 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurstormer: Burst Image Restoration and Enhancement Transformer
Apr 03, 2023



On a shutter press, modern handheld cameras capture multiple images in rapid succession and merge them to generate a single image. However, individual frames in a burst are misaligned due to inevitable motions and contain multiple degradations. The challenge is to properly align the successive image shots and merge their complimentary information to achieve high-quality outputs. Towards this direction, we propose Burstormer: a novel transformer-based architecture for burst image restoration and enhancement. In comparison to existing works, our approach exploits multi-scale local and non-local features to achieve improved alignment and feature fusion. Our key idea is to enable inter-frame communication in the burst neighborhoods for information aggregation and progressive fusion while modeling the burst-wide context. However, the input burst frames need to be properly aligned before fusing their information. Therefore, we propose an enhanced deformable alignment module for aligning burst features with regards to the reference frame. Unlike existing methods, the proposed alignment module not only aligns burst features but also exchanges feature information and maintains focused communication with the reference frame through the proposed reference-based feature enrichment mechanism, which facilitates handling complex motions. After multi-level alignment and enrichment, we re-emphasize on inter-frame communication within burst using a cyclic burst sampling module. Finally, the inter-frame information is aggregated using the proposed burst feature fusion module followed by progressive upsampling. Our Burstormer outperforms state-of-the-art methods on burst super-resolution, burst denoising and burst low-light enhancement. Our codes and pretrained models are available at https:// github.com/akshaydudhane16/Burstormer
Spatiotemporally Discriminative Video-Language Pre-Training with Text Grounding
Mar 28, 2023



Most of existing video-language pre-training methods focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. In this work, we propose a simple yet effective video-language pre-training framework, namely G-ViLM, to learn discriminative spatiotemporal features. Two novel designs involving spatiotemporal grounding and temporal grouping promote learning local region-noun alignment and temporal-aware features simultaneously. Specifically, spatiotemporal grounding aggregates semantically similar video tokens and aligns them with noun phrases extracted from the caption to promote local region-noun correspondences. Moreover, temporal grouping leverages cut-and-paste to manually create temporal scene changes and then learns distinguishable features from different scenes. Comprehensive evaluations demonstrate that G-ViLM performs favorably against existing approaches on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition and temporal action localization. G-ViLM performs competitively on all evaluated tasks and in particular achieves R@10 of 65.1 on zero-shot MSR-VTT retrieval, over 9% higher than the state-of-the-art method.
SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications
Mar 27, 2023



Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2. Code: https://github.com/Amshaker/SwiftFormer
Unified Visual Relationship Detection with Vision and Language Models
Mar 16, 2023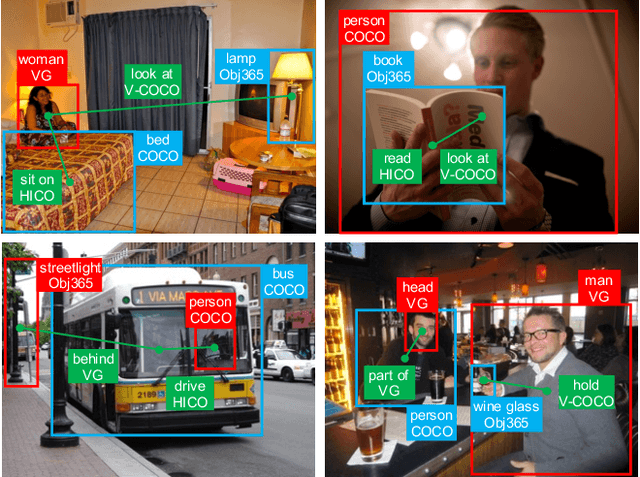
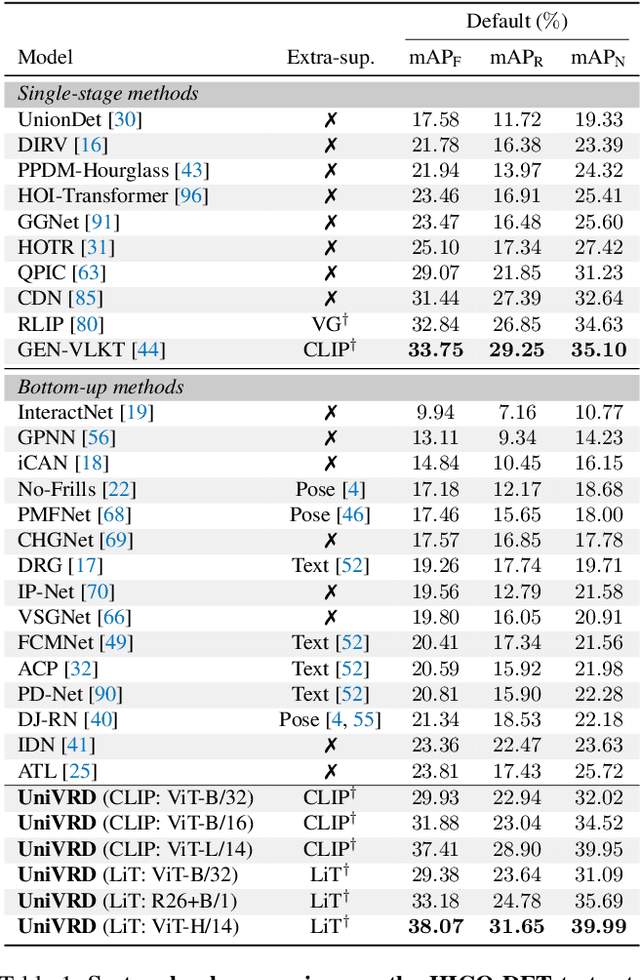
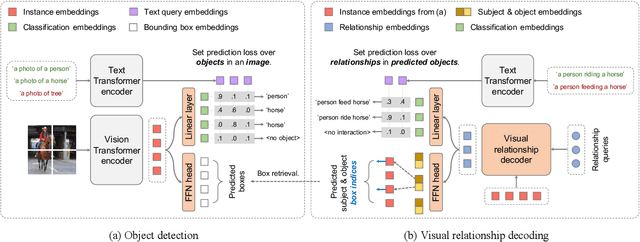
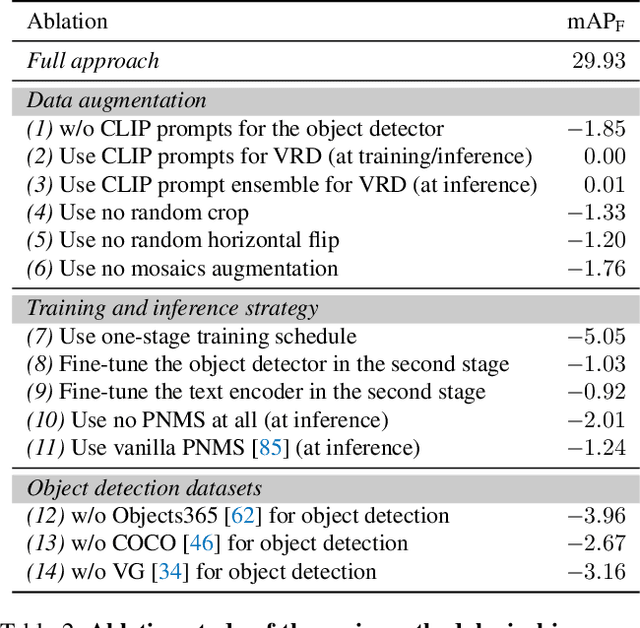
This work focuses on training a single visual relationship detector predicting over the union of label spaces from multiple datasets. Merging labels spanning different datasets could be challenging due to inconsistent taxonomies. The issue is exacerbated in visual relationship detection when second-order visual semantics are introduced between pairs of objects. To address this challenge, we propose UniVRD, a novel bottom-up method for Unified Visual Relationship Detection by leveraging vision and language models (VLMs). VLMs provide well-aligned image and text embeddings, where similar relationships are optimized to be close to each other for semantic unification. Our bottom-up design enables the model to enjoy the benefit of training with both object detection and visual relationship datasets. Empirical results on both human-object interaction detection and scene-graph generation demonstrate the competitive performance of our model. UniVRD achieves 38.07 mAP on HICO-DET, outperforming the current best bottom-up HOI detector by 60% relatively. More importantly, we show that our unified detector performs as well as dataset-specific models in mAP, and achieves further improvements when we scale up the model.
InfiniCity: Infinite-Scale City Synthesis
Jan 23, 2023Toward infinite-scale 3D city synthesis, we propose a novel framework, InfiniCity, which constructs and renders an unconstrainedly large and 3D-grounded environment from random noises. InfiniCity decomposes the seemingly impractical task into three feasible modules, taking advantage of both 2D and 3D data. First, an infinite-pixel image synthesis module generates arbitrary-scale 2D maps from the bird's-eye view. Next, an octree-based voxel completion module lifts the generated 2D map to 3D octrees. Finally, a voxel-based neural rendering module texturizes the voxels and renders 2D images. InfiniCity can thus synthesize arbitrary-scale and traversable 3D city environments, and allow flexible and interactive editing from users. We quantitatively and qualitatively demonstrate the efficacy of the proposed framework. Project page: https://hubert0527.github.io/infinicity/
Muse: Text-To-Image Generation via Masked Generative Transformers
Jan 02, 2023



