for neural machine translation. However, the traditional fine-tuning solution requires multiple extra training and yields a high cost. In this paper, we propose a non-tuning paradigm, resolving domain adaptation with a prompt-based method. Specifically, we construct a bilingual phrase-level database and retrieve relevant pairs from it as a prompt for the input sentences. By utilizing Retrieved Phrase-level Prompts (RePP), we effectively boost the translation quality. Experiments show that our method improves domain-specific machine translation for 6.2 BLEU scores and improves translation constraints for 11.5% accuracy without additional training.
Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation
May 18, 2022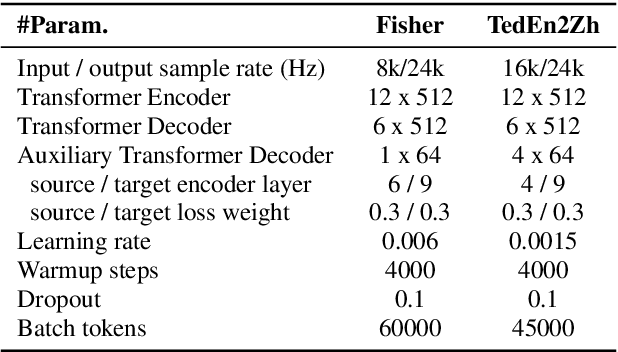
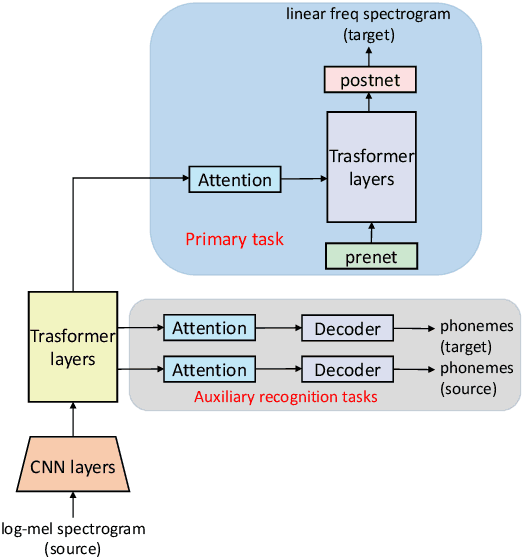
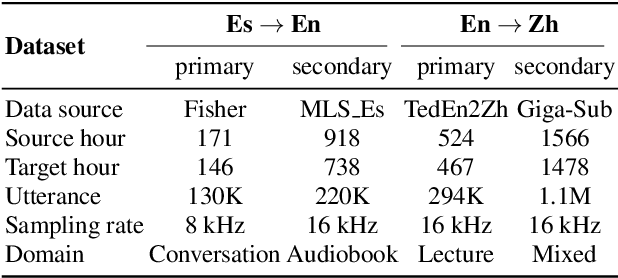
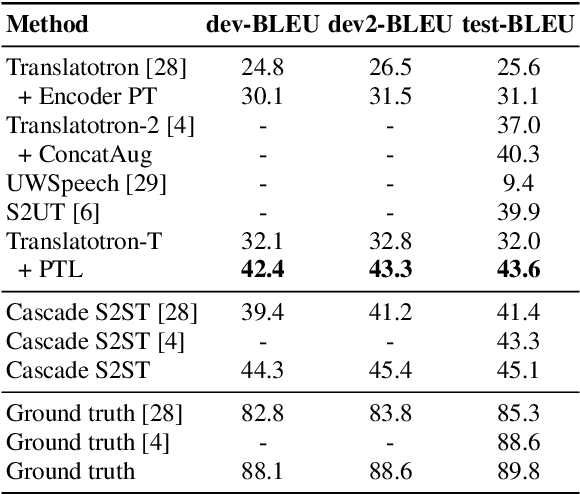
Direct Speech-to-speech translation (S2ST) has drawn more and more attention recently. The task is very challenging due to data scarcity and complex speech-to-speech mapping. In this paper, we report our recent achievements in S2ST. Firstly, we build a S2ST Transformer baseline which outperforms the original Translatotron. Secondly, we utilize the external data by pseudo-labeling and obtain a new state-of-the-art result on the Fisher English-to-Spanish test set. Indeed, we exploit the pseudo data with a combination of popular techniques which are not trivial when applied to S2ST. Moreover, we evaluate our approach on both syntactically similar (Spanish-English) and distant (English-Chinese) language pairs. Our implementation is available at https://github.com/fengpeng-yue/speech-to-speech-translation.
