 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIGaussian: Disentangle Gaussians for Spatial-Awared Text-Image-3D Alignment
Jan 27, 2026While visual-language models have profoundly linked features between texts and images, the incorporation of 3D modality data, such as point clouds and 3D Gaussians, further enables pretraining for 3D-related tasks, e.g., cross-modal retrieval, zero-shot classification, and scene recognition. As challenges remain in extracting 3D modal features and bridging the gap between different modalities, we propose TIGaussian, a framework that harnesses 3D Gaussian Splatting (3DGS) characteristics to strengthen cross-modality alignment through multi-branch 3DGS tokenizer and modality-specific 3D feature alignment strategies. Specifically, our multi-branch 3DGS tokenizer decouples the intrinsic properties of 3DGS structures into compact latent representations, enabling more generalizable feature extraction. To further bridge the modality gap, we develop a bidirectional cross-modal alignment strategies: a multi-view feature fusion mechanism that leverages diffusion priors to resolve perspective ambiguity in image-3D alignment, while a text-3D projection module adaptively maps 3D features to text embedding space for better text-3D alignment. Extensive experiments on various datasets demonstrate the state-of-the-art performance of TIGaussian in multiple tasks.
Replay Failures as Successes: Sample-Efficient Reinforcement Learning for Instruction Following
Dec 29, 2025Reinforcement Learning (RL) has shown promise for aligning Large Language Models (LLMs) to follow instructions with various constraints. Despite the encouraging results, RL improvement inevitably relies on sampling successful, high-quality responses; however, the initial model often struggles to generate responses that satisfy all constraints due to its limited capabilities, yielding sparse or indistinguishable rewards that impede learning. In this work, we propose Hindsight instruction Replay (HiR), a novel sample-efficient RL framework for complex instruction following tasks, which employs a select-then-rewrite strategy to replay failed attempts as successes based on the constraints that have been satisfied in hindsight. We perform RL on these replayed samples as well as the original ones, theoretically framing the objective as dual-preference learning at both the instruction- and response-level to enable efficient optimization using only a binary reward signal. Extensive experiments demonstrate that the proposed HiR yields promising results across different instruction following tasks, while requiring less computational budget. Our code and dataset is available at https://github.com/sastpg/HIR.
LiDAR-GS++:Improving LiDAR Gaussian Reconstruction via Diffusion Priors
Nov 15, 2025



Recent GS-based rendering has made significant progress for LiDAR, surpassing Neural Radiance Fields (NeRF) in both quality and speed. However, these methods exhibit artifacts in extrapolated novel view synthesis due to the incomplete reconstruction from single traversal scans. To address this limitation, we present LiDAR-GS++, a LiDAR Gaussian Splatting reconstruction method enhanced by diffusion priors for real-time and high-fidelity re-simulation on public urban roads. Specifically, we introduce a controllable LiDAR generation model conditioned on coarsely extrapolated rendering to produce extra geometry-consistent scans and employ an effective distillation mechanism for expansive reconstruction. By extending reconstruction to under-fitted regions, our approach ensures global geometric consistency for extrapolative novel views while preserving detailed scene surfaces captured by sensors. Experiments on multiple public datasets demonstrate that LiDAR-GS++ achieves state-of-the-art performance for both interpolated and extrapolated viewpoints, surpassing existing GS and NeRF-based methods.
Industrial-Grade Sensor Simulation via Gaussian Splatting: A Modular Framework for Scalable Editing and Full-Stack Validation
Mar 14, 2025Sensor simulation is pivotal for scalable validation of autonomous driving systems, yet existing Neural Radiance Fields (NeRF) based methods face applicability and efficiency challenges in industrial workflows. This paper introduces a Gaussian Splatting (GS) based system to address these challenges: We first break down sensor simulator components and analyze the possible advantages of GS over NeRF. Then in practice, we refactor three crucial components through GS, to leverage its explicit scene representation and real-time rendering: (1) choosing the 2D neural Gaussian representation for physics-compliant scene and sensor modeling, (2) proposing a scene editing pipeline to leverage Gaussian primitives library for data augmentation, and (3) coupling a controllable diffusion model for scene expansion and harmonization. We implement this framework on a proprietary autonomous driving dataset supporting cameras and LiDAR sensors. We demonstrate through ablation studies that our approach reduces frame-wise simulation latency, achieves better geometric and photometric consistency, and enables interpretable explicit scene editing and expansion. Furthermore, we showcase how integrating such a GS-based sensor simulator with traffic and dynamic simulators enables full-stack testing of end-to-end autonomy algorithms. Our work provides both algorithmic insights and practical validation, establishing GS as a cornerstone for industrial-grade sensor simulation.
Reference Neural Operators: Learning the Smooth Dependence of Solutions of PDEs on Geometric Deformations
May 27, 2024



