 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoparsing: Diagram Parsing for Plane and Solid Geometry with a Unified Formal Language
Apr 13, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress but continue to struggle with geometric reasoning, primarily due to the perception bottleneck regarding fine-grained visual elements. While formal languages have aided plane geometry understanding, solid geometry which requires spatial understanding remains largely unexplored. In this paper, we address this challenge by designing a unified formal language that integrates plane and solid geometry, comprehensively covering geometric structures and semantic relations. We construct GDP-29K, a large-scale dataset comprising 20k plane and 9k solid geometry samples collected from diverse real-world sources, each paired with its ground-truth formal description. To ensure syntactic correctness and geometric consistency, we propose a training paradigm that combines Supervised Fine-Tuning with Reinforcement Learning via Verifiable Rewards. Experiments show that our approach achieves state-of-the-art parsing performance. Furthermore, we demonstrate that our parsed formal descriptions serve as a critical cognitive scaffold, significantly boosting MLLMs' capabilities for downstream geometry reasoning tasks. Our data and code are available at Geoparsing.
Physics-Aware Heterogeneous GNN Architecture for Real-Time BESS Optimization in Unbalanced Distribution Systems
Dec 10, 2025Battery energy storage systems (BESS) have become increasingly vital in three-phase unbalanced distribution grids for maintaining voltage stability and enabling optimal dispatch. However, existing deep learning approaches often lack explicit three-phase representation, making it difficult to accurately model phase-specific dynamics and enforce operational constraints--leading to infeasible dispatch solutions. This paper demonstrates that by embedding detailed three-phase grid information--including phase voltages, unbalanced loads, and BESS states--into heterogeneous graph nodes, diverse GNN architectures (GCN, GAT, GraphSAGE, GPS) can jointly predict network state variables with high accuracy. Moreover, a physics-informed loss function incorporates critical battery constraints--SoC and C-rate limits--via soft penalties during training. Experimental validation on the CIGRE 18-bus distribution system shows that this embedding-loss approach achieves low prediction errors, with bus voltage MSEs of 6.92e-07 (GCN), 1.21e-06 (GAT), 3.29e-05 (GPS), and 9.04e-07 (SAGE). Importantly, the physics-informed method ensures nearly zero SoC and C-rate constraint violations, confirming its effectiveness for reliable, constraint-compliant dispatch.
Enhanced Multimodal Aspect-Based Sentiment Analysis by LLM-Generated Rationales
May 20, 2025There has been growing interest in Multimodal Aspect-Based Sentiment Analysis (MABSA) in recent years. Existing methods predominantly rely on pre-trained small language models (SLMs) to collect information related to aspects and sentiments from both image and text, with an aim to align these two modalities. However, small SLMs possess limited capacity and knowledge, often resulting in inaccurate identification of meaning, aspects, sentiments, and their interconnections in textual and visual data. On the other hand, Large language models (LLMs) have shown exceptional capabilities in various tasks by effectively exploring fine-grained information in multimodal data. However, some studies indicate that LLMs still fall short compared to fine-tuned small models in the field of ABSA. Based on these findings, we propose a novel framework, termed LRSA, which combines the decision-making capabilities of SLMs with additional information provided by LLMs for MABSA. Specifically, we inject explanations generated by LLMs as rationales into SLMs and employ a dual cross-attention mechanism for enhancing feature interaction and fusion, thereby augmenting the SLMs' ability to identify aspects and sentiments. We evaluated our method using two baseline models, numerous experiments highlight the superiority of our approach on three widely-used benchmarks, indicating its generalizability and applicability to most pre-trained models for MABSA.
SafePowerGraph-LLM: Novel Power Grid Graph Embedding and Optimization with Large Language Models
Jan 13, 2025



Efficiently solving Optimal Power Flow (OPF) problems in power systems is crucial for operational planning and grid management. There is a growing need for scalable algorithms capable of handling the increasing variability, constraints, and uncertainties in modern power networks while providing accurate and fast solutions. To address this, machine learning techniques, particularly Graph Neural Networks (GNNs) have emerged as promising approaches. This letter introduces SafePowerGraph-LLM, the first framework explicitly designed for solving OPF problems using Large Language Models (LLM)s. The proposed approach combines graph and tabular representations of power grids to effectively query LLMs, capturing the complex relationships and constraints in power systems. A new implementation of in-context learning and fine-tuning protocols for LLMs is introduced, tailored specifically for the OPF problem. SafePowerGraph-LLM demonstrates reliable performances using off-the-shelf LLM. Our study reveals the impact of LLM architecture, size, and fine-tuning and demonstrates our framework's ability to handle realistic grid components and constraints.
SafePowerGraph: Safety-aware Evaluation of Graph Neural Networks for Transmission Power Grids
Jul 17, 2024



