 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging What the Model Thinks and How It Speaks: Self-Aware Speech Language Models for Expressive Speech Generation
Apr 13, 2026Speech Language Models (SLMs) exhibit strong semantic understanding, yet their generated speech often sounds flat and fails to convey expressive intent, undermining user engagement. We term this mismatch the semantic understanding-acoustic realization gap. We attribute this gap to two key deficiencies: (1) intent transmission failure, where SLMs fail to provide the stable utterance-level intent needed for expressive delivery; and (2) realization-unaware training, where no feedback signal verifies whether acoustic outputs faithfully reflect intended expression. To address these issues, we propose SA-SLM (Self-Aware Speech Language Model), built on the principle that the model should be aware of what it thinks during generation and how it speaks during training. SA-SLM addresses this gap through two core contributions: (1) Intent-Aware Bridging, which uses a Variational Information Bottleneck (VIB) objective to translate the model's internal semantics into temporally smooth expressive intent, making speech generation aware of what the model intends to express; and (2) Realization-Aware Alignment, which repurposes the model as its own critic to verify and align acoustic realization with intended expressive intent via rubric-based feedback. Trained on only 800 hours of expressive speech data, our 3B parameter SA-SLM surpasses all open-source baselines and comes within 0.08 points of GPT-4o-Audio in overall expressiveness on the EchoMind benchmark.
Controllable Accent Normalization via Discrete Diffusion
Mar 15, 2026Existing accent normalization methods do not typically offer control over accent strength, yet many applications-such as language learning and dubbing-require tunable accent retention. We propose DLM-AN, a controllable accent normalization system built on masked discrete diffusion over self-supervised speech tokens. A Common Token Predictor identifies source tokens that likely encode native pronunciation; these tokens are selectively reused to initialize the reverse diffusion process. This provides a simple yet effective mechanism for controlling accent strength: reusing more tokens preserves more of the original accent. DLM-AN further incorporates a flow-matching Duration Ratio Predictor that automatically adjusts the total duration to better match the native rhythm. Experiments on multi-accent English data show that DLM-AN achieves the lowest word error rate among all compared systems while delivering competitive accent reduction and smooth, interpretable accent strength control.
CosyAccent: Duration-Controllable Accent Normalization Using Source-Synthesis Training Data
Feb 22, 2026Accent normalization (AN) systems often struggle with unnatural outputs and undesired content distortion, stemming from both suboptimal training data and rigid duration modeling. In this paper, we propose a "source-synthesis" methodology for training data construction. By generating source L2 speech and using authentic native speech as the training target, our approach avoids learning from TTS artifacts and, crucially, requires no real L2 data in training. Alongside this data strategy, we introduce CosyAccent, a non-autoregressive model that resolves the trade-off between prosodic naturalness and duration control. CosyAccent implicitly models rhythm for flexibility yet offers explicit control over total output duration. Experiments show that, despite being trained without any real L2 speech, CosyAccent achieves significantly improved content preservation and superior naturalness compared to strong baselines trained on real-world data.
Accent Normalization Using Self-Supervised Discrete Tokens with Non-Parallel Data
Jul 23, 2025Accent normalization converts foreign-accented speech into native-like speech while preserving speaker identity. We propose a novel pipeline using self-supervised discrete tokens and non-parallel training data. The system extracts tokens from source speech, converts them through a dedicated model, and synthesizes the output using flow matching. Our method demonstrates superior performance over a frame-to-frame baseline in naturalness, accentedness reduction, and timbre preservation across multiple English accents. Through token-level phonetic analysis, we validate the effectiveness of our token-based approach. We also develop two duration preservation methods, suitable for applications such as dubbing.
LLaST: Improved End-to-end Speech Translation System Leveraged by Large Language Models
Jul 22, 2024



We introduces LLaST, a framework for building high-performance Large Language model based Speech-to-text Translation systems. We address the limitations of end-to-end speech translation(E2E ST) models by exploring model architecture design and optimization techniques tailored for LLMs. Our approach includes LLM-based speech translation architecture design, ASR-augmented training, multilingual data augmentation, and dual-LoRA optimization. Our approach demonstrates superior performance on the CoVoST-2 benchmark and showcases exceptional scaling capabilities powered by LLMs. We believe this effective method will serve as a strong baseline for speech translation and provide insights for future improvements of the LLM-based speech translation framework. We release the data, code and models in https://github.com/openaudiolab/LLaST.
Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
Jun 08, 2024Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokenization often poses a necessary compromise between code bitrate and reconstruction accuracy. When dealing with low-bitrate audio codes, language models are constrained to process only a subset of the information embedded in the audio, which in turn restricts their generative capabilities. To circumvent these issues, we propose encoding audio as vector sequences in continuous space $\mathbb R^d$ and autoregressively generating these sequences using a decoder-only diffusion transformer (ARDiT). Our findings indicate that ARDiT excels in zero-shot text-to-speech and exhibits performance that compares to or even surpasses that of state-of-the-art models. High-bitrate continuous speech representation enables almost flawless reconstruction, allowing our model to achieve nearly perfect speech editing. Our experiments reveal that employing Integral Kullback-Leibler (IKL) divergence for distillation at each autoregressive step significantly boosts the perceived quality of the samples. Simultaneously, it condenses the iterative sampling process of the diffusion model into a single step. Furthermore, ARDiT can be trained to predict several continuous vectors in one step, significantly reducing latency during sampling. Impressively, one of our models can generate $170$ ms of $24$ kHz speech per evaluation step with minimal degradation in performance. Audio samples are available at http://ardit-tts.github.io/ .
Leveraging In-the-Wild Data for Effective Self-Supervised Pretraining in Speaker Recognition
Sep 27, 2023Current speaker recognition systems primarily rely on supervised approaches, constrained by the scale of labeled datasets. To boost the system performance, researchers leverage large pretrained models such as WavLM to transfer learned high-level features to the downstream speaker recognition task. However, this approach introduces extra parameters as the pretrained model remains in the inference stage. Another group of researchers directly apply self-supervised methods such as DINO to speaker embedding learning, yet they have