 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deterministic Agentic Workflow for HS Tariff Classification: Multi-Dimensional Rule Reasoning with Interpretable Decisions
May 14, 2026Harmonized System (HS) tariff classification is a high-stakes, expert-level task in which a free-form product description must be mapped to a specific six- or eight-digit code under the General Interpretive Rules (GIR), section notes, chapter notes, and Explanatory Notes. The difficulty lies not in knowledge volume but in *multi-dimensional rule reasoning*: a correct classification must satisfy competing priority rules along several axes simultaneously, including material, form, function, essential character, the part-versus-whole boundary, and specific listing versus residual headings. End-to-end prompting of large language models fails characteristically by resolving one axis while ignoring the priority constraints on the others. We present a *deterministic agentic workflow* in contrast to self-planning agents: the control flow is fixed, language model calls are confined to narrow stages, and reflection and verification are retained as local mechanisms. This design yields interpretability by construction--each decision is decomposed into stage-wise structured outputs with verbatim citation of the chapter or section notes that bear on it. The architecture combines offline knowledge-engineering of the Chinese HS tariff with an online six-stage pipeline. Evaluated on HSCodeComp at the six-digit level, the workflow reaches 75.0% top-1 and 91.5% top-3 at four digits, and 64.2% top-1 and 78.3% top-3 at six digits with Qwen3.6-plus; an open-weight Qwen3.6-27B-FP8 backbone in non-thinking mode achieves 84.2% four-digit and 77.4% six-digit top-1 agreement with the frontier model. A two-stage manual audit of 226 six-digit disagreements suggests that a non-trivial fraction of HSCodeComp ground-truth labels may deviate from HS general rules; full adjudication records are released in the appendix as preliminary findings for community review.
TiPToP: A Modular Open-Vocabulary Planning System for Robotic Manipulation
Mar 10, 2026We present TiPToP, an extensible modular system that combines pretrained vision foundation models with an existing Task and Motion Planner (TAMP) to solve multi-step manipulation tasks directly from input RGB images and natural-language instructions. Our system aims to be simple and easy-to-use: it can be installed and run on a standard DROID setup in under one hour and adapted to new embodiments with minimal effort. We evaluate TiPToP -- which requires zero robot data -- over 28 tabletop manipulation tasks in simulation and the real world and find it matches or outperforms $π_{0.5}\text{-DROID}$, a vision-language-action (VLA) model fine-tuned on 350 hours of embodiment-specific demonstrations. TiPToP's modular architecture enables us to analyze the system's failure modes at the component level. We analyze results from an evaluation of 173 trials and identify directions for improvement. We release TiPToP open-source to further research on modular manipulation systems and tighter integration between learning and planning. Project website and code: https://tiptop-robot.github.io
Follow the Signs: Using Textual Cues and LLMs to Guide Efficient Robot Navigation
Jan 10, 2026Autonomous navigation in unfamiliar environments often relies on geometric mapping and planning strategies that overlook rich semantic cues such as signs, room numbers, and textual labels. We propose a novel semantic navigation framework that leverages large language models (LLMs) to infer patterns from partial observations and predict regions where the goal is most likely located. Our method combines local perceptual inputs with frontier-based exploration and periodic LLM queries, which extract symbolic patterns (e.g., room numbering schemes and building layout structures) and update a confidence grid used to guide exploration. This enables robots to move efficiently toward goal locations labeled with textual identifiers (e.g., "room 8") even before direct observation. We demonstrate that this approach enables more efficient navigation in sparse, partially observable grid environments by exploiting symbolic patterns. Experiments across environments modeled after real floor plans show that our approach consistently achieves near-optimal paths and outperforms baselines by over 25% in Success weighted by Path Length.
Learning Depth from Past Selves: Self-Evolution Contrast for Robust Depth Estimation
Nov 19, 2025Self-supervised depth estimation has gained significant attention in autonomous driving and robotics. However, existing methods exhibit substantial performance degradation under adverse weather conditions such as rain and fog, where reduced visibility critically impairs depth prediction. To address this issue, we propose a novel self-evolution contrastive learning framework called SEC-Depth for self-supervised robust depth estimation tasks. Our approach leverages intermediate parameters generated during training to construct temporally evolving latency models. Using these, we design a self-evolution contrastive scheme to mitigate performance loss under challenging conditions. Concretely, we first design a dynamic update strategy of latency models for the depth estimation task to capture optimization states across training stages. To effectively leverage latency models, we introduce a self-evolution contrastive Loss (SECL) that treats outputs from historical latency models as negative samples. This mechanism adaptively adjusts learning objectives while implicitly sensing weather degradation severity, reducing the needs for manual intervention. Experiments show that our method integrates seamlessly into diverse baseline models and significantly enhances robustness in zero-shot evaluations.
