 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Decentralized Online Convex Optimization with Compressed Communication
Jul 02, 2026Decentralized online convex optimization (D-OCO) is a popular framework for distributed applications with streaming data. To tackle the communication bottleneck, previous studies have investigated D-OCO with compressed communication and proposed several algorithms that are variants of online gradient descent (OGD). However, for D-OCO with exact communication, the best existing algorithms are variants of follow-the-regularized-leader (FTRL). In this paper, for the first time, we propose two FTRL-type algorithms for D-OCO with compressed communication. Compared with OGD-type algorithms, our algorithms are more elegant in both algorithmic design and theoretical analysis. The key insight is that the dual update mechanism of FTRL allows us to make a simple application of the technique for average consensus with communication compression. More specifically, our first algorithm considers the full-information setting, and can match the existing regret bounds. Our second algorithm is designed for the bandit setting, and can significantly improve both the regret bounds and communication costs of existing algorithms.
Open Problem: Is AdamW Effective Under Heavy-Tailed Noise?
Jun 22, 2026AdamW is the de facto optimizer for training large language models (LLMs), yet the theory behind it still lives mostly in finite-variance regimes. This is increasingly unsatisfying, as empirical evidence indicates that stochastic gradient noise in LLM pretraining is typically heavy-tailed. Recent work shows that sign-based optimizers such as Lion and Muon achieve sharp heavy-tailed rates, and that AdaGrad can also converge under heavy-tailed noise. However, no rigorous convergence theory for AdamW has yet been established in this regime. Can AdamW converge under the same heavy-tailed assumptions, or does its second-moment accumulator create a genuine obstruction? We formulate this as an open problem, prove a positive weighted-metric benchmark, and give a corridor lower-bound mechanism showing how denominator memory can hide large gradients.
Temporal Motif-aware Graph Test-time Adaptation for OOD Blockchain Anomaly Detection
May 28, 2026Ever-evolving transaction patterns have significantly hindered anomaly detection on emerging cryptocurrency blockchains due to the vast number of addresses and diverse anomalous behaviors. Recently, advanced Graph Anomaly Detection (GAD) approaches applied to blockchains have faced two critical challenges: \textit{adversarial pattern evolution by malicious actors} and \textit{the out-of-distribution (OOD) problem caused by varied transaction semantics on blockchains}. To address these challenges, we propose a novel framework termed \textbf{TE}mporal \textbf{M}otif-aware \textbf{G}raph \textbf{T}est-\textbf{T}ime \textbf{A}daptation (\textbf{TEMG-TTA}). First, we comprehensively capture the 3-node temporal motif distribution of each active address using an efficient computational mechanism, enabling downstream temporal motif-aware graph learning. Second, we design a simple yet effective test-time adaptation strategy to facilitate the sharing of common patterns between training and testing graphs. Extensive experiments on 5 real-world datasets demonstrate that our proposed \textbf{TEMG-TTA} outperforms \textit{state-of-the-art} GAD approaches by an average of 54.88\%. A further case study on interpretable motif patterns reveals that \textbf{TEMG-TTA} explicitly characterizes the complex transaction patterns of anomalous addresses, thereby verifying the effectiveness of our technical designs. Our code will be made publicly available https://github.com/LuoXishuang0712/TEMG-TTA/.
Walk the Talk: Bridging the Reasoning-Action Gap for Thinking with Images via Multimodal Agentic Policy Optimization
Apr 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have incentivized models to ``think with images'' by actively invoking visual tools during multi-turn reasoning. The common Reinforcement Learning (RL) practice of relying on outcome-based rewards ignores the fact that textual plausibility often masks executive failure, meaning that models may exhibit intuitive textual reasoning while executing imprecise or irrelevant visual actions within their agentic reasoning trajectories. This reasoning-action discrepancy introduces noise that accumulates throughout the multi-turn reasoning process, severely degrading the model's multimodal reasoning capabilities and potentially leading to training collapse. In this paper, we introduce Multimodal Agentic Policy Optimization (MAPO), bridging the gap between textual reasoning and visual actions generated by models within their Multimodal Chain-of-Thought (MCoT). Specifically, MAPO mandates the model to generate explicit textual descriptions for the visual content obtained via tool usage. We then employ a novel advantage estimation that couples the semantic alignment between these descriptions and the actual observations with the task reward. Theoretical findings are provided to justify the rationale behind MAPO, which inherently reduces the variance of gradients, and extensive experiments demonstrate that our method achieves superior performance across multiple visual reasoning benchmarks.
