 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience is the Best Teacher: Motivating Effective Exploration in Reinforcement Learning for LLMs
Mar 20, 2026Reinforcement Learning (RL) with rubric-based rewards has recently shown remarkable progress in enhancing general reasoning capabilities of Large Language Models (LLMs), yet still suffers from ineffective exploration confined to curent policy distribution. In fact, RL optimization can be viewed as steering the policy toward an ideal distribution that maximizes the rewards, while effective exploration should align efforts with desired target. Leveraging this insight, we propose HeRL, a Hindsight experience guided Reinforcement Learning framework to bootstrap effective exploration by explicitly telling LLMs the desired behaviors specified in rewards. Concretely, HeRL treats failed trajectories along with their unmet rubrics as hindsight experience, which serves as in-context guidance for the policy to explore desired responses beyond its current distribution. Additionally, we introduce a bonus reward to incentivize responses with greater potential for improvement under such guidance. HeRL facilitates effective learning from desired high quality samples without repeated trial-and-error from scratch, yielding a more accurate estimation of the expected gradient theoretically. Extensive experiments across various benchmarks demonstrate that HeRL achieves superior performance gains over baselines, and can further benefit from experience guided self-improvement at test time. Our code is available at https://github.com/sikelifei/HeRL.
Replay Failures as Successes: Sample-Efficient Reinforcement Learning for Instruction Following
Dec 29, 2025Reinforcement Learning (RL) has shown promise for aligning Large Language Models (LLMs) to follow instructions with various constraints. Despite the encouraging results, RL improvement inevitably relies on sampling successful, high-quality responses; however, the initial model often struggles to generate responses that satisfy all constraints due to its limited capabilities, yielding sparse or indistinguishable rewards that impede learning. In this work, we propose Hindsight instruction Replay (HiR), a novel sample-efficient RL framework for complex instruction following tasks, which employs a select-then-rewrite strategy to replay failed attempts as successes based on the constraints that have been satisfied in hindsight. We perform RL on these replayed samples as well as the original ones, theoretically framing the objective as dual-preference learning at both the instruction- and response-level to enable efficient optimization using only a binary reward signal. Extensive experiments demonstrate that the proposed HiR yields promising results across different instruction following tasks, while requiring less computational budget. Our code and dataset is available at https://github.com/sastpg/HIR.
Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning
Jun 10, 2025Recent advances of Reinforcement Learning (RL) have highlighted its potential in complex reasoning tasks, yet effective training often relies on external supervision, which limits the broader applicability. In this work, we propose a novel self-rewarding reinforcement learning framework to enhance Large Language Model (LLM) reasoning by leveraging the consistency of intermediate reasoning states across different reasoning trajectories. Our key insight is that correct responses often exhibit consistent trajectory patterns in terms of model likelihood: their intermediate reasoning states tend to converge toward their own final answers (high consistency) with minimal deviation toward other candidates (low volatility). Inspired by this observation, we introduce CoVo, an intrinsic reward mechanism that integrates Consistency and Volatility via a robust vector-space aggregation strategy, complemented by a curiosity bonus to promote diverse exploration. CoVo enables LLMs to perform RL in a self-rewarding manner, offering a scalable pathway for learning to reason without external supervision. Extensive experiments on diverse reasoning benchmarks show that CoVo achieves performance comparable to or even surpassing supervised RL. Our code is available at https://github.com/sastpg/CoVo.