not explored its potential on large-scale in-the-wild datasets. In this paper, we present the effectiveness of DINO training on the large-scale WenetSpeech dataset and its transferability in enhancing the supervised system performance on the CNCeleb dataset. Additionally, we introduce a confidence-based data filtering algorithm to remove unreliable data from the pretraining dataset, leading to better performance with less training data. The associated pretrained models, confidence files, pretraining and finetuning scripts will be made available in the Wespeaker toolkit.
A Study of Modeling Rising Intonation in Cantonese Neural Speech Synthesis
Aug 03, 2022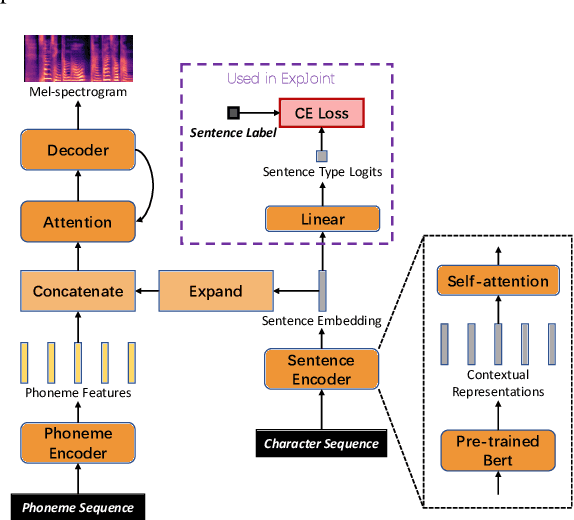
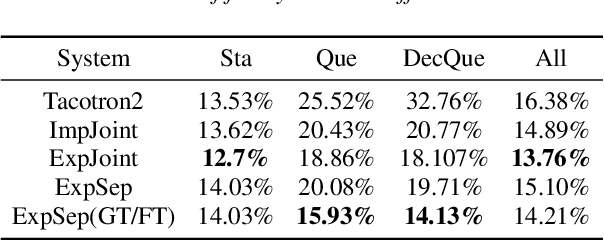
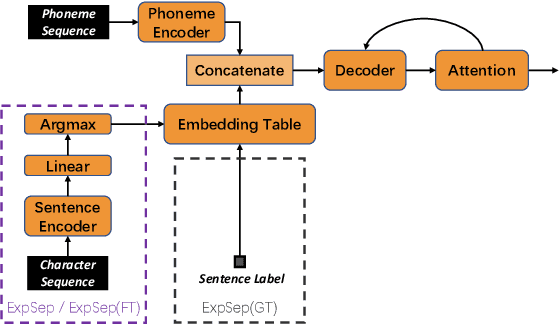

In human speech, the attitude of a speaker cannot be fully expressed only by the textual content. It has to come along with the intonation. Declarative questions are commonly used in daily Cantonese conversations, and they are usually uttered with rising intonation. Vanilla neural text-to-speech (TTS) systems are not capable of synthesizing rising intonation for these sentences due to the loss of semantic information. Though it has become more common to complement the systems with extra language models, their performance in modeling rising intonation is not well studied. In this paper, we propose to complement the Cantonese TTS model with a BERT-based statement/question classifier. We design different training strategies and compare their performance. We conduct our experiments on a Cantonese corpus named CanTTS. Empirical results show that the separate training approach obtains the best generalization performance and feasibility.
Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation
May 18, 2022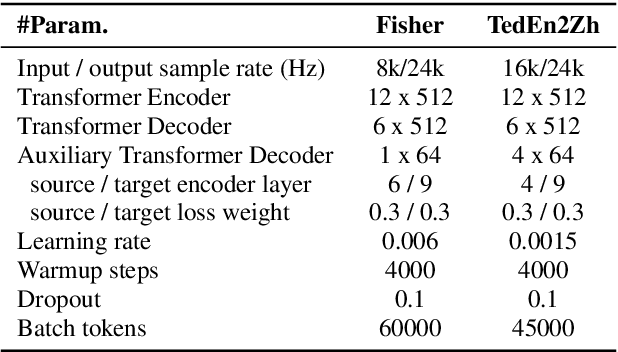
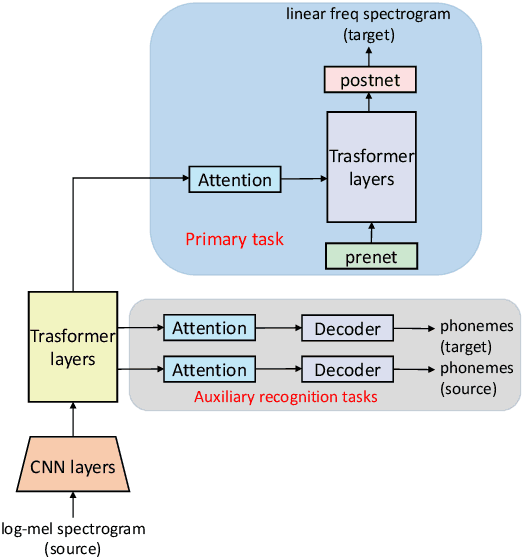
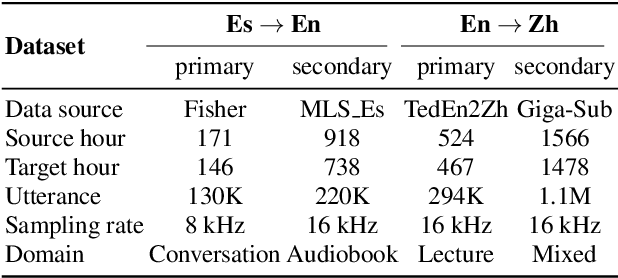
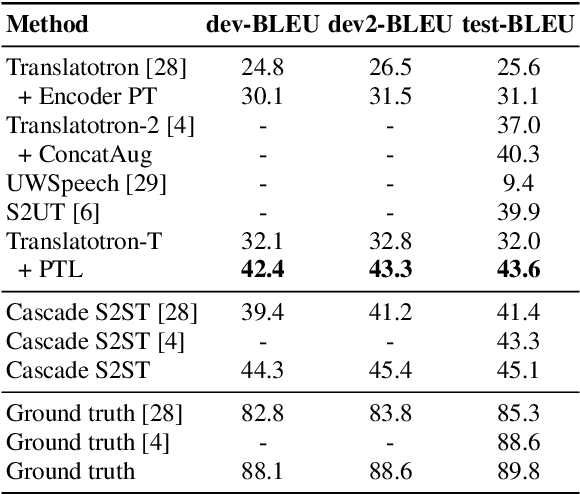
