 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplay Failures as Successes: Sample-Efficient Reinforcement Learning for Instruction Following
Dec 29, 2025Reinforcement Learning (RL) has shown promise for aligning Large Language Models (LLMs) to follow instructions with various constraints. Despite the encouraging results, RL improvement inevitably relies on sampling successful, high-quality responses; however, the initial model often struggles to generate responses that satisfy all constraints due to its limited capabilities, yielding sparse or indistinguishable rewards that impede learning. In this work, we propose Hindsight instruction Replay (HiR), a novel sample-efficient RL framework for complex instruction following tasks, which employs a select-then-rewrite strategy to replay failed attempts as successes based on the constraints that have been satisfied in hindsight. We perform RL on these replayed samples as well as the original ones, theoretically framing the objective as dual-preference learning at both the instruction- and response-level to enable efficient optimization using only a binary reward signal. Extensive experiments demonstrate that the proposed HiR yields promising results across different instruction following tasks, while requiring less computational budget. Our code and dataset is available at https://github.com/sastpg/HIR.
Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning
Jun 10, 2025Recent advances of Reinforcement Learning (RL) have highlighted its potential in complex reasoning tasks, yet effective training often relies on external supervision, which limits the broader applicability. In this work, we propose a novel self-rewarding reinforcement learning framework to enhance Large Language Model (LLM) reasoning by leveraging the consistency of intermediate reasoning states across different reasoning trajectories. Our key insight is that correct responses often exhibit consistent trajectory patterns in terms of model likelihood: their intermediate reasoning states tend to converge toward their own final answers (high consistency) with minimal deviation toward other candidates (low volatility). Inspired by this observation, we introduce CoVo, an intrinsic reward mechanism that integrates Consistency and Volatility via a robust vector-space aggregation strategy, complemented by a curiosity bonus to promote diverse exploration. CoVo enables LLMs to perform RL in a self-rewarding manner, offering a scalable pathway for learning to reason without external supervision. Extensive experiments on diverse reasoning benchmarks show that CoVo achieves performance comparable to or even surpassing supervised RL. Our code is available at https://github.com/sastpg/CoVo.
GarmentDiffusion: 3D Garment Sewing Pattern Generation with Multimodal Diffusion Transformers
Apr 30, 2025



Garment sewing patterns are fundamental design elements that bridge the gap between design concepts and practical manufacturing. The generative modeling of sewing patterns is crucial for creating diversified garments. However, existing approaches are limited either by reliance on a single input modality or by suboptimal generation efficiency. In this work, we present \textbf{\textit{GarmentDiffusion}}, a new generative model capable of producing centimeter-precise, vectorized 3D sewing patterns from multimodal inputs (text, image, and incomplete sewing pattern). Our method efficiently encodes 3D sewing pattern parameters into compact edge token representations, achieving a sequence length that is $\textbf{10}\times$ shorter than that of the autoregressive SewingGPT in DressCode. By employing a diffusion transformer, we simultaneously denoise all edge tokens along the temporal axis, while maintaining a constant number of denoising steps regardless of dataset-specific edge and panel statistics. With all combination of designs of our model, the sewing pattern generation speed is accelerated by $\textbf{100}\times$ compared to SewingGPT. We achieve new state-of-the-art results on DressCodeData, as well as on the largest sewing pattern dataset, namely GarmentCodeData. The project website is available at https://shenfu-research.github.io/Garment-Diffusion/.
