 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Diffusion Generation for Geomagnetic Map Interpolation
Jan 31, 2026Geomagnetic map interpolation aims to infer unobserved geomagnetic data at spatial points, yielding critical applications in navigation and resource exploration. However, existing methods for scattered data interpolation are not specifically designed for geomagnetic maps, which inevitably leads to suboptimal performance due to detection noise and the laws of physics. Therefore, we propose a Physics-informed Diffusion Generation framework~(PDG) to interpolate incomplete geomagnetic maps. First, we design a physics-informed mask strategy to guide the diffusion generation process based on a local receptive field, effectively eliminating noise interference. Second, we impose a physics-informed constraint on the diffusion generation results following the kriging principle of geomagnetic maps, ensuring strict adherence to the laws of physics. Extensive experiments and in-depth analyses on four real-world datasets demonstrate the superiority and effectiveness of each component of PDG.
Replay Failures as Successes: Sample-Efficient Reinforcement Learning for Instruction Following
Dec 29, 2025Reinforcement Learning (RL) has shown promise for aligning Large Language Models (LLMs) to follow instructions with various constraints. Despite the encouraging results, RL improvement inevitably relies on sampling successful, high-quality responses; however, the initial model often struggles to generate responses that satisfy all constraints due to its limited capabilities, yielding sparse or indistinguishable rewards that impede learning. In this work, we propose Hindsight instruction Replay (HiR), a novel sample-efficient RL framework for complex instruction following tasks, which employs a select-then-rewrite strategy to replay failed attempts as successes based on the constraints that have been satisfied in hindsight. We perform RL on these replayed samples as well as the original ones, theoretically framing the objective as dual-preference learning at both the instruction- and response-level to enable efficient optimization using only a binary reward signal. Extensive experiments demonstrate that the proposed HiR yields promising results across different instruction following tasks, while requiring less computational budget. Our code and dataset is available at https://github.com/sastpg/HIR.
Learning Multi-Modal Mobility Dynamics for Generalized Next Location Recommendation
Dec 27, 2025The precise prediction of human mobility has produced significant socioeconomic impacts, such as location recommendations and evacuation suggestions. However, existing methods suffer from limited generalization capability: unimodal approaches are constrained by data sparsity and inherent biases, while multi-modal methods struggle to effectively capture mobility dynamics caused by the semantic gap between static multi-modal representation and spatial-temporal dynamics. Therefore, we leverage multi-modal spatial-temporal knowledge to characterize mobility dynamics for the location recommendation task, dubbed as \textbf{M}ulti-\textbf{M}odal \textbf{Mob}ility (\textbf{M}$^3$\textbf{ob}). First, we construct a unified spatial-temporal relational graph (STRG) for multi-modal representation, by leveraging the functional semantics and spatial-temporal knowledge captured by the large language models (LLMs)-enhanced spatial-temporal knowledge graph (STKG). Second, we design a gating mechanism to fuse spatial-temporal graph representations of different modalities, and propose an STKG-guided cross-modal alignment to inject spatial-temporal dynamic knowledge into the static image modality. Extensive experiments on six public datasets show that our proposed method not only achieves consistent improvements in normal scenarios but also exhibits significant generalization ability in abnormal scenarios.
Tree of Preferences for Diversified Recommendation
Dec 24, 2025Diversified recommendation has attracted increasing attention from both researchers and practitioners, which can effectively address the homogeneity of recommended items. Existing approaches predominantly aim to infer the diversity of user preferences from observed user feedback. Nonetheless, due to inherent data biases, the observed data may not fully reflect user interests, where underexplored preferences can be overwhelmed or remain unmanifested. Failing to capture these preferences can lead to suboptimal diversity in recommendations. To fill this gap, this work aims to study diversified recommendation from a data-bias perspective. Inspired by the outstanding performance of large language models (LLMs) in zero-shot inference leveraging world knowledge, we propose a novel approach that utilizes LLMs' expertise to uncover underexplored user preferences from observed behavior, ultimately providing diverse and relevant recommendations. To achieve this, we first introduce Tree of Preferences (ToP), an innovative structure constructed to model user preferences from coarse to fine. ToP enables LLMs to systematically reason over the user's rationale behind their behavior, thereby uncovering their underexplored preferences. To guide diversified recommendations using uncovered preferences, we adopt a data-centric approach, identifying candidate items that match user preferences and generating synthetic interactions that reflect underexplored preferences. These interactions are integrated to train a general recommender for diversification. Moreover, we scale up overall efficiency by dynamically selecting influential users during optimization. Extensive evaluations of both diversity and relevance show that our approach outperforms existing methods in most cases and achieves near-optimal performance in others, with reasonable inference latency.