Direct Speech-to-speech translation (S2ST) has drawn more and more attention recently. The task is very challenging due to data scarcity and complex speech-to-speech mapping. In this paper, we report our recent achievements in S2ST. Firstly, we build a S2ST Transformer baseline which outperforms the original Translatotron. Secondly, we utilize the external data by pseudo-labeling and obtain a new state-of-the-art result on the Fisher English-to-Spanish test set. Indeed, we exploit the pseudo data with a combination of popular techniques which are not trivial when applied to S2ST. Moreover, we evaluate our approach on both syntactically similar (Spanish-English) and distant (English-Chinese) language pairs. Our implementation is available at https://github.com/fengpeng-yue/speech-to-speech-translation.
LightHuBERT: Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT
Mar 29, 2022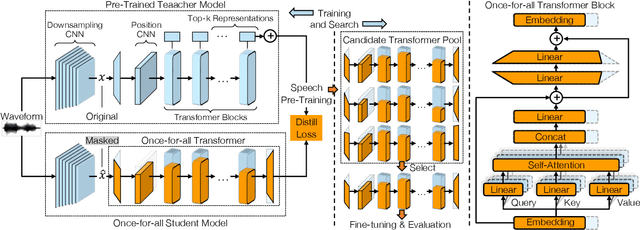
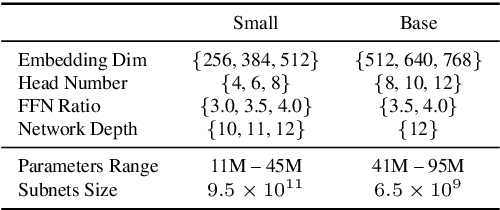

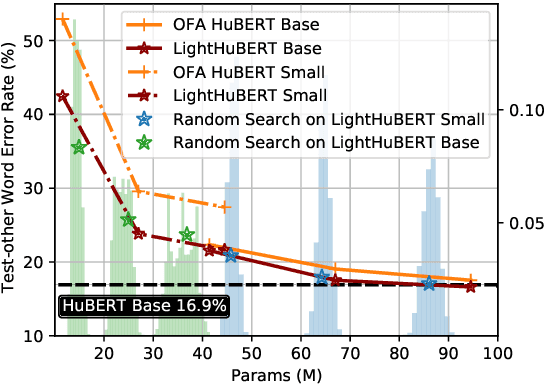
Self-supervised speech representation learning has shown promising results in various speech processing tasks. However, the pre-trained models, e.g., HuBERT, are storage-intensive Transformers, limiting their scope of applications under low-resource settings. To this end, we propose LightHuBERT, a once-for-all Transformer compression framework, to find the desired architectures automatically by pruning structured parameters. More precisely, we create a Transformer-based supernet that is nested with thousands of weight-sharing subnets and design a two-stage distillation strategy to leverage the contextualized latent representations from HuBERT. Experiments on automatic speech recognition (ASR) and the SUPERB benchmark show the proposed LightHuBERT enables over $10^9$ architectures concerning the embedding dimension, attention dimension, head number, feed-forward network ratio, and network depth. LightHuBERT outperforms the original HuBERT on ASR and five SUPERB tasks with the HuBERT size, achieves comparable performance to the teacher model in most tasks with a reduction of 29% parameters, and obtains a $3.5\times$ compression ratio in three SUPERB tasks, e.g., automatic speaker verification, keyword spotting, and intent classification, with a slight accuracy loss. The code and pre-trained models are available at https://github.com/mechanicalsea/lighthubert.