SpatiaLQA: A Benchmark for Evaluating Spatial Logical Reasoning in Vision-Language Models
Feb 24, 2026Vision-Language Models (VLMs) have been increasingly applied in real-world scenarios due to their outstanding understanding and reasoning capabilities. Although VLMs have already demonstrated impressive capabilities in common visual question answering and logical reasoning, they still lack the ability to make reasonable decisions in complex real-world environments. We define this ability as spatial logical reasoning, which not only requires understanding the spatial relationships among objects in complex scenes, but also the logical dependencies between steps in multi-step tasks. To bridge this gap, we introduce Spatial Logical Question Answering (SpatiaLQA), a benchmark designed to evaluate the spatial logical reasoning capabilities of VLMs. SpatiaLQA consists of 9,605 question answer pairs derived from 241 real-world indoor scenes. We conduct extensive experiments on 41 mainstream VLMs, and the results show that even the most advanced models still struggle with spatial logical reasoning. To address this issue, we propose a method called recursive scene graph assisted reasoning, which leverages visual foundation models to progressively decompose complex scenes into task-relevant scene graphs, thereby enhancing the spatial logical reasoning ability of VLMs, outperforming all previous methods. Code and dataset are available at https://github.com/xieyc99/SpatiaLQA.
Improved Approximate Regret for Decentralized Online Continuous Submodular Maximization via Reductions
Feb 10, 2026To expand the applicability of decentralized online learning, previous studies have proposed several algorithms for decentralized online continuous submodular maximization (D-OCSM) -- a non-convex/non-concave setting with continuous DR-submodular reward functions. However, there exist large gaps between their approximate regret bounds and the regret bounds achieved in the convex setting. Moreover, if focusing on projection-free algorithms, which can efficiently handle complex decision sets, they cannot even recover the approximate regret bounds achieved in the centralized setting. In this paper, we first demonstrate that for D-OCSM over general convex decision sets, these two issues can be addressed simultaneously. Furthermore, for D-OCSM over downward-closed decision sets, we show that the second issue can be addressed while significantly alleviating the first issue. Our key techniques are two reductions from D-OCSM to decentralized online convex optimization (D-OCO), which can exploit D-OCO algorithms to improve the approximate regret of D-OCSM in these two cases, respectively.
Sign-Based Optimizers Are Effective Under Heavy-Tailed Noise
Feb 07, 2026While adaptive gradient methods are the workhorse of modern machine learning, sign-based optimization algorithms such as Lion and Muon have recently demonstrated superior empirical performance over AdamW in training large language models (LLM). However, a theoretical understanding of why sign-based updates outperform variance-adapted methods remains elusive. In this paper, we aim to bridge the gap between theory and practice through the lens of heavy-tailed gradient noise, a phenomenon frequently observed in language modeling tasks. Theoretically, we introduce a novel generalized heavy-tailed noise condition that captures the behavior of LLMs more accurately than standard finite variance assumptions. Under this noise model, we establish sharp convergence rates of SignSGD and Lion for generalized smooth function classes, matching or surpassing previous best-known bounds. Furthermore, we extend our analysis to Muon and Muonlight, providing what is, to our knowledge, the first rigorous analysis of matrix optimization under heavy-tailed stochasticity. These results offer a strong theoretical justification for the empirical superiority of sign-based optimizers, showcasing that they are naturally suited to handle the noisy gradients associated with heavy tails. Empirically, LLM pretraining experiments validate our theoretical insights and confirm that our proposed noise models are well-aligned with practice.
KeepLoRA: Continual Learning with Residual Gradient Adaptation
Jan 27, 2026Continual learning for pre-trained vision-language models requires balancing three competing objectives: retaining pre-trained knowledge, preserving knowledge from a sequence of learned tasks, and maintaining the plasticity to acquire new knowledge. This paper presents a simple but effective approach called KeepLoRA to effectively balance these objectives. We first analyze the knowledge retention mechanism within the model parameter space and find that general knowledge is mainly encoded in the principal subspace, while task-specific knowledge is encoded in the residual subspace. Motivated by this finding, KeepLoRA learns new tasks by restricting LoRA parameter updates in the residual subspace to prevent interfering with previously learned capabilities. Specifically, we infuse knowledge for a new task by projecting its gradient onto a subspace orthogonal to both the principal subspace of pre-trained model and the dominant directions of previous task features. Our theoretical and empirical analyses confirm that KeepLoRA balances the three objectives and achieves state-of-the-art performance. The implementation code is available at https://github.com/MaolinLuo/KeepLoRA.