Cross-modal Contrastive Learning for Speech Translation
May 05, 2022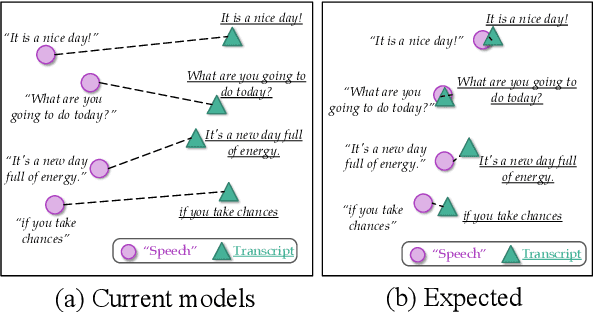
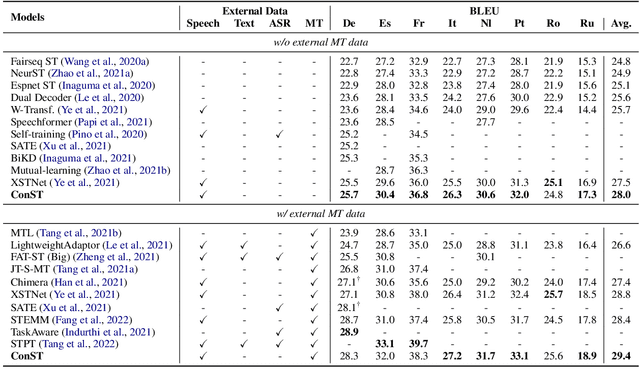
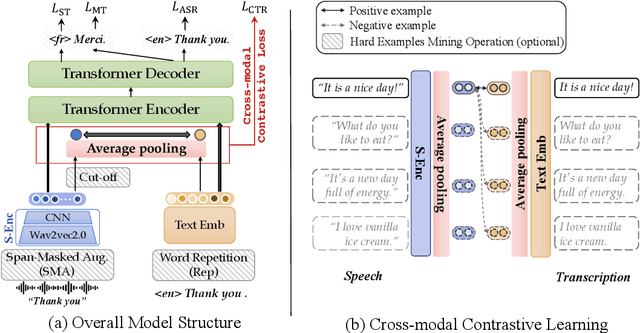
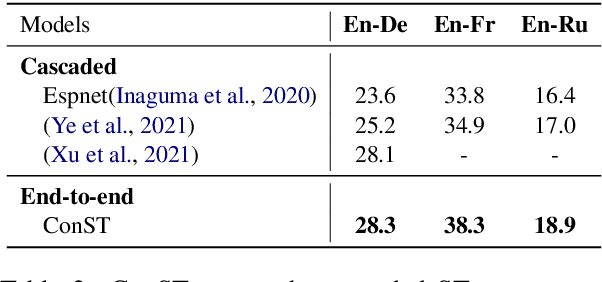
How can we learn unified representations for spoken utterances and their written text? Learning similar representations for semantically similar speech and text is important for speech translation. To this end, we propose ConST, a cross-modal contrastive learning method for end-to-end speech-to-text translation. We evaluate ConST and a variety of previous baselines on a popular benchmark MuST-C. Experiments show that the proposed ConST consistently outperforms the previous methods on, and achieves an average BLEU of 29.4. The analysis further verifies that ConST indeed closes the representation gap of different modalities -- its learned representation improves the accuracy of cross-modal speech-text retrieval from 4% to 88%. Code and models are available at https://github.com/ReneeYe/ConST.
