 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Semantic Segmentation Meets SAM3
Apr 07, 2026Few-Shot Semantic Segmentation (FSS) focuses on segmenting novel object categories from only a handful of annotated examples. Most existing approaches rely on extensive episodic training to learn transferable representations, which is both computationally demanding and sensitive to distribution shifts. In this work, we revisit FSS from the perspective of modern vision foundation models and explore the potential of Segment Anything Model 3 (SAM3) as a training-free solution. By repurposing its Promptable Concept Segmentation (PCS) capability, we adopt a simple spatial concatenation strategy that places support and query images into a shared canvas, allowing a fully frozen SAM3 to perform segmentation without any fine-tuning or architectural changes. Experiments on PASCAL-$5^i$ and COCO-$20^i$ show that this minimal design already achieves state-of-the-art performance, outperforming many heavily engineered methods. Beyond empirical gains, we uncover that negative prompts can be counterproductive in few-shot settings, where they often weaken target representations and lead to prediction collapse despite their intended role in suppressing distractors. These findings suggest that strong cross-image reasoning can emerge from simple spatial formulations, while also highlighting limitations in how current foundation models handle conflicting prompt signals. Code at: https://github.com/WongKinYiu/FSS-SAM3
HDR Reconstruction Boosting with Training-Free and Exposure-Consistent Diffusion
Feb 23, 2026Single LDR to HDR reconstruction remains challenging for over-exposed regions where traditional methods often fail due to complete information loss. We present a training-free approach that enhances existing indirect and direct HDR reconstruction methods through diffusion-based inpainting. Our method combines text-guided diffusion models with SDEdit refinement to generate plausible content in over-exposed areas while maintaining consistency across multi-exposure LDR images. Unlike previous approaches requiring extensive training, our method seamlessly integrates with existing HDR reconstruction techniques through an iterative compensation mechanism that ensures luminance coherence across multiple exposures. We demonstrate significant improvements in both perceptual quality and quantitative metrics on standard HDR datasets and in-the-wild captures. Results show that our method effectively recovers natural details in challenging scenarios while preserving the advantages of existing HDR reconstruction pipelines. Project page: https://github.com/EusdenLin/HDR-Reconstruction-Boosting
GOT-JEPA: Generic Object Tracking with Model Adaptation and Occlusion Handling using Joint-Embedding Predictive Architecture
Feb 16, 2026The human visual system tracks objects by integrating current observations with previously observed information, adapting to target and scene changes, and reasoning about occlusion at fine granularity. In contrast, recent generic object trackers are often optimized for training targets, which limits robustness and generalization in unseen scenarios, and their occlusion reasoning remains coarse, lacking detailed modeling of occlusion patterns. To address these limitations in generalization and occlusion perception, we propose GOT-JEPA, a model-predictive pretraining framework that extends JEPA from predicting image features to predicting tracking models. Given identical historical information, a teacher predictor generates pseudo-tracking models from a clean current frame, and a student predictor learns to predict the same pseudo-tracking models from a corrupted version of the current frame. This design provides stable pseudo supervision and explicitly trains the predictor to produce reliable tracking models under occlusions, distractors, and other adverse observations, improving generalization to dynamic environments. Building on GOT-JEPA, we further propose OccuSolver to enhance occlusion perception for object tracking. OccuSolver adapts a point-centric point tracker for object-aware visibility estimation and detailed occlusion-pattern capture. Conditioned on object priors iteratively generated by the tracker, OccuSolver incrementally refines visibility states, strengthens occlusion handling, and produces higher-quality reference labels that progressively improve subsequent model predictions. Extensive evaluations on seven benchmarks show that our method effectively enhances tracker generalization and robustness.
GOT-Edit: Geometry-Aware Generic Object Tracking via Online Model Editing
Feb 09, 2026Human perception for effective object tracking in a 2D video stream arises from the implicit use of prior 3D knowledge combined with semantic reasoning. In contrast, most generic object tracking (GOT) methods primarily rely on 2D features of the target and its surroundings while neglecting 3D geometric cues, which makes them susceptible to partial occlusion, distractors, and variations in geometry and appearance. To address this limitation, we introduce GOT-Edit, an online cross-modality model editing approach that integrates geometry-aware cues into a generic object tracker from a 2D video stream. Our approach leverages features from a pre-trained Visual Geometry Grounded Transformer to enable geometric cue inference from only a few 2D images. To tackle the challenge of seamlessly combining geometry and semantics, GOT-Edit performs online model editing with null-space constrained updates that incorporate geometric information while preserving semantic discrimination, yielding consistently better performance across diverse scenarios. Extensive experiments on multiple GOT benchmarks demonstrate that GOT-Edit achieves superior robustness and accuracy, particularly under occlusion and clutter, establishing a new paradigm for combining 2D semantics with 3D geometric reasoning for generic object tracking.
CSGaussian: Progressive Rate-Distortion Compression and Segmentation for 3D Gaussian Splatting
Jan 19, 2026We present the first unified framework for rate-distortion-optimized compression and segmentation of 3D Gaussian Splatting (3DGS). While 3DGS has proven effective for both real-time rendering and semantic scene understanding, prior works have largely treated these tasks independently, leaving their joint consideration unexplored. Inspired by recent advances in rate-distortion-optimized 3DGS compression, this work integrates semantic learning into the compression pipeline to support decoder-side applications--such as scene editing and manipulation--that extend beyond traditional scene reconstruction and view synthesis. Our scheme features a lightweight implicit neural representation-based hyperprior, enabling efficient entropy coding of both color and semantic attributes while avoiding costly grid-based hyperprior as seen in many prior works. To facilitate compression and segmentation, we further develop compression-guided segmentation learning, consisting of quantization-aware training to enhance feature separability and a quality-aware weighting mechanism to suppress unreliable Gaussian primitives. Extensive experiments on the LERF and 3D-OVS datasets demonstrate that our approach significantly reduces transmission cost while preserving high rendering quality and strong segmentation performance.
3AM: 3egment Anything with Geometric Consistency in Videos
Jan 18, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
3AM: Segment Anything with Geometric Consistency in Videos
Jan 13, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos
Aug 19, 2025