Reasoning with Reinforced Functional Token Tuning
Feb 19, 2025



In this work, we propose Reinforced Functional Token Tuning (RFTT), a novel reinforced fine-tuning framework that empowers Large Language Models (LLMs) with self-play learn-to-reason capabilities. Unlike prior prompt-driven reasoning efforts, RFTT embeds a rich set of learnable functional tokens (e.g., <analyze>, <verify>, <refine>) directly into the model vocabulary, enabling chain-of-thought construction with diverse human-like reasoning behaviors. Specifically, RFTT comprises two phases: (1) supervised fine-tuning performs prompt-driven tree search to obtain self-generated training data annotated with functional tokens, which warms up the model to learn these tokens for reasoning; and (2) online reinforcement learning further allows the model to explore different reasoning pathways through functional token sampling without relying on prompts, thereby facilitating effective self-improvement for functional reasoning. Extensive experiments demonstrate the superiority of the proposed RFTT on mathematical benchmarks, significantly boosting Qwen-2.5-7B-Instruct (70.6% to 79.8%) and LLaMA-3.1-8B-Instruct (32.2% to 60.2%) on the MATH dataset. Moreover, the performance of RFTT consistently improves with more search rollouts at inference time. Our code is available at https://github.com/sastpg/RFTT.
Online Convolutional Re-parameterization
Apr 02, 2022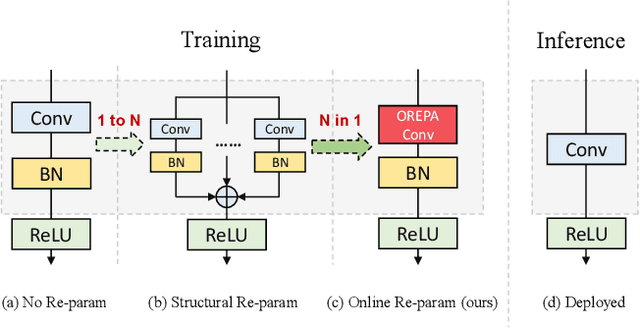
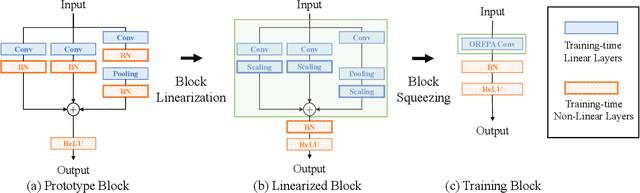
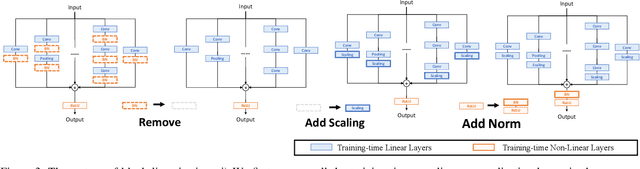
Structural re-parameterization has drawn increasing attention in various computer vision tasks. It aims at improving the performance of deep models without introducing any inference-time cost. Though efficient during inference, such models rely heavily on the complicated training-time blocks to achieve high accuracy, leading to large extra training cost. In this paper, we present online convolutional re-parameterization (OREPA), a two-stage pipeline, aiming to reduce the huge training overhead by squeezing the complex training-time block into a single convolution. To achieve this goal, we introduce a linear scaling layer for better optimizing the online blocks. Assisted with the reduced training cost, we also explore some more effective re-param components. Compared with the state-of-the-art re-param models, OREPA is able to save the training-time memory cost by about 70% and accelerate the training speed by around 2x. Meanwhile, equipped with OREPA, the models outperform previous methods on ImageNet by up to +0.6%.We also conduct experiments on object detection and semantic segmentation and show consistent improvements on the downstream tasks. Codes are available at https://github.com/JUGGHM/OREPA_CVPR2022 .