Deep But Reliable: Advancing Multi-turn Reasoning for Thinking with Images
Dec 19, 2025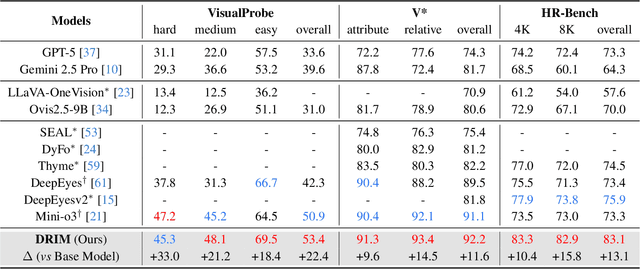
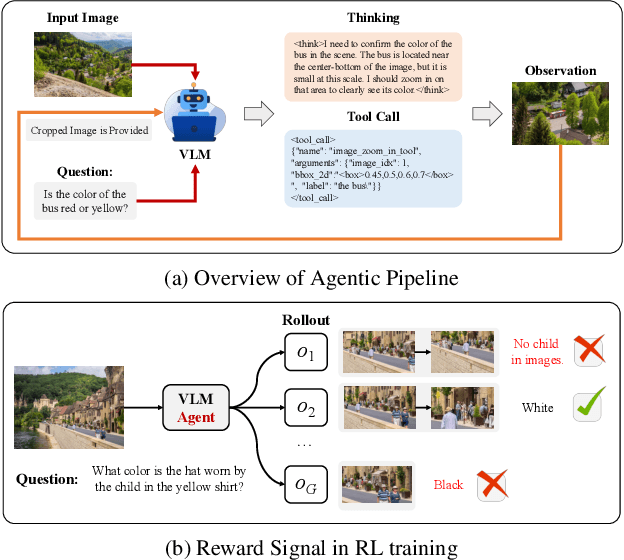
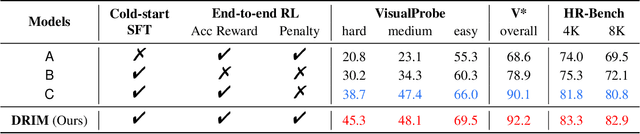
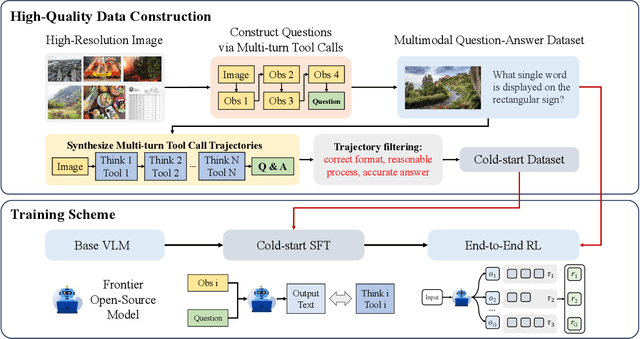
Recent advances in large Vision-Language Models (VLMs) have exhibited strong reasoning capabilities on complex visual tasks by thinking with images in their Chain-of-Thought (CoT), which is achieved by actively invoking tools to analyze visual inputs rather than merely perceiving them. However, existing models often struggle to reflect on and correct themselves when attempting incorrect reasoning trajectories. To address this limitation, we propose DRIM, a model that enables deep but reliable multi-turn reasoning when thinking with images in its multimodal CoT. Our pipeline comprises three stages: data construction, cold-start SFT and RL. Based on a high-resolution image dataset, we construct high-difficulty and verifiable visual question-answer pairs, where solving each task requires multi-turn tool calls to reach the correct answer. In the SFT stage, we collect tool trajectories as cold-start data, guiding a multi-turn reasoning pattern. In the RL stage, we introduce redundancy-penalized policy optimization, which incentivizes the model to develop a self-reflective reasoning pattern. The basic idea is to impose judgment on reasoning trajectories and penalize those that produce incorrect answers without sufficient multi-scale exploration. Extensive experiments demonstrate that DRIM achieves superior performance on visual understanding benchmarks.
Beyond the Lower Bound: Bridging Regret Minimization and Best Arm Identification in Lexicographic Bandits
Nov 08, 2025In multi-objective decision-making with hierarchical preferences, lexicographic bandits provide a natural framework for optimizing multiple objectives in a prioritized order. In this setting, a learner repeatedly selects arms and observes reward vectors, aiming to maximize the reward for the highest-priority objective, then the next, and so on. While previous studies have primarily focused on regret minimization, this work bridges the gap between \textit{regret minimization} and \textit{best arm identification} under lexicographic preferences. We propose two elimination-based algorithms to address this joint objective. The first algorithm eliminates suboptimal arms sequentially, layer by layer, in accordance with the objective priorities, and achieves sample complexity and regret bounds comparable to those of the best single-objective algorithms. The second algorithm simultaneously leverages reward information from all objectives in each round, effectively exploiting cross-objective dependencies. Remarkably, it outperforms the known lower bound for the single-objective bandit problem, highlighting the benefit of cross-objective information sharing in the multi-objective setting. Empirical results further validate their superior performance over baselines.