LongSplat addresses critical challenges in novel view synthesis (NVS) from casually captured long videos characterized by irregular camera motion, unknown camera poses, and expansive scenes. Current methods often suffer from pose drift, inaccurate geometry initialization, and severe memory limitations. To address these issues, we introduce LongSplat, a robust unposed 3D Gaussian Splatting framework featuring: (1) Incremental Joint Optimization that concurrently optimizes camera poses and 3D Gaussians to avoid local minima and ensure global consistency; (2) a robust Pose Estimation Module leveraging learned 3D priors; and (3) an efficient Octree Anchor Formation mechanism that converts dense point clouds into anchors based on spatial density. Extensive experiments on challenging benchmarks demonstrate that LongSplat achieves state-of-the-art results, substantially improving rendering quality, pose accuracy, and computational efficiency compared to prior approaches. Project page: https://linjohnss.github.io/longsplat/
AuraFusion360: Augmented Unseen Region Alignment for Reference-based 360° Unbounded Scene Inpainting
Feb 07, 2025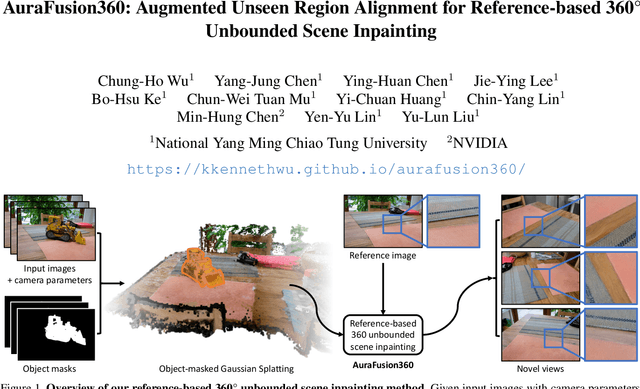
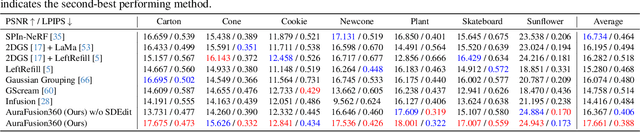

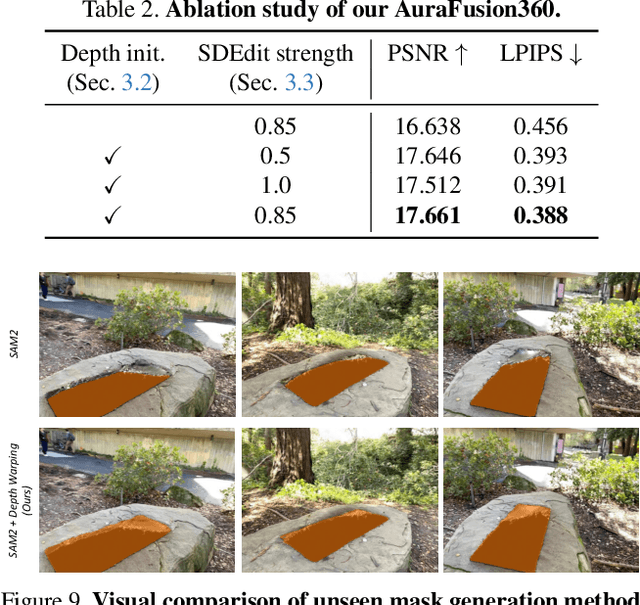
Three-dimensional scene inpainting is crucial for applications from virtual reality to architectural visualization, yet existing methods struggle with view consistency and geometric accuracy in 360{\deg} unbounded scenes. We present AuraFusion360, a novel reference-based method that enables high-quality object removal and hole filling in 3D scenes represented by Gaussian Splatting. Our approach introduces (1) depth-aware unseen mask generation for accurate occlusion identification, (2) Adaptive Guided Depth Diffusion, a zero-shot method for accurate initial point placement without requiring additional training, and (3) SDEdit-based detail enhancement for multi-view coherence. We also introduce 360-USID, the first comprehensive dataset for 360{\deg} unbounded scene inpainting with ground truth. Extensive experiments demonstrate that AuraFusion360 significantly outperforms existing methods, achieving superior perceptual quality while maintaining geometric accuracy across dramatic viewpoint changes. See our project page for video results and the dataset at https://kkennethwu.github.io/aurafusion360/.
CorrFill: Enhancing Faithfulness in Reference-based Inpainting with Correspondence Guidance in Diffusion Models
Jan 04, 2025


In the task of reference-based image inpainting, an additional reference image is provided to restore a damaged target image to its original state. The advancement of diffusion models, particularly Stable Diffusion, allows for simple formulations in this task. However, existing diffusion-based methods often lack explicit constraints on the correlation between the reference and damaged images, resulting in lower faithfulness to the reference images in the inpainting results. In this work, we propose CorrFill, a training-free module designed to enhance the awareness of geometric correlations between the reference and target images. This enhancement is achieved by guiding the inpainting process with correspondence constraints estimated during inpainting, utilizing attention masking in self-attention layers and an objective function to update the input tensor according to the constraints. Experimental results demonstrate that CorrFill significantly enhances the performance of multiple baseline diffusion-based methods, including state-of-the-art approaches, by emphasizing faithfulness to the reference images.