GigaST: A 10,000-hour Pseudo Speech Translation Corpus
Apr 08, 2022
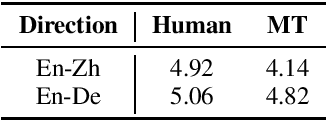
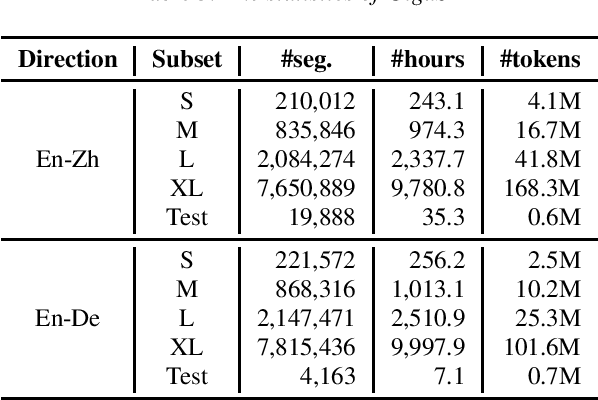
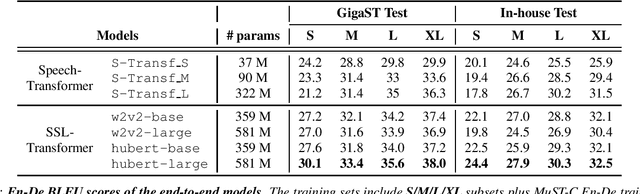
This paper introduces GigaST, a large-scale pseudo speech translation (ST) corpus. We create the corpus by translating the text in GigaSpeech, an English ASR corpus, into German and Chinese. The training set is translated by a strong machine translation system and the test set is translated by human. ST models trained with an addition of our corpus obtain new state-of-the-art results on the MuST-C English-German benchmark test set. We provide a detailed description of the translation process and verify its quality. We make the translated text data public and hope to facilitate research in speech translation. Additionally, we also release the training scripts on NeurST to make it easy to replicate our systems. GigaST dataset is available at https://st-benchmark.github.io/resources/GigaST.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation
Mar 20, 2022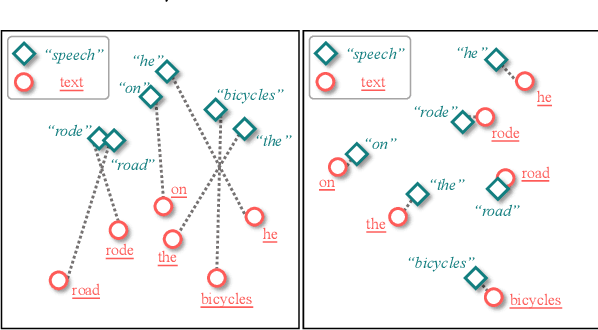
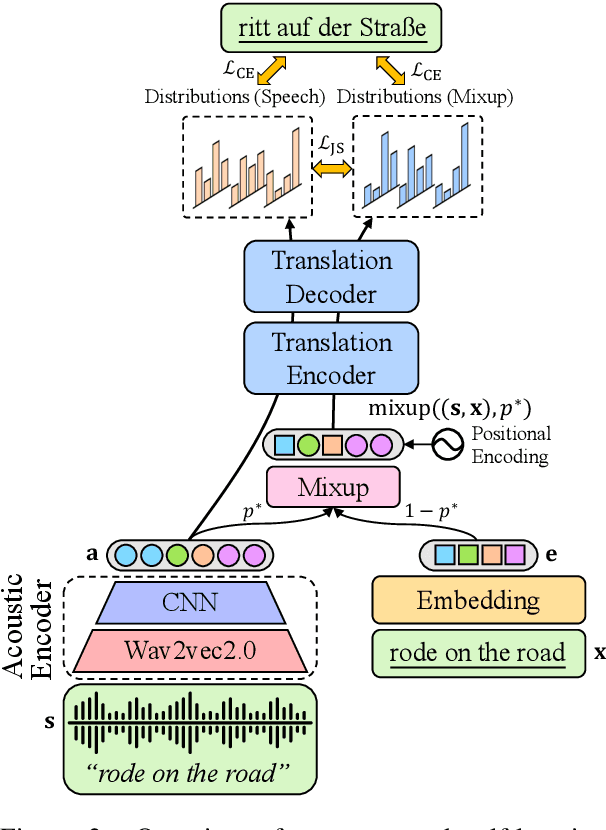
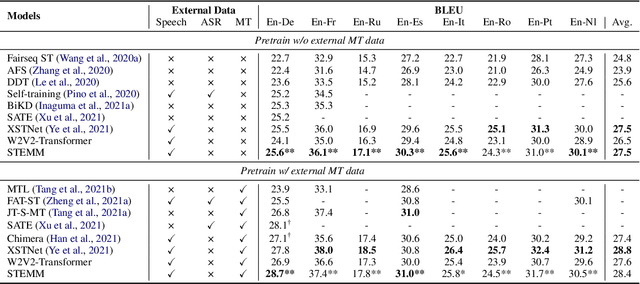
How to learn a better speech representation for end-to-end speech-to-text translation (ST) with limited labeled data? Existing techniques often attempt to transfer powerful machine translation (MT) capabilities to ST, but neglect the representation discrepancy across modalities. In this paper, we propose the Speech-TExt Manifold Mixup (STEMM) method to calibrate