Mixture-of-Schedulers: An Adaptive Scheduling Agent as a Learned Router for Expert Policies
Nov 07, 2025Modern operating system schedulers employ a single, static policy, which struggles to deliver optimal performance across the diverse and dynamic workloads of contemporary systems. This "one-policy-fits-all" approach leads to significant compromises in fairness, throughput, and latency, particularly with the rise of heterogeneous hardware and varied application architectures. This paper proposes a new paradigm: dynamically selecting the optimal policy from a portfolio of specialized schedulers rather than designing a single, monolithic one. We present the Adaptive Scheduling Agent (ASA), a lightweight framework that intelligently matches workloads to the most suitable "expert" scheduling policy at runtime. ASA's core is a novel, low-overhead offline/online approach. First, an offline process trains a universal, hardware-agnostic machine learning model to recognize abstract workload patterns from system behaviors. Second, at runtime, ASA continually processes the model's predictions using a time-weighted probability voting algorithm to identify the workload, then makes a scheduling decision by consulting a pre-configured, machine-specific mapping table to switch to the optimal scheduler via Linux's sched_ext framework. This decoupled architecture allows ASA to adapt to new hardware platforms rapidly without expensive retraining of the core recognition model. Our evaluation, based on a novel benchmark focused on user-experience metrics, demonstrates that ASA consistently outperforms the default Linux scheduler (EEVDF), achieving superior results in 86.4% of test scenarios. Furthermore, ASA's selections are near-optimal, ranking among the top three schedulers in 78.6% of all scenarios. This validates our approach as a practical path toward more intelligent, adaptive, and responsive operating system schedulers.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
Always Clear Depth: Robust Monocular Depth Estimation under Adverse Weather
May 18, 2025
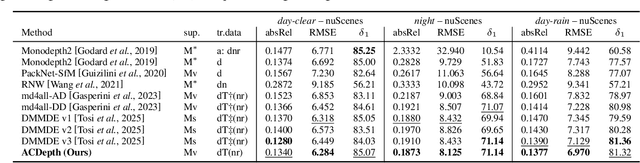
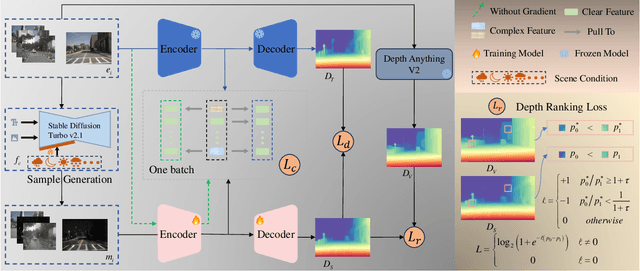
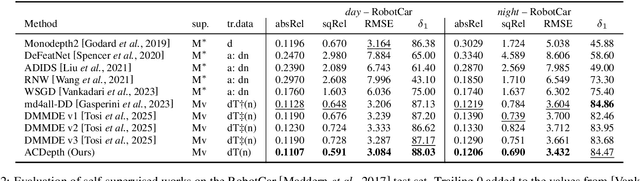
Monocular depth estimation is critical for applications such as autonomous driving and scene reconstruction. While existing methods perform well under normal scenarios, their performance declines in adverse weather, due to challenging domain shifts and difficulties in extracting scene information. To address this issue, we present a robust monocular depth estimation method called \textbf{ACDepth} from the perspective of high-quality training data generation and domain adaptation. Specifically, we introduce a one-step diffusion model for generating samples that simulate adverse weather conditions, constructing a multi-tuple degradation dataset during training. To ensure the quality of the generated degradation samples, we employ LoRA adapters to fine-tune the generation weights of diffusion model. Additionally, we integrate circular consistency loss and adversarial training to guarantee the fidelity and naturalness of the scene contents. Furthermore, we elaborate on a multi-granularity knowledge distillation strategy (MKD) that encourages the student network to absorb knowledge from both the teacher model and pretrained Depth Anything V2. This strategy guides the student model in learning degradation-agnostic scene information from various degradation inputs. In particular, we introduce an ordinal guidance distillation mechanism (OGD) that encourages the network to focus on uncertain regions through differential ranking, leading to a more precise depth estimation. Experimental results demonstrate that our ACDepth surpasses md4all-DD by 2.50\% for night scene and 2.61\% for rainy scene on the nuScenes dataset in terms of the absRel metric.