For partial differential equations on domains of arbitrary shapes, existing works of neural operators attempt to learn a mapping from geometries to solutions. It often requires a large dataset of geometry-solution pairs in order to obtain a sufficiently accurate neural operator. However, for many industrial applications, e.g., engineering design optimization, it can be prohibitive to satisfy the requirement since even a single simulation may take hours or days of computation. To address this issue, we propose reference neural operators (RNO), a novel way of implementing neural operators, i.e., to learn the smooth dependence of solutions on geometric deformations. Specifically, given a reference solution, RNO can predict solutions corresponding to arbitrary deformations of the referred geometry. This approach turns out to be much more data efficient. Through extensive experiments, we show that RNO can learn the dependence across various types and different numbers of geometry objects with relatively small datasets. RNO outperforms baseline models in accuracy by a large lead and achieves up to 80% error reduction.
View-Centric Multi-Object Tracking with Homographic Matching in Moving UAV
Mar 16, 2024



In this paper, we address the challenge of multi-object tracking (MOT) in moving Unmanned Aerial Vehicle (UAV) scenarios, where irregular flight trajectories, such as hovering, turning left/right, and moving up/down, lead to significantly greater complexity compared to fixed-camera MOT. Specifically, changes in the scene background not only render traditional frame-to-frame object IOU association methods ineffective but also introduce significant view shifts in the objects, which complicates tracking. To overcome these issues, we propose a novel universal HomView-MOT framework, which for the first time, harnesses the view Homography inherent in changing scenes to solve MOT challenges in moving environments, incorporating Homographic Matching and View-Centric concepts. We introduce a Fast Homography Estimation (FHE) algorithm for rapid computation of Homography matrices between video frames, enabling object View-Centric ID Learning (VCIL) and leveraging multi-view Homography to learn cross-view ID features. Concurrently, our Homographic Matching Filter (HMF) maps object bounding boxes from different frames onto a common view plane for a more realistic physical IOU association. Extensive experiments have proven that these innovations allow HomView-MOT to achieve state-of-the-art performance on prominent UAV MOT datasets VisDrone and UAVDT.
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023



Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.
PANet: Perspective-Aware Network with Dynamic Receptive Fields and Self-Distilling Supervision for Crowd Counting
Oct 31, 2021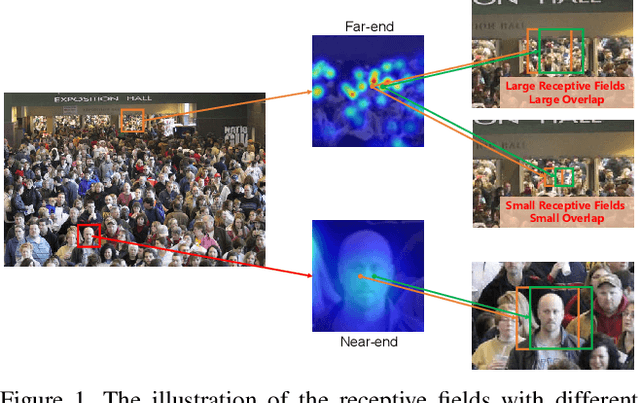
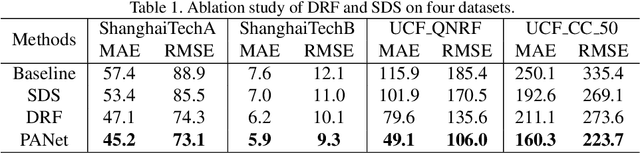
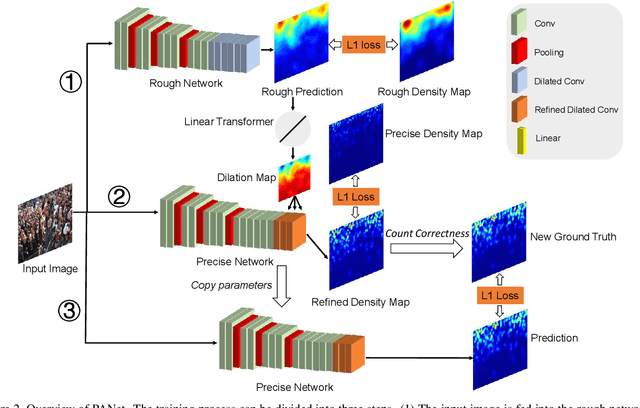