such discrepancy. Specifically, we mix up the representation sequences of different modalities, and take both unimodal speech sequences and multimodal mixed sequences as input to the translation model in parallel, and regularize their output predictions with a self-learning framework. Experiments on MuST-C speech translation benchmark and further analysis show that our method effectively alleviates the cross-modal representation discrepancy, and achieves significant improvements over a strong baseline on eight translation directions.
Unified Multimodal Punctuation Restoration Framework for Mixed-Modality Corpus
Jan 24, 2022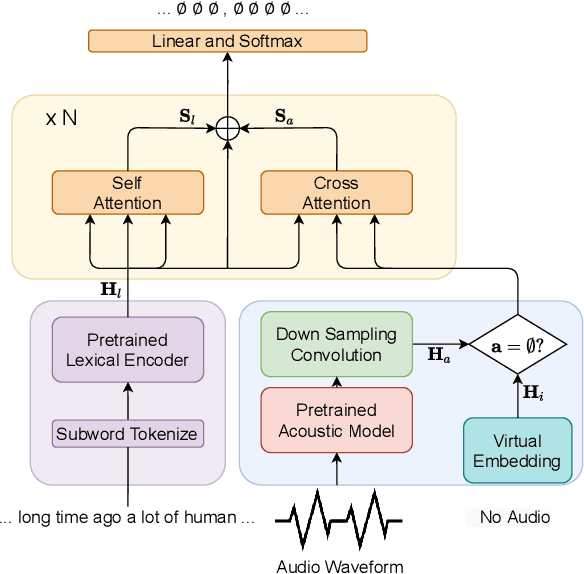
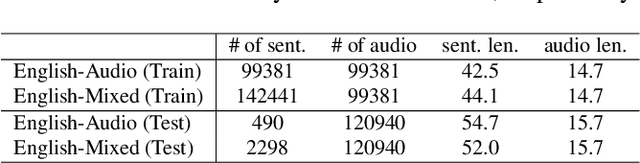
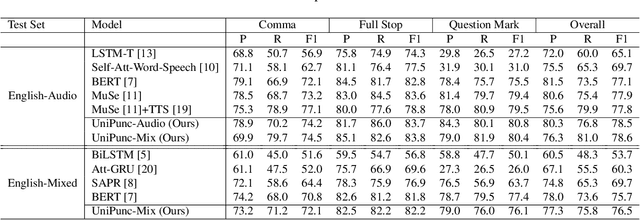
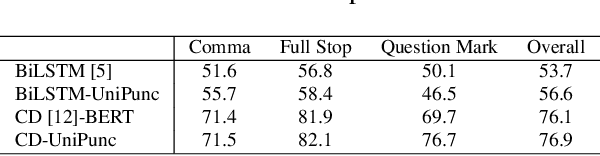
The punctuation restoration task aims to correctly punctuate the output transcriptions of automatic speech recognition systems. Previous punctuation models, either using text only or demanding the corresponding audio, tend to be constrained by real scenes, where unpunctuated sentences are a mixture of those with and without audio. This paper proposes a unified multimodal punctuation restoration framework, named UniPunc, to punctuate the mixed sentences with a single model. UniPunc jointly represents audio and non-audio samples in a shared latent space, based on which the model learns a hybrid representation and punctuates both kinds of samples. We validate the effectiveness of the UniPunc on real-world datasets, which outperforms various