PANDA -- Paired Anti-hate Narratives Dataset from Asia: Using an LLM-as-a-Judge to Create the First Chinese Counterspeech Dataset
Jan 04, 2025Despite the global prevalence of Modern Standard Chinese language, counterspeech (CS) resources for Chinese remain virtually nonexistent. To address this gap in East Asian counterspeech research we introduce the a corpus of Modern Standard Mandarin counterspeech that focuses on combating hate speech in Mainland China. This paper proposes a novel approach of generating CS by using an LLM-as-a-Judge, simulated annealing, LLMs zero-shot CN generation and a round-robin algorithm. This is followed by manual verification for quality and contextual relevance. This paper details the methodology for creating effective counterspeech in Chinese and other non-Eurocentric languages, including unique cultural patterns of which groups are maligned and linguistic patterns in what kinds of discourse markers are programmatically marked as hate speech (HS). Analysis of the generated corpora, we provide strong evidence for the lack of open-source, properly labeled Chinese hate speech data and the limitations of using an LLM-as-Judge to score possible answers in Chinese. Moreover, the present corpus serves as the first East Asian language based CS corpus and provides an essential resource for future research on counterspeech generation and evaluation.
Trust the PRoC3S: Solving Long-Horizon Robotics Problems with LLMs and Constraint Satisfaction
Jun 08, 2024Recent developments in pretrained large language models (LLMs) applied to robotics have demonstrated their capacity for sequencing a set of discrete skills to achieve open-ended goals in simple robotic tasks. In this paper, we examine the topic of LLM planning for a set of continuously parameterized skills whose execution must avoid violations of a set of kinematic, geometric, and physical constraints. We prompt the LLM to output code for a function with open parameters, which, together with environmental constraints, can be viewed as a Continuous Constraint Satisfaction Problem (CCSP). This CCSP can be solved through sampling or optimization to find a skill sequence and continuous parameter settings that achieve the goal while avoiding constraint violations. Additionally, we consider cases where the LLM proposes unsatisfiable CCSPs, such as those that are kinematically infeasible, dynamically unstable, or lead to collisions, and re-prompt the LLM to form a new CCSP accordingly. Experiments across three different simulated 3D domains demonstrate that our proposed strategy, PRoC3S, is capable of solving a wide range of complex manipulation tasks with realistic constraints on continuous parameters much more efficiently and effectively than existing baselines.
MMToM-QA: Multimodal Theory of Mind Question Answering
Jan 16, 2024



Theory of Mind (ToM), the ability to understand people's minds, is an essential ingredient for developing machines with human-level social intelligence. Recent machine learning models, particularly large language models, seem to show some aspects of ToM understanding. However, existing ToM benchmarks use unimodal datasets - either video or text. Human ToM, on the other hand, is more than video or text understanding. People can flexibly reason about another person's mind based on conceptual representations (e.g., goals, beliefs, plans) extracted from any available data, which can include visual cues, linguistic narratives, or both. To address this, we introduce a multimodal Theory of Mind question answering (MMToM-QA) benchmark. MMToM-QA comprehensively evaluates machine ToM both on multimodal data and on different kinds of unimodal data about a person's activity in a household environment. To engineer multimodal ToM capacity, we propose a novel method, BIP-ALM (Bayesian Inverse Planning Accelerated by Language Models). BIP-ALM extracts unified representations from multimodal data and utilizes language models for scalable Bayesian inverse planning. We conducted a systematic comparison of human performance, BIP-ALM, and state-of-the-art models, including GPT-4. The experiments demonstrate that large language models and large multimodal models still lack robust ToM capacity. BIP-ALM, on the other hand, shows promising results, by leveraging the power of both model-based mental inference and language models.