Reasoning with Reinforced Functional Token Tuning
Feb 19, 2025



In this work, we propose Reinforced Functional Token Tuning (RFTT), a novel reinforced fine-tuning framework that empowers Large Language Models (LLMs) with self-play learn-to-reason capabilities. Unlike prior prompt-driven reasoning efforts, RFTT embeds a rich set of learnable functional tokens (e.g., <analyze>, <verify>, <refine>) directly into the model vocabulary, enabling chain-of-thought construction with diverse human-like reasoning behaviors. Specifically, RFTT comprises two phases: (1) supervised fine-tuning performs prompt-driven tree search to obtain self-generated training data annotated with functional tokens, which warms up the model to learn these tokens for reasoning; and (2) online reinforcement learning further allows the model to explore different reasoning pathways through functional token sampling without relying on prompts, thereby facilitating effective self-improvement for functional reasoning. Extensive experiments demonstrate the superiority of the proposed RFTT on mathematical benchmarks, significantly boosting Qwen-2.5-7B-Instruct (70.6% to 79.8%) and LLaMA-3.1-8B-Instruct (32.2% to 60.2%) on the MATH dataset. Moreover, the performance of RFTT consistently improves with more search rollouts at inference time. Our code is available at https://github.com/sastpg/RFTT.
Controlling Character Motions without Observable Driving Source
Aug 11, 2023



How to generate diverse, life-like, and unlimited long head/body sequences without any driving source? We argue that this under-investigated research problem is non-trivial at all, and has unique technical challenges behind it. Without semantic constraints from the driving sources, using the standard autoregressive model to generate infinitely long sequences would easily result in 1) out-of-distribution (OOD) issue due to the accumulated error, 2) insufficient diversity to produce natural and life-like motion sequences and 3) undesired periodic patterns along the time. To tackle the above challenges, we propose a systematic framework that marries the benefits of VQ-VAE and a novel token-level control policy trained with reinforcement learning using carefully designed reward functions. A high-level prior model can be easily injected on top to generate unlimited long and diverse sequences. Although we focus on no driving sources now, our framework can be generalized for controlled synthesis with explicit driving sources. Through comprehensive evaluations, we conclude that our proposed framework can address all the above-mentioned challenges and outperform other strong baselines very significantly.
Weakly Supervised Detection of Baby Cry
Apr 19, 2023