strong baselines (e.g. BERT, MuSe) by at least 0.8 overall F1 scores, making a new state-of-the-art. Extensive experiments show that UniPunc's design is a pervasive solution: by grafting onto previous models, UniPunc enables them to punctuate on the mixed corpus. Our code is available at github.com/Yaoming95/UniPunc
LightSeq2: Accelerated Training for Transformer-based Models on GPUs
Oct 27, 2021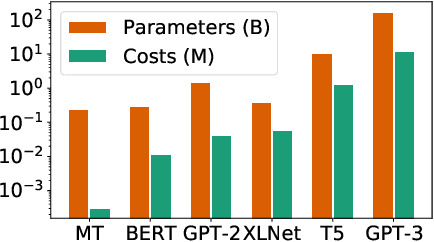

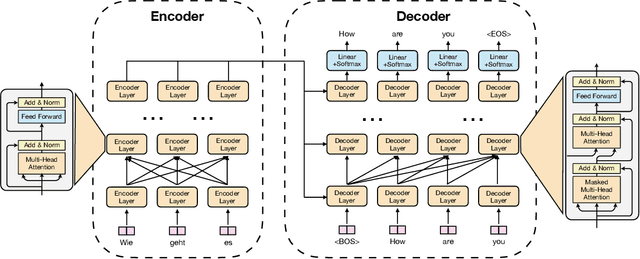
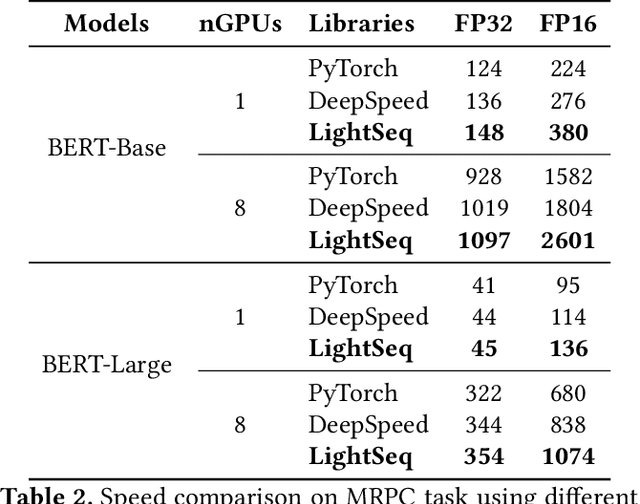
Transformer-based models have proven to be powerful in many natural language, computer vision, and speech recognition applications. It is expensive to train these types of models due to unfixed input length, complex computation, and large numbers of parameters. Existing systems either only focus on efficient inference or optimize only BERT-like encoder models. In this paper, we present LightSeq2, a system for efficient training of Transformer-based models on GPUs. We propose a series of GPU optimization techniques tailored to computation flow and memory access patterns of neural layers in Transformers. LightSeq2 supports a variety of network architectures, including BERT (encoder-only), GPT (decoder-only), and Transformer (encoder-decoder). Our experiments on GPUs with varying models and datasets show that LightSeq2 is 1.4-3.5x faster than previous systems. In particular, it gains 308% training speedup compared with existing systems on a large public machine translation benchmark (WMT14 English-German).