Power grids are critical infrastructures of paramount importance to modern society and their rapid evolution and interconnections has heightened the complexity of power systems (PS) operations. Traditional methods for grid analysis struggle with the computational demands of large-scale RES and ES integration, prompting the adoption of machine learning (ML) techniques, particularly Graph Neural Networks (GNNs). GNNs have proven effective in solving the alternating current (AC) Power Flow (PF) and Optimal Power Flow (OPF) problems, crucial for operational planning. However, existing benchmarks and datasets completely ignore safety and robustness requirements in their evaluation and never consider realistic safety-critical scenarios that most impact the operations of the power grids. We present SafePowerGraph, the first simulator-agnostic, safety-oriented framework and benchmark for GNNs in PS operations. SafePowerGraph integrates multiple PF and OPF simulators and assesses GNN performance under diverse scenarios, including energy price variations and power line outages. Our extensive experiments underscore the importance of self-supervised learning and graph attention architectures for GNN robustness. We provide at https://github.com/yamizi/SafePowerGraph our open-source repository, a comprehensive leaderboard, a dataset and model zoo and expect our framework to standardize and advance research in the critical field of GNN for power systems.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Xiwu: A Basis Flexible and Learnable LLM for High Energy Physics
Apr 08, 2024Large Language Models (LLMs) are undergoing a period of rapid updates and changes, with state-of-the-art (SOTA) model frequently being replaced. When applying LLMs to a specific scientific field, it's challenging to acquire unique domain knowledge while keeping the model itself advanced. To address this challenge, a sophisticated large language model system named as Xiwu has been developed, allowing you switch between the most advanced foundation models and quickly teach the model domain knowledge. In this work, we will report on the best practices for applying LLMs in the field of high-energy physics (HEP), including: a seed fission technology is proposed and some data collection and cleaning tools are developed to quickly obtain domain AI-Ready dataset; a just-in-time learning system is implemented based on the vector store technology; an on-the-fly fine-tuning system has been developed to facilitate rapid training under a specified foundation model. The results show that Xiwu can smoothly switch between foundation models such as LLaMA, Vicuna, ChatGLM and Grok-1. The trained Xiwu model is significantly outperformed the benchmark model on the HEP knowledge question-and-answering and code generation. This strategy significantly enhances the potential for growth of our model's performance, with the hope of surpassing GPT-4 as it evolves with the development of open-source models. This work provides a customized LLM for the field of HEP, while also offering references for applying LLM to other fields, the corresponding codes are available on Github.
PowerFlowMultiNet: Multigraph Neural Networks for Unbalanced Three-Phase Distribution Systems
Mar 12, 2024



Efficiently solving unbalanced three-phase power flow in distribution grids is pivotal for grid analysis and simulation. There is a pressing need for scalable algorithms capable of handling large-scale unbalanced power grids that can provide accurate and fast solutions. To address this, deep learning techniques, especially Graph Neural Networks (GNNs), have emerged. However, existing literature primarily focuses on balanced networks, leaving a critical gap in supporting unbalanced three-phase power grids. This letter introduces PowerFlowMultiNet, a novel multigraph GNN framework explicitly designed for unbalanced three-phase power grids. The proposed approach models each phase separately in a multigraph representation, effectively capturing the inherent asymmetry in unbalanced grids. A graph embedding mechanism utilizing message passing is introduced to capture spatial dependencies within the power system network. PowerFlowMultiNet outperforms traditional methods and other deep learning approaches in terms of accuracy and computational speed. Rigorous testing reveals significantly lower error rates and a notable hundredfold increase in computational speed for large power networks compared to model-based methods.
Augmentation-Free Graph Contrastive Learning of Invariant-Discriminative Representations
Oct 15, 2022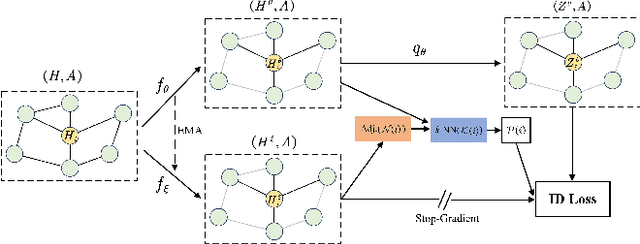
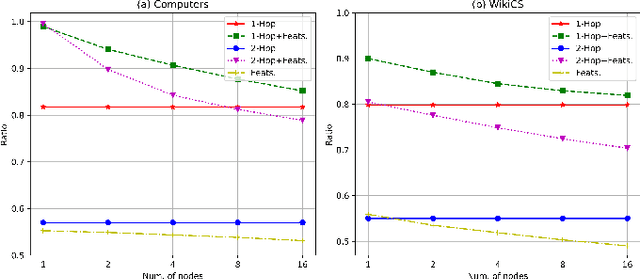
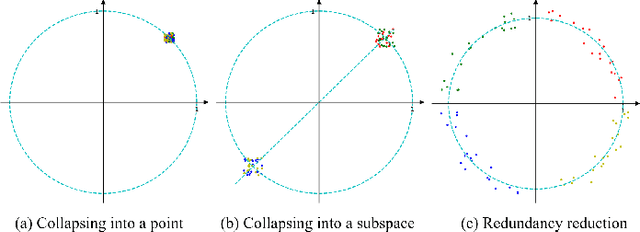

The pretasks are mainly built on mutual information estimation, which requires data augmentation to construct positive samples with similar semantics to learn invariant signals and negative samples with dissimilar semantics in order to empower representation discriminability. However, an appropriate data augmentation configuration depends heavily on lots of empirical trials such as choosing the compositions of data augmentation techniques and the corresponding hyperparameter settings. We propose an augmentation-free graph contrastive learning method, invariant-discriminative graph contrastive learning (iGCL), that does not intrinsically require negative samples. iGCL designs the invariant-discriminative loss (ID loss) to learn invariant and discriminative representations. On the one hand, ID loss learns invariant signals by directly minimizing the mean square error between the target samples and positive samples in the representation space. On the other hand, ID loss ensures that the representations are discriminative by an orthonormal constraint forcing the different dimensions of representations to be independent of each other. This prevents representations from collapsing to a point or subspace. Our theoretical analysis explains the effectiveness of ID loss from the perspectives of the redundancy reduction criterion, canonical correlation analysis, and information bottleneck principle. The experimental results demonstrate that iGCL outperforms all baselines on 5 node classification benchmark datasets. iGCL also shows superior performance for different label ratios and is capable of resisting graph attacks, which indicates that iGCL has excellent generalization and robustness.