Detection of baby cries is an important part of baby monitoring and health care. Almost all existing methods use supervised SVM, CNN, or their varieties. In this work, we propose to use weakly supervised anomaly detection to detect a baby cry. In this weak supervision, we only need weak annotation if there is a cry in an audio file. We design a data mining technique using the pre-trained VGGish feature extractor and an anomaly detection network on long untrimmed audio files. The obtained datasets are used to train a simple CNN feature network for cry/non-cry classification. This CNN is then used as a feature extractor in an anomaly detection framework to achieve better cry detection performance.
Overlooked Video Classification in Weakly Supervised Video Anomaly Detection
Oct 13, 2022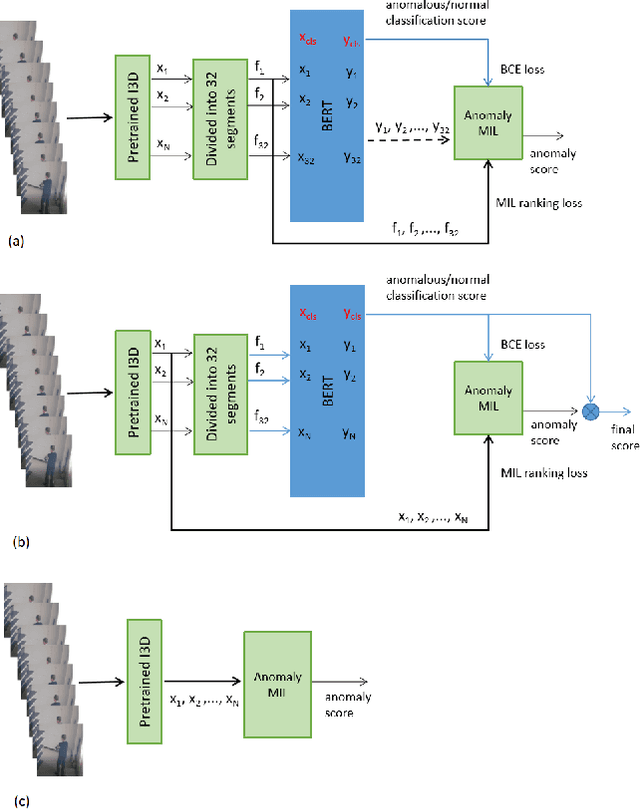
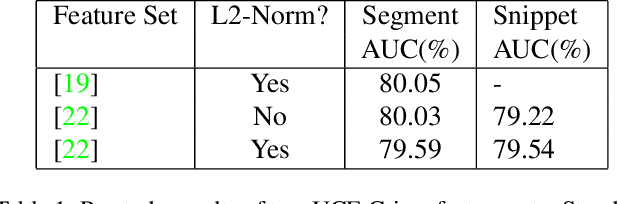
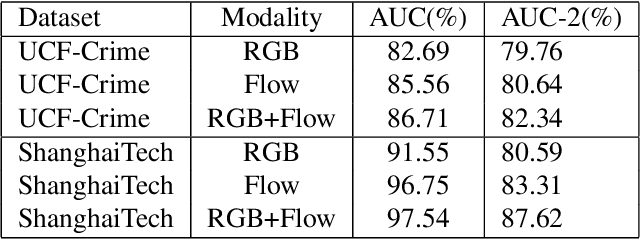
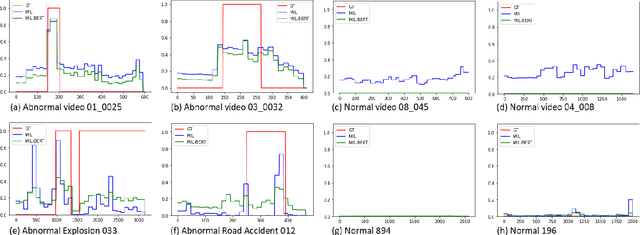
Current weakly supervised video anomaly detection algorithms mostly use multiple instance learning (MIL) or their varieties. Almost all recent approaches focus on how to select the correct snippets for training to improve the performance. They overlook or do not realize the power of video classification in boosting the performance of anomaly detection. In this paper, we study explicitly the power of video classification supervision using a BERT or LSTM. With this BERT or LSTM, CNN features of all snippets of a video can be aggregated into a single feature which can be used for video classification. This simple yet powerful video classification supervision, combined into the MIL framework, brings extraordinary performance improvement on all three major video anomaly detection datasets. Particularly it improves the mean average precision (mAP) on the XD-Violence from SOTA 78.84\% to new 82.10\%. The source code is available at https://github.com/wjtan99/BERT_Anomaly_Video_Classification.
Two-Stage COVID19 Classification Using BERT Features
Jun 29, 2022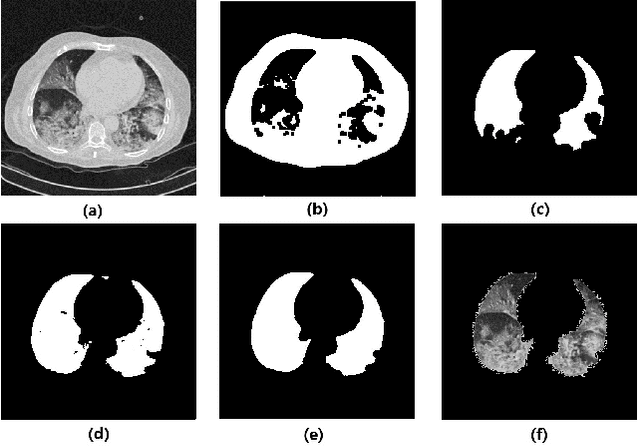
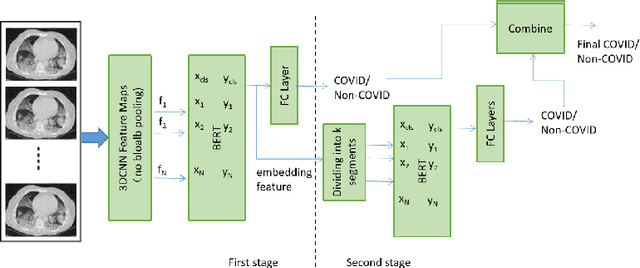
We propose an automatic COVID1-19 diagnosis framework from lung CT-scan slice images using double BERT feature extraction. In the first BERT feature extraction, A 3D-CNN is first used to extract CNN internal feature maps. Instead of using the global average pooling, a late BERT temporal pooing is used to aggregate the temporal information in these feature maps, followed by a classification layer. This 3D-CNN-BERT classification network is first trained on sampled fixed number of slice images from every original CT scan volume. In the second stage, the 3D-CNN-BERT embedding features are extracted on all slice images of every CT scan volume, and these features are averaged into a fixed number of segments. Then another BERT network is used to aggregate these multiple features into a single feature followed by another classification layer. The classification results of both stages are combined to generate final outputs. On the validation dataset, we achieve macro F1 score of 0.9164.
