 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Imbalance Continual Learning for Real-World Food Recognition
Mar 31, 2026Visual food recognition in real-world dietary logging scenarios naturally exhibits severe data imbalance, where a small number of food categories appear frequently while many others occur rarely, resulting in long-tailed class distributions. In practice, food recognition systems often operate in a continual learning setting, where new categories are introduced sequentially over time. However, existing studies typically assume that each incremental step introduces a similar number of new food classes, which rarely happens in real world where the number of newly observed categories can vary significantly across steps, leading to highly uneven learning dynamics. As a result, continual food recognition exhibits a dual imbalance: imbalanced samples within each food class and imbalanced numbers of new food classes to learn at each incremental learning step. In this work, we introduce DIME, a Dual-Imbalance-aware Adapter Merging framework for continual food recognition. DIME learns lightweight adapters for each task using parameter-efficient fine-tuning and progressively integrates them through a class-count guided spectral merging strategy. A rank-wise threshold modulation mechanism further stabilizes the merging process by preserving dominant knowledge while allowing adaptive updates. The resulting model maintains a single merged adapter for inference, enabling efficient deployment without accumulating task-specific modules. Experiments on realistic long-tailed food benchmarks under our step-imbalanced setup show that the proposed method consistently improves by more than 3% over the strongest existing continual learning baselines. Code is available at https://github.com/xiaoyanzhang1/DIME.
One Adapter for All: Towards Unified Representation in Step-Imbalanced Class-Incremental Learning
Mar 10, 2026Class-incremental learning (CIL) aims to acquire new classes over time while retaining prior knowledge, yet most setups and methods assume balanced task streams. In practice, the number of classes per task often varies significantly. We refer to this as step imbalance, where large tasks that contain more classes dominate learning and small tasks inject unstable updates. Existing CIL methods assume balanced tasks and therefore treat all tasks uniformly, producing imbalanced updates that degrade overall learning performance. To address this challenge, we propose One-A, a unified and imbalance-aware framework that incrementally merges task updates into a single adapter, maintaining constant inference cost. One-A performs asymmetric subspace alignment to preserve dominant subspaces learned from large tasks while constraining low-information updates within them. An information-adaptive weighting balances the contribution between base and new adapters, and a directional gating mechanism selectively fuses updates along each singular direction, maintaining stability in head directions and plasticity in tail ones. Across multiple benchmarks and step-imbalanced streams, One-A achieves competitive accuracy with significantly low inference overhead, showing that a single, asymmetrically fused adapter can remain both adaptive to dynamic task sizes and efficient at deployment.
SpatiaLQA: A Benchmark for Evaluating Spatial Logical Reasoning in Vision-Language Models
Feb 24, 2026Vision-Language Models (VLMs) have been increasingly applied in real-world scenarios due to their outstanding understanding and reasoning capabilities. Although VLMs have already demonstrated impressive capabilities in common visual question answering and logical reasoning, they still lack the ability to make reasonable decisions in complex real-world environments. We define this ability as spatial logical reasoning, which not only requires understanding the spatial relationships among objects in complex scenes, but also the logical dependencies between steps in multi-step tasks. To bridge this gap, we introduce Spatial Logical Question Answering (SpatiaLQA), a benchmark designed to evaluate the spatial logical reasoning capabilities of VLMs. SpatiaLQA consists of 9,605 question answer pairs derived from 241 real-world indoor scenes. We conduct extensive experiments on 41 mainstream VLMs, and the results show that even the most advanced models still struggle with spatial logical reasoning. To address this issue, we propose a method called recursive scene graph assisted reasoning, which leverages visual foundation models to progressively decompose complex scenes into task-relevant scene graphs, thereby enhancing the spatial logical reasoning ability of VLMs, outperforming all previous methods. Code and dataset are available at https://github.com/xieyc99/SpatiaLQA.
SIGMA: Selective-Interleaved Generation with Multi-Attribute Tokens
Feb 07, 2026Recent unified models such as Bagel demonstrate that paired image-edit data can effectively align multiple visual tasks within a single diffusion transformer. However, these models remain limited to single-condition inputs and lack the flexibility needed to synthesize results from multiple heterogeneous sources. We present SIGMA (Selective-Interleaved Generation with Multi-Attribute Tokens), a unified post-training framework that enables interleaved multi-condition generation within diffusion transformers. SIGMA introduces selective multi-attribute tokens, including style, content, subject, and identity tokens, which allow the model to interpret and compose multiple visual conditions in an interleaved text-image sequence. Through post-training on the Bagel unified backbone with 700K interleaved examples, SIGMA supports compositional editing, selective attribute transfer, and fine-grained multimodal alignment. Extensive experiments show that SIGMA improves controllability, cross-condition consistency, and visual quality across diverse editing and generation tasks, with substantial gains over Bagel on compositional tasks.
Dataset Ownership Verification for Pre-trained Masked Models
Jul 16, 2025High-quality open-source datasets have emerged as a pivotal catalyst driving the swift advancement of deep learning, while facing the looming threat of potential exploitation. Protecting these datasets is of paramount importance for the interests of their owners. The verification of dataset ownership has evolved into a crucial approach in this domain; however, existing verification techniques are predominantly tailored to supervised models and contrastive pre-trained models, rendering them ill-suited for direct application to the increasingly prevalent masked models. In this work, we introduce the inaugural methodology addressing this critical, yet unresolved challenge, termed Dataset Ownership Verification for Masked Modeling (DOV4MM). The central objective is to ascertain whether a suspicious black-box model has been pre-trained on a particular unlabeled dataset, thereby assisting dataset owners in safeguarding their rights. DOV4MM is grounded in our empirical observation that when a model is pre-trained on the target dataset, the difficulty of reconstructing masked information within the embedding space exhibits a marked contrast to models not pre-trained on that dataset. We validated the efficacy of DOV4MM through ten masked image models on ImageNet-1K and four masked language models on WikiText-103. The results demonstrate that DOV4MM rejects the null hypothesis, with a $p$-value considerably below 0.05, surpassing all prior approaches. Code is available at https://github.com/xieyc99/DOV4MM.