Offline-Online Associated Camera-Aware Proxies for Unsupervised Person Re-identification
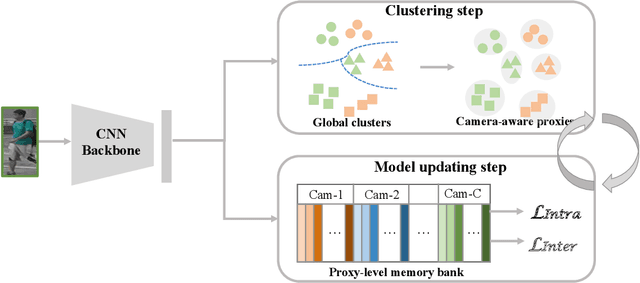
Jan 15, 2022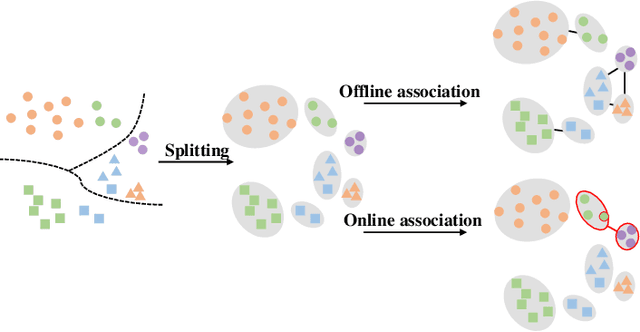


Recently, unsupervised person re-identification (Re-ID) has received increasing research attention due to its potential for label-free applications. A promising way to address unsupervised Re-ID is clustering-based, which generates pseudo labels by clustering and uses the pseudo labels to train a Re-ID model iteratively. However, most clustering-based methods take each cluster as a pseudo identity class, neglecting the intra-cluster variance mainly caused by the change of cameras. To address this issue, we propose to split each single cluster into multiple proxies according to camera views. The camera-aware proxies explicitly capture local structures within clusters, by which the intra-ID variance and inter-ID similarity can be better tackled. Assisted with the camera-aware proxies, we design two proxy-level contrastive learning losses that are, respectively, based on offline and online association results. The offline association directly associates proxies according to the clustering and splitting results, while the online strategy dynamically associates proxies in terms of up-to-date features to reduce the noise caused by the delayed update of pseudo labels. The combination of two losses enable us to train a desirable Re-ID model. Extensive experiments on three person Re-ID datasets and one vehicle Re-ID dataset show that our proposed approach demonstrates competitive performance with state-of-the-art methods. Code will be available at: https://github.com/Terminator8758/O2CAP.
Camera-aware Proxies for Unsupervised Person Re-Identification
Dec 19, 2020


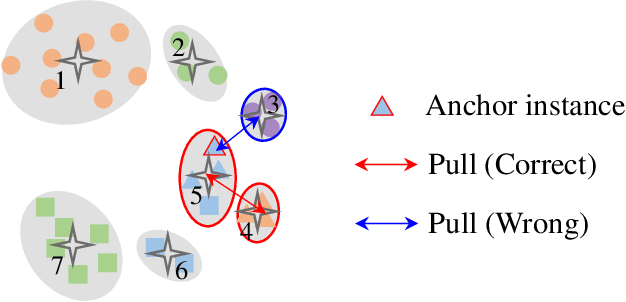
This paper tackles the purely unsupervised person re-identification (Re-ID) problem that requires no annotations. Some previous methods adopt clustering techniques to generate pseudo labels and use the produced labels to train Re-ID models progressively. These methods are relatively simple but effective. However, most clustering-based methods take each cluster as a pseudo identity class, neglecting the large intra-ID variance caused mainly by the change of camera views. To address this issue, we propose to split each single cluster into multiple proxies and each proxy represents the instances coming from the same camera. These camera-aware proxies enable us to deal with large intra-ID variance and generate more reliable pseudo labels for learning. Based on the camera-aware proxies, we design both intra- and inter-camera contrastive learning components for our Re-ID model to effectively learn the ID discrimination ability within and across cameras. Meanwhile, a proxy-balanced sampling strategy is also designed, which facilitates our learning further. Extensive experiments on three large-scale Re-ID datasets show that our proposed approach outperforms most unsupervised methods by a significant margin. Especially, on the challenging MSMT17 dataset, we gain $14.3\%$ Rank-1 and $10.2\%$ mAP improvements when compared to the second place.