Balanced Masked and Standard Face Recognition
Oct 04, 2021
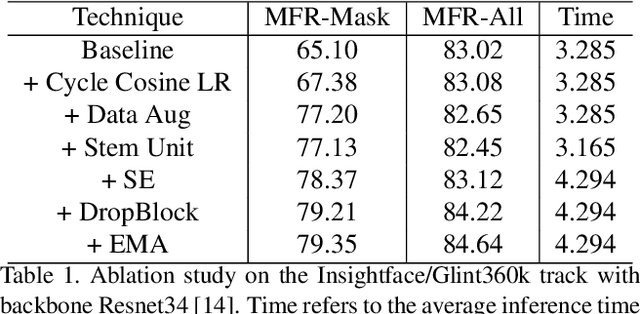
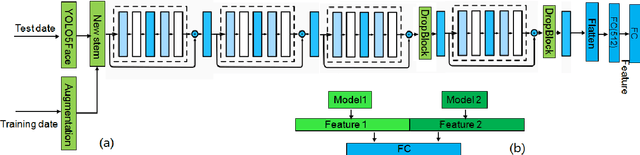
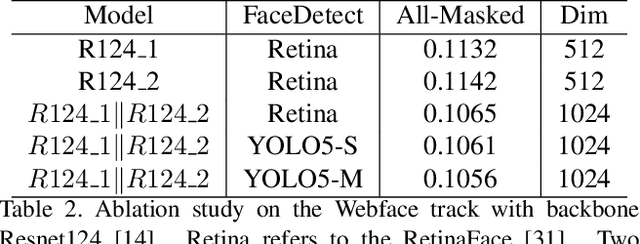
We present the improved network architecture, data augmentation, and training strategies for the Webface track and Insightface/Glint360K track of the masked face recognition challenge of ICCV2021. One of the key goals is to have a balanced performance of masked and standard face recognition. In order to prevent the overfitting for the masked face recognition, we control the total number of masked faces by not more than 10\% of the total face recognition in the training dataset. We propose a few key changes to the face recognition network including a new stem unit, drop block, face detection and alignment using YOLO5Face, feature concatenation, a cycle cosine learning rate, etc. With this strategy, we achieve good and balanced performance for both masked and standard face recognition.
