 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Question Answering by Commonsense-Based Pre-Training
Oct 05, 2018
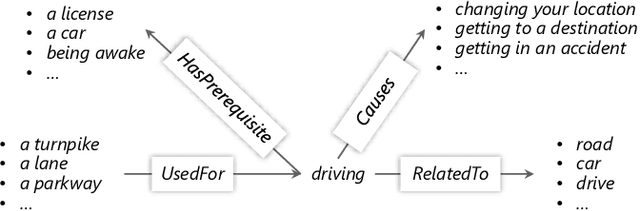
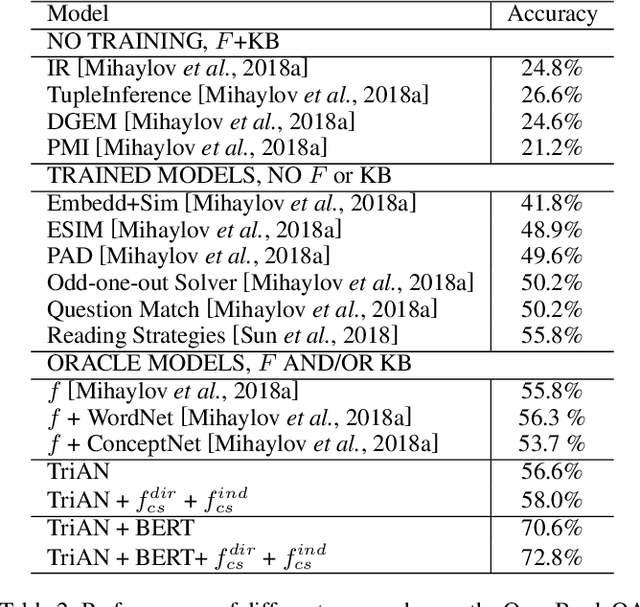
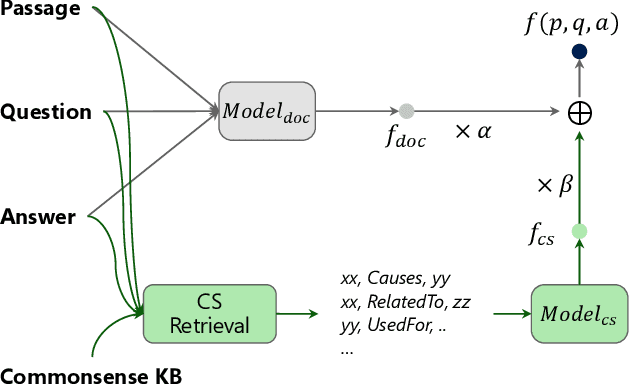
Although neural network approaches achieve remarkable success on a variety of NLP tasks, many of them struggle to answer questions that require commonsense knowledge. We believe the main reason is the lack of commonsense connections between concepts. To remedy this, we provide a simple and effective method that leverages external commonsense knowledge base such as ConceptNet. We pre-train direct and indirect relational functions between concepts, and show that these pre-trained functions could be easily added to existing neural network models. Results show that incorporating commonsense-based function improves the state-of-the-art on two question answering tasks that require commonsense reasoning. Further analysis shows that our system discovers and leverages useful evidences from an external commonsense knowledge base, which is missing in existing neural network models and help derive the