Learning to Generate Content-Aware Dynamic Detectors
Dec 08, 2020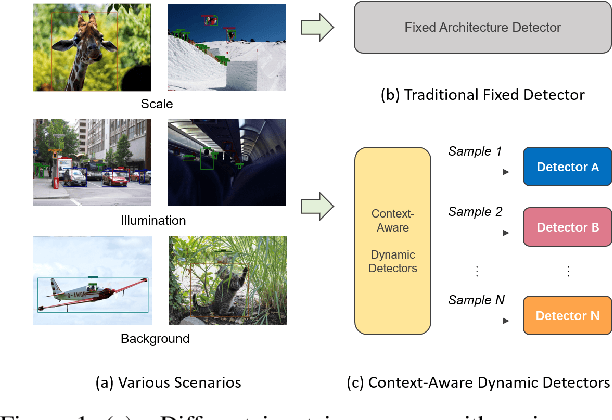
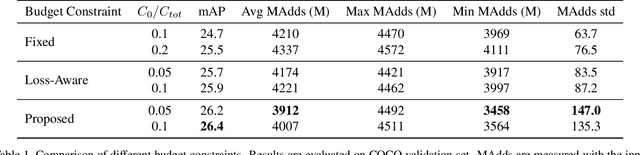
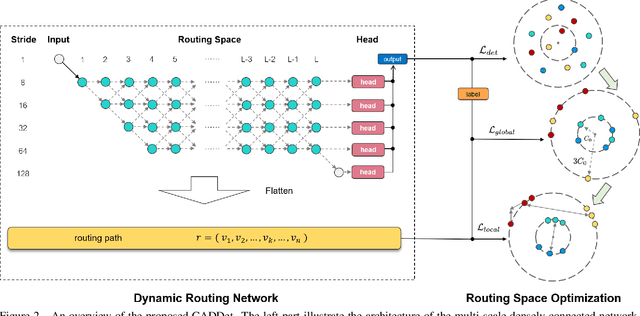
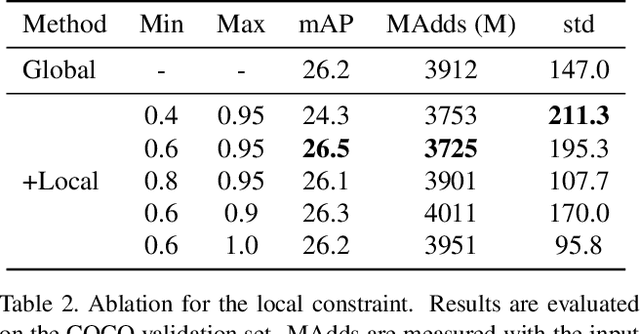
Model efficiency is crucial for object detection. Mostprevious works rely on either hand-crafted design or auto-search methods to obtain a static architecture, regardless ofthe difference of inputs. In this paper, we introduce a newperspective of designing efficient detectors, which is automatically generating sample-adaptive model architectureon the fly. The proposed method is named content-aware dynamic detectors (CADDet). It first applies a multi-scale densely connected network with dynamic routing as the supernet. Furthermore, we introduce a course-to-fine strat-egy tailored for object detection to guide the learning of dynamic routing, which contains two metrics: 1) dynamic global budget constraint assigns data-dependent expectedbudgets for individual samples; 2) local path similarity regularization aims to generate more diverse routing paths. With these, our method achieves higher computational efficiency while maintaining good performance. To the best of our knowledge, our CADDet is the first work to introduce dynamic routing mechanism in object detection. Experiments on MS-COCO dataset demonstrate that CADDet achieves 1.8 higher mAP with 10% fewer FLOPs compared with vanilla routing strategy. Compared with the models based upon similar building blocks, CADDet achieves a 42% FLOPs reduction with a competitive mAP.