Mixture-of-Schedulers: An Adaptive Scheduling Agent as a Learned Router for Expert Policies
Nov 07, 2025Modern operating system schedulers employ a single, static policy, which struggles to deliver optimal performance across the diverse and dynamic workloads of contemporary systems. This "one-policy-fits-all" approach leads to significant compromises in fairness, throughput, and latency, particularly with the rise of heterogeneous hardware and varied application architectures. This paper proposes a new paradigm: dynamically selecting the optimal policy from a portfolio of specialized schedulers rather than designing a single, monolithic one. We present the Adaptive Scheduling Agent (ASA), a lightweight framework that intelligently matches workloads to the most suitable "expert" scheduling policy at runtime. ASA's core is a novel, low-overhead offline/online approach. First, an offline process trains a universal, hardware-agnostic machine learning model to recognize abstract workload patterns from system behaviors. Second, at runtime, ASA continually processes the model's predictions using a time-weighted probability voting algorithm to identify the workload, then makes a scheduling decision by consulting a pre-configured, machine-specific mapping table to switch to the optimal scheduler via Linux's sched_ext framework. This decoupled architecture allows ASA to adapt to new hardware platforms rapidly without expensive retraining of the core recognition model. Our evaluation, based on a novel benchmark focused on user-experience metrics, demonstrates that ASA consistently outperforms the default Linux scheduler (EEVDF), achieving superior results in 86.4% of test scenarios. Furthermore, ASA's selections are near-optimal, ranking among the top three schedulers in 78.6% of all scenarios. This validates our approach as a practical path toward more intelligent, adaptive, and responsive operating system schedulers.
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
Aug 23, 2025Recent advances in Large Language Models (LLMs) have underscored the potential of Reinforcement Learning (RL) to facilitate the emergence of reasoning capabilities. Despite the encouraging results, a fundamental dilemma persists as RL improvement relies on learning from high-quality samples, yet the exploration for such samples remains bounded by the inherent limitations of LLMs. This, in effect, creates an undesirable cycle in which what cannot be explored cannot be learned. In this work, we propose Rubric-Scaffolded Reinforcement Learning (RuscaRL), a novel instructional scaffolding framework designed to break the exploration bottleneck for general LLM reasoning. Specifically, RuscaRL introduces checklist-style rubrics as (1) explicit scaffolding for exploration during rollout generation, where different rubrics are provided as external guidance within task instructions to steer diverse high-quality responses. This guidance is gradually decayed over time, encouraging the model to internalize the underlying reasoning patterns; (2) verifiable rewards for exploitation during model training, where we can obtain robust LLM-as-a-Judge scores using rubrics as references, enabling effective RL on general reasoning tasks. Extensive experiments demonstrate the superiority of the proposed RuscaRL across various benchmarks, effectively expanding reasoning boundaries under the best-of-N evaluation. Notably, RuscaRL significantly boosts Qwen-2.5-7B-Instruct from 23.6 to 50.3 on HealthBench-500, surpassing GPT-4.1. Furthermore, our fine-tuned variant on Qwen3-30B-A3B-Instruct achieves 61.1 on HealthBench-500, outperforming leading LLMs including OpenAI-o3.
Dataset Ownership Verification for Pre-trained Masked Models
Jul 16, 2025High-quality open-source datasets have emerged as a pivotal catalyst driving the swift advancement of deep learning, while facing the looming threat of potential exploitation. Protecting these datasets is of paramount importance for the interests of their owners. The verification of dataset ownership has evolved into a crucial approach in this domain; however, existing verification techniques are predominantly tailored to supervised models and contrastive pre-trained models, rendering them ill-suited for direct application to the increasingly prevalent masked models. In this work, we introduce the inaugural methodology addressing this critical, yet unresolved challenge, termed Dataset Ownership Verification for Masked Modeling (DOV4MM). The central objective is to ascertain whether a suspicious black-box model has been pre-trained on a particular unlabeled dataset, thereby assisting dataset owners in safeguarding their rights. DOV4MM is grounded in our empirical observation that when a model is pre-trained on the target dataset, the difficulty of reconstructing masked information within the embedding space exhibits a marked contrast to models not pre-trained on that dataset. We validated the efficacy of DOV4MM through ten masked image models on ImageNet-1K and four masked language models on WikiText-103. The results demonstrate that DOV4MM rejects the null hypothesis, with a $p$-value considerably below 0.05, surpassing all prior approaches. Code is available at https://github.com/xieyc99/DOV4MM.
GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies
Jun 17, 2025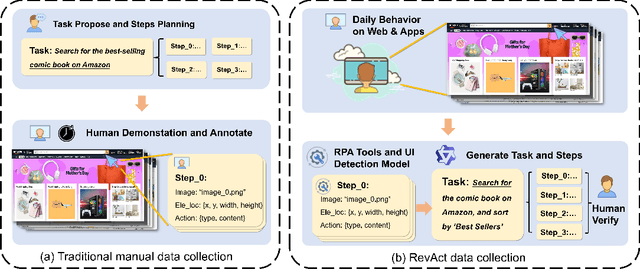
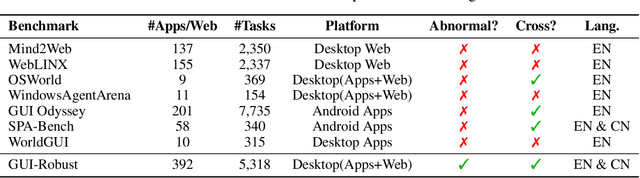

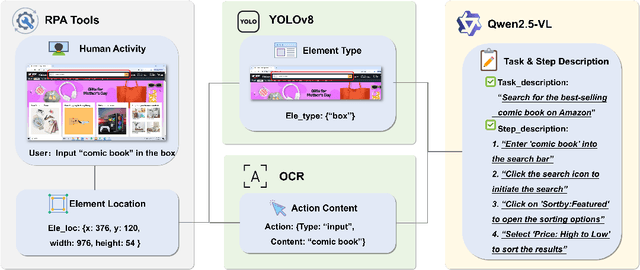
The development of high-quality datasets is crucial for benchmarking and advancing research in Graphical User Interface (GUI) agents. Despite their importance, existing datasets are often constructed under idealized conditions, overlooking the diverse anomalies frequently encountered in real-world deployments. To address this limitation, we introduce GUI-Robust, a novel dataset designed for comprehensive GUI agent evaluation, explicitly incorporating seven common types of anomalies observed in everyday GUI interactions. Furthermore, we propose a semi-automated dataset construction paradigm that collects user action sequences from natural interactions via RPA tools and then generate corresponding step and task descriptions for these actions with the assistance of MLLMs. This paradigm significantly reduces annotation time cost by a factor of over 19 times. Finally, we assess state-of-the-art GUI agents using the GUI-Robust dataset, revealing their substantial performance degradation in abnormal scenarios. We anticipate that our work will highlight the importance of robustness in GUI agents and inspires more future research in this direction. The dataset and code are available at https://github.com/chessbean1/GUI-Robust..
Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning
Jun 10, 2025Recent advances of Reinforcement Learning (RL) have highlighted its potential in complex reasoning tasks, yet effective training often relies on external supervision, which limits the broader applicability. In this work, we propose a novel self-rewarding reinforcement learning framework to enhance Large Language Model (LLM) reasoning by leveraging the consistency of intermediate reasoning states across different reasoning trajectories. Our key insight is that correct responses often exhibit consistent trajectory patterns in terms of model likelihood: their intermediate reasoning states tend to converge toward their own final answers (high consistency) with minimal deviation toward other candidates (low volatility). Inspired by this observation, we introduce CoVo, an intrinsic reward mechanism that integrates Consistency and Volatility via a robust vector-space aggregation strategy, complemented by a curiosity bonus to promote diverse exploration. CoVo enables LLMs to perform RL in a self-rewarding manner, offering a scalable pathway for learning to reason without external supervision. Extensive experiments on diverse reasoning benchmarks show that CoVo achieves performance comparable to or even surpassing supervised RL. Our code is available at https://github.com/sastpg/CoVo.
Adaptive Location Hierarchy Learning for Long-Tailed Mobility Prediction
May 26, 2025Human mobility prediction is crucial for applications ranging from location-based recommendations to urban planning, which aims to forecast users' next location visits based on historical trajectories. Despite the severe long-tailed distribution of locations, the problem of long-tailed mobility prediction remains largely underexplored. Existing long-tailed learning methods primarily focus on rebalancing the skewed distribution at the data, model, or class level, neglecting to exploit the spatiotemporal semantics of locations. To address this gap, we propose the first plug-and-play framework for long-tailed mobility prediction in an exploitation and exploration manner, named \textbf{A}daptive \textbf{LO}cation \textbf{H}ier\textbf{A}rchy learning (ALOHA). First, we construct city-tailored location hierarchy based on Large Language Models (LLMs) by exploiting Maslow's theory of human motivation to design Chain-of-Thought (CoT) prompts that captures spatiotemporal semantics. Second, we optimize the location hierarchy predictions by Gumbel disturbance and node-wise adaptive weights within the hierarchical tree structure. Experiments on state-of-the-art models across six datasets demonstrate the framework's consistent effectiveness and generalizability, which strikes a well balance between head and tail locations. Weight analysis and ablation studies reveal the optimization differences of each component for head and tail locations. Furthermore, in-depth analyses of hierarchical distance and case study demonstrate the effective semantic guidance from the location hierarchy. Our code will be made publicly available.