MFP3D: Monocular Food Portion Estimation Leveraging 3D Point Clouds
Nov 14, 2024



Food portion estimation is crucial for monitoring health and tracking dietary intake. Image-based dietary assessment, which involves analyzing eating occasion images using computer vision techniques, is increasingly replacing traditional methods such as 24-hour recalls. However, accurately estimating the nutritional content from images remains challenging due to the loss of 3D information when projecting to the 2D image plane. Existing portion estimation methods are challenging to deploy in real-world scenarios due to their reliance on specific requirements, such as physical reference objects, high-quality depth information, or multi-view images and videos. In this paper, we introduce MFP3D, a new framework for accurate food portion estimation using only a single monocular image. Specifically, MFP3D consists of three key modules: (1) a 3D Reconstruction Module that generates a 3D point cloud representation of the food from the 2D image, (2) a Feature Extraction Module that extracts and concatenates features from both the 3D point cloud and the 2D RGB image, and (3) a Portion Regression Module that employs a deep regression model to estimate the food's volume and energy content based on the extracted features. Our MFP3D is evaluated on MetaFood3D dataset, demonstrating its significant improvement in accurate portion estimation over existing methods.
Compression of enumerations and gain
Apr 06, 2023
We study the compressibility of enumerations, and its role in the relative Kolmogorov complexity of computably enumerable sets, with respect to density. With respect to a strong and a weak form of compression, we examine the gain: the amount of auxiliary information embedded in the compressed enumeration. Strong compression and weak gainless compression is shown for any computably enumerable set, and a positional game is studied toward understanding strong gainless compression.
Bayesian Optimization of 2D Echocardiography Segmentation
Nov 17, 2022



Bayesian Optimization (BO) is a well-studied hyperparameter tuning technique that is more efficient than grid search for high-cost, high-parameter machine learning problems. Echocardiography is a ubiquitous modality for evaluating heart structure and function in cardiology. In this work, we use BO to optimize the architectural and training-related hyperparameters of a previously published deep fully convolutional neural network model for multi-structure segmentation in echocardiography. In a fair comparison, the resulting model outperforms this recent state-of-the-art on the annotated CAMUS dataset in both apical two- and four-chamber echo views. We report mean Dice overlaps of 0.95, 0.96, and 0.93 on left ventricular (LV) endocardium, LV epicardium, and left atrium respectively. We also observe significant improvement in derived clinical indices, including smaller median absolute errors for LV end-diastolic volume (4.9mL vs. 6.7), end-systolic volume (3.1mL vs. 5.2), and ejection fraction (2.6% vs. 3.7); and much tighter limits of agreement, which were already within inter-rater variability for non-contrast echo. These results demonstrate the benefits of BO for echocardiography segmentation over a recent state-of-the-art framework, although validation using large-scale independent clinical data is required.
See Blue Sky: Deep Image Dehaze Using Paired and Unpaired Training Images
Oct 14, 2022
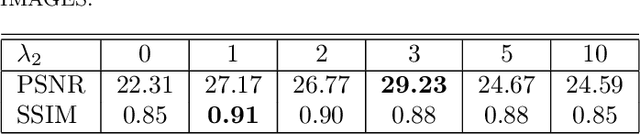
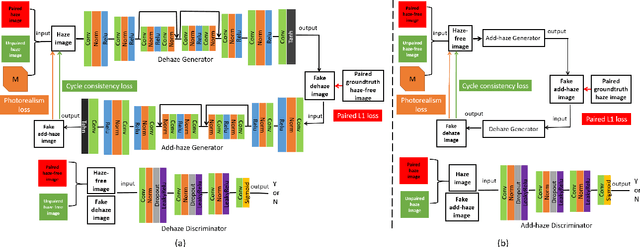
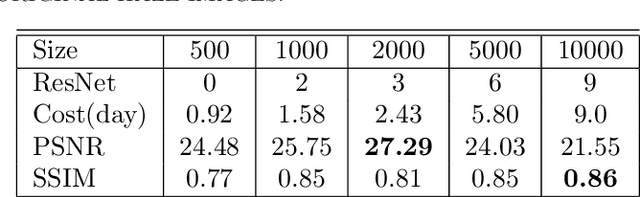
The issue of image haze removal has attracted wide attention in recent years. However, most existing haze removal methods cannot restore the scene with clear blue sky, since the color and texture information of the object in the original haze image is insufficient. To remedy this, we propose a cycle generative adversarial network to construct a novel end-to-end image dehaze model. We adopt outdoor image datasets to train our model, which includes a set of real-world unpaired image dataset and a set of paired image dataset to ensure that the generated images are close to the real scene. Based on the cycle structure, our model adds four different kinds of loss function to constrain the effect including adversarial loss, cycle consistency loss, photorealism loss and paired L1 loss. These four constraints can improve the overall quality of such degraded images for better visual appeal and ensure reconstruction of images to keep from distortion. The proposed model could remove the haze of images and also restore the sky of images to be clean and blue (like captured in a sunny weather).