Towards Precise Intra-camera Supervised Person Re-identification
Feb 12, 2020

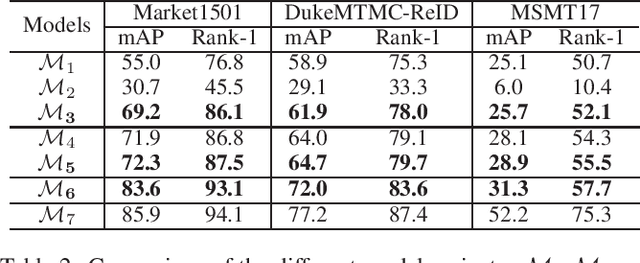
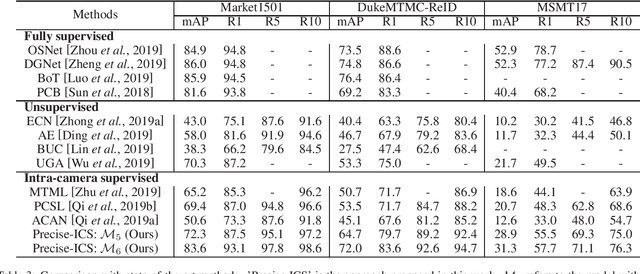
Intra-camera supervision (ICS) for person re-identification (Re-ID) assumes that identity labels are independently annotated within each camera view and no inter-camera identity association is labeled. It is a new setting proposed recently to reduce the burden of annotation while expect to maintain desirable Re-ID performance. However, the lack of inter-camera labels makes the ICS Re-ID problem much more challenging than the fully supervised counterpart. By investigating the characteristics of ICS, this paper proposes camera-specific non-parametric classifiers, together with a hybrid mining quintuplet loss, to perform intra-camera learning. Then, an inter-camera learning module consisting of a graph-based ID association step and a Re-ID model updating step is conducted. Extensive experiments on three large-scale Re-ID datasets show that our approach outperforms all existing ICS works by a great margin. Our approach performs even comparable to state-of-the-art fully supervised methods in two of the datasets.
Deep Active Learning for Video-based Person Re-identification
Dec 14, 2018
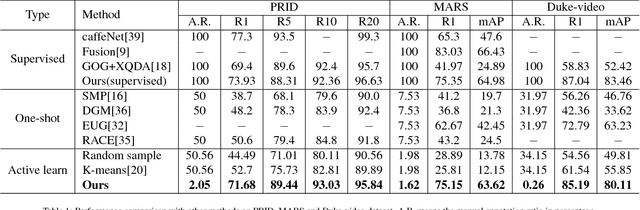
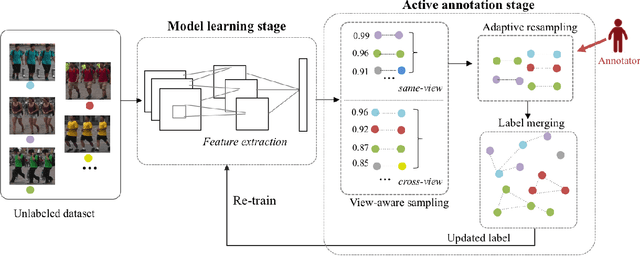

It is prohibitively expensive to annotate a large-scale video-based person re-identification (re-ID) dataset, which makes fully supervised methods inapplicable to real-world deployment. How to maximally reduce the annotation cost while retaining the re-ID performance becomes an interesting problem. In this paper, we address this problem by integrating an active learning scheme into a deep learning framework. Noticing that the truly matched tracklet-pairs, also denoted as true positives (TP), are the most informative samples for our re-ID model, we propose a sampling criterion to choose the most TP-likely tracklet-pairs for annotation. A view-aware sampling strategy considering view-specific biases is designed to facilitate candidate selection, followed by an adaptive resampling step to leave out the selected candidates that are unnecessary to annotate. Our method learns the re-ID model and updates the annotation set iteratively. The re-ID model is supervised by the tracklets' pesudo labels that are initialized by treating each tracklet as a distinct class. With the gained annotations of the actively selected candidates, the tracklets' pesudo labels are updated by label merging and further used to re-train our re-ID model. While being simple, the proposed method demonstrates its effectiveness on three video-based person re-ID datasets. Experimental results show that less than 3\% pairwise annotations are needed for our method to reach comparable performance with the fully-supervised setting.