YOLO5Face: Why Reinventing a Face Detector
May 27, 2021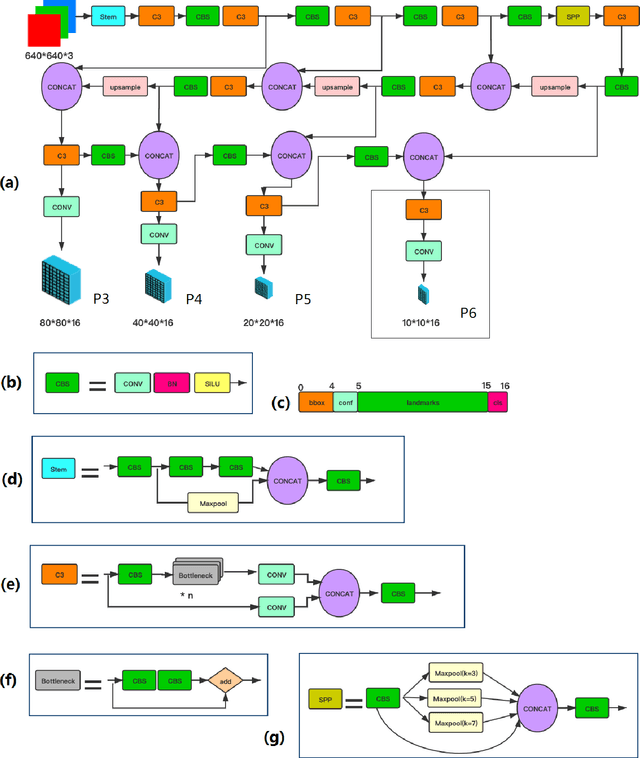
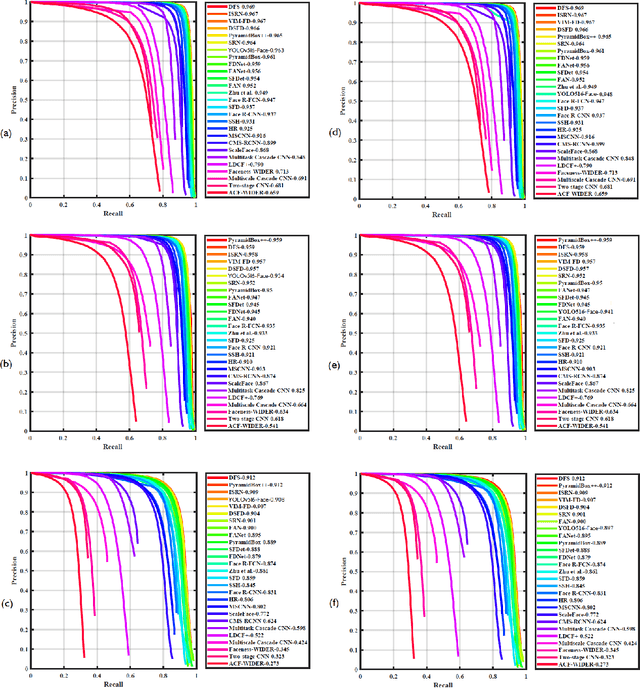
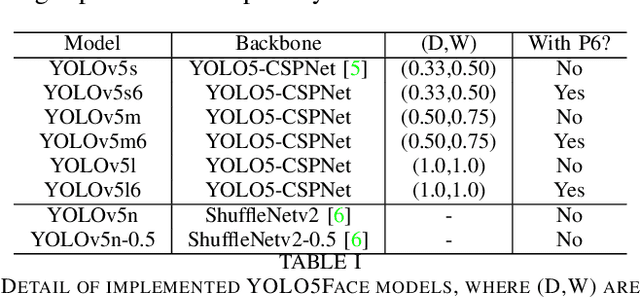
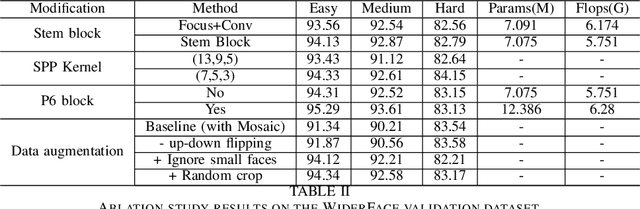
Tremendous progress has been made on face detection in recent years using convolutional neural networks. While many face detectors use designs designated for the detection of face, we treat face detection as a general object detection task. We implement a face detector based on YOLOv5 object detector and call it YOLO5Face. We add a five-point landmark regression head into it and use the Wing loss function. We design detectors with different model sizes, from a large model to achieve the best performance, to a super small model for real-time detection on an embedded or mobile device. Experiment results on the WiderFace dataset show that our face detectors can achieve state-of-the-art performance in almost all the Easy, Medium, and Hard subsets, exceeding the more complex designated face detectors. The code is available at \url{https://www.github.com/deepcam-cn/yolov5-face}.