Crowd counting aims to learn the crowd density distributions and estimate the number of objects (e.g. persons) in images. The perspective effect, which significantly influences the distribution of data points, plays an important role in crowd counting. In this paper, we propose a novel perspective-aware approach called PANet to address the perspective problem. Based on the observation that the size of the objects varies greatly in one image due to the perspective effect, we propose the dynamic receptive fields (DRF) framework. The framework is able to adjust the receptive field by the dilated convolution parameters according to the input image, which helps the model to extract more discriminative features for each local region. Different from most previous works which use Gaussian kernels to generate the density map as the supervised information, we propose the self-distilling supervision (SDS) training method. The ground-truth density maps are refined from the first training stage and the perspective information is distilled to the model in the second stage. The experimental results on ShanghaiTech Part_A and Part_B, UCF_QNRF, and UCF_CC_50 datasets demonstrate that our proposed PANet outperforms the state-of-the-art methods by a large margin.
Learning deep representation from coarse to fine for face alignment
Jul 31, 2016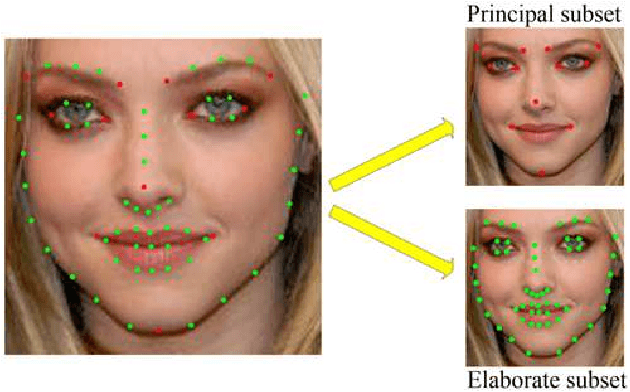
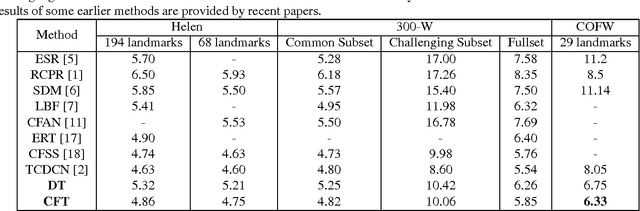
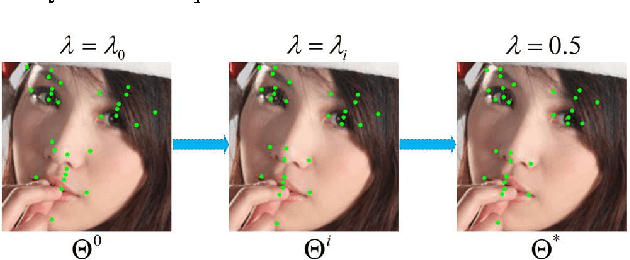
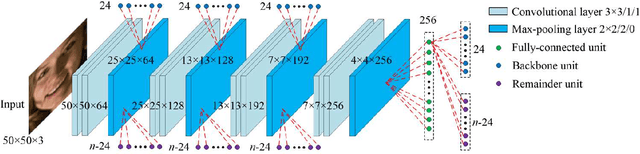
In this paper, we propose a novel face alignment method that trains deep convolutional network from coarse to fine. It divides given landmarks into principal subset and elaborate subset. We firstly keep a large weight for principal subset to make our network primarily predict their locations while slightly take elaborate subset into account. Next the weight of principal subset is gradually decreased until two subsets have equivalent weights. This process contributes to learn a good initial model and search the optimal model smoothly to avoid missing fairly good intermediate models in subsequent procedures. On the challenging COFW dataset [1], our method achieves 6.33% mean error with a reduction of 21.37% compared with the best previous result [2].