We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at https://muse-model.github.io
Hi-LASSIE: High-Fidelity Articulated Shape and Skeleton Discovery from Sparse Image Ensemble
Dec 28, 2022



Automatically estimating 3D skeleton, shape, camera viewpoints, and part articulation from sparse in-the-wild image ensembles is a severely under-constrained and challenging problem. Most prior methods rely on large-scale image datasets, dense temporal correspondence, or human annotations like camera pose, 2D keypoints, and shape templates. We propose Hi-LASSIE, which performs 3D articulated reconstruction from only 20-30 online images in the wild without any user-defined shape or skeleton templates. We follow the recent work of LASSIE that tackles a similar problem setting and make two significant advances. First, instead of relying on a manually annotated 3D skeleton, we automatically estimate a class-specific skeleton from the selected reference image. Second, we improve the shape reconstructions with novel instance-specific optimization strategies that allow reconstructions to faithful fit on each instance while preserving the class-specific priors learned across all images. Experiments on in-the-wild image ensembles show that Hi-LASSIE obtains higher fidelity state-of-the-art 3D reconstructions despite requiring minimum user input.
Beyond SOT: It's Time to Track Multiple Generic Objects at Once
Dec 22, 2022



Generic Object Tracking (GOT) is the problem of tracking target objects, specified by bounding boxes in the first frame of a video. While the task has received much attention in the last decades, researchers have almost exclusively focused on the single object setting. Multi-object GOT benefits from a wider applicability, rendering it more attractive in real-world applications. We attribute the lack of research interest into this problem to the absence of suitable benchmarks. In this work, we introduce a new large-scale GOT benchmark, LaGOT, containing multiple annotated target objects per sequence. Our benchmark allows researchers to tackle key remaining challenges in GOT, aiming to increase robustness and reduce computation through joint tracking of multiple objects simultaneously. Furthermore, we propose a Transformer-based GOT tracker TaMOS capable of joint processing of multiple objects through shared computation. TaMOs achieves a 4x faster run-time in case of 10 concurrent objects compared to tracking each object independently and outperforms existing single object trackers on our new benchmark. Finally, TaMOs achieves highly competitive results on single-object GOT datasets, setting a new state-of-the-art on TrackingNet with a success rate AUC of 84.4%. Our benchmark, code, and trained models will be made publicly available.
Learning Object-level Point Augmentor for Semi-supervised 3D Object Detection
Dec 19, 2022



Semi-supervised object detection is important for 3D scene understanding because obtaining large-scale 3D bounding box annotations on point clouds is time-consuming and labor-intensive. Existing semi-supervised methods usually employ teacher-student knowledge distillation together with an augmentation strategy to leverage unlabeled point clouds. However, these methods adopt global augmentation with scene-level transformations and hence are sub-optimal for instance-level object detection. In this work, we propose an object-level point augmentor (OPA) that performs local transformations for semi-supervised 3D object detection. In this way, the resultant augmentor is derived to emphasize object instances rather than irrelevant backgrounds, making the augmented data more useful for object detector training. Extensive experiments on the ScanNet and SUN RGB-D datasets show that the proposed OPA performs favorably against the state-of-the-art methods under various experimental settings. The source code will be available at https://github.com/nomiaro/OPA.
MAGVIT: Masked Generative Video Transformer
Dec 10, 2022



We introduce the MAsked Generative VIdeo Transformer, MAGVIT, to tackle various video synthesis tasks with a single model. We introduce a 3D tokenizer to quantize a video into spatial-temporal visual tokens and propose an embedding method for masked video token modeling to facilitate multi-task learning. We conduct extensive experiments to demonstrate the quality, efficiency, and flexibility of MAGVIT. Our experiments show that (i) MAGVIT performs favorably against state-of-the-art approaches and establishes the best-published FVD on three video generation benchmarks, including the challenging Kinetics-600. (ii) MAGVIT outperforms existing methods in inference time by two orders of magnitude against diffusion models and by 60x against autoregressive models. (iii) A single MAGVIT model supports ten diverse generation tasks and generalizes across videos from different visual domains. The source code and trained models will be released to the public at https://magvit.cs.cmu.edu.