 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous heterogeneous catalyst discovery with a self-evolving multi-agent digital twin
Jun 03, 2026Theoretical heterogeneous catalysis promises rapid catalyst discovery, yet computational and machine-learning predictions often deviate from experiment and stay confined to narrow material families, for want of a faithful, condition-aware catalytic simulator. We present CatDT (Catalysis Digital Twin), a self-evolving multi-agent system that builds an autonomous digital twin of a working catalyst, unifying gas-solid and liquid-solid modeling. From only a bulk crystal and a natural-language reaction description, eight specialized agents and 27 scientific tools predict stable facets, reconstruct working surfaces, enumerate and rank reaction pathways, locate transition states, and compute kinetics in 5-30 min on a single GPU. Two innovations address the hardest steps: UniMech finds dominant pathways for novel materials at over $10^3\times$ lower cost than exhaustive enumeration by fusing agent-guided proposals with energy-cached graph search, and a memory-augmented reinforcement loop raises barrier-calculation success from 41\% to 84\% across 600 catalytic surfaces. Across seven gas-solid benchmarks -- stepped metals, single-atom catalysts, ordered intermetallics, vacancy-rich 2D sulfides and carbides, and a strong-metal--support-interaction (SMSI) interface -- every CatDT prediction lies within 0.5-2 times experiment over four orders of magnitude. For propane dehydrogenation, CatDT independently discovers non-precious candidates rivaling the Pt-based industrial benchmark, with a proposed Ni@ZrO$_2$ SMSI overlayer reaching a simulated TOF of $1.63~\text{s}^{-1}$ at $\sim$100\% selectivity. More broadly, the decisive factor for a faithful catalyst digital twin -- or any multi-stage scientific simulator -- is not raw LLM capability but the engineered harness around it: deterministic tools, persistent memory, and verified self-improvement that compound across models, tools, and runs.
LoViF 2026 The First Challenge on Holistic Quality Assessment for 4D World Model (PhyScore)
May 06, 2026This paper reports on the LoViF 2026 PhyScore challenge, a competition on holistic quality assessment of world-model-generated videos across both 2D and 4D generation settings. The challenge is motivated by a central gap in current evaluation practice: perceptual quality alone is insufficient to judge whether generated dynamics are physically plausible, temporally coherent, and consistent with input conditions. Participants are required to build a metric that jointly predicts four dimensions, i.e., Video Quality, Physical Realism, Condition-Video Alignment, and Temporal Consistency. Depart from that, participants also need to localize physical anomaly timestamps for fine-grained diagnosis. The benchmark dataset contains 1,554 videos generated by seven representative world generative models, organized into three tracks (text-2D, image-to-4D, and video-to-4D) and spanning 26 categories. These categories explicitly cover physics-relevant scenarios, including dynamics, optics, and thermodynamics, together with diverse real-world and creative content. To ensure label reliability, scores and anomaly timestamps are produced through trained human annotation with an additional automated quality-control pass. Evaluation is based on both score prediction and anomaly localization, with a composite protocol that combines TimeStamp_IOU and SRCC/PLCC. This report summarizes the challenge design and provides method-level insights from submitted solutions.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies
Jun 17, 2025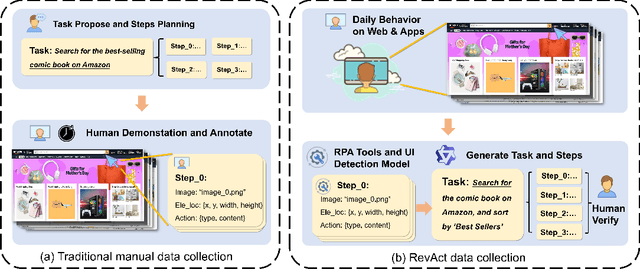
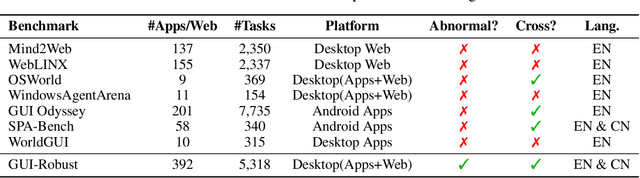

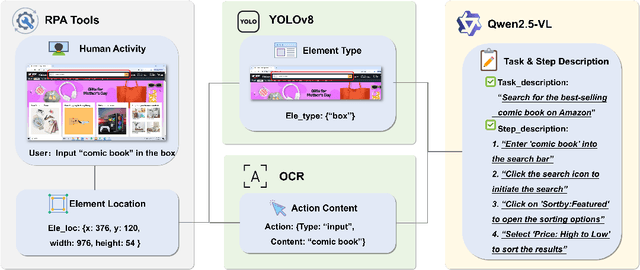
The development of high-quality datasets is crucial for benchmarking and advancing research in Graphical User Interface (GUI) agents. Despite their importance, existing datasets are often constructed under idealized conditions, overlooking the diverse anomalies frequently encountered in real-world deployments. To address this limitation, we introduce GUI-Robust, a novel dataset designed for comprehensive GUI agent evaluation, explicitly incorporating seven common types of anomalies observed in everyday GUI interactions. Furthermore, we propose a semi-automated dataset construction paradigm that collects user action sequences from natural interactions via RPA tools and then generate corresponding step and task descriptions for these actions with the assistance of MLLMs. This paradigm significantly reduces annotation time cost by a factor of over 19 times. Finally, we assess state-of-the-art GUI agents using the GUI-Robust dataset, revealing their substantial performance degradation in abnormal scenarios. We anticipate that our work will highlight the importance of robustness in GUI agents and inspires more future research in this direction. The dataset and code are available at https://github.com/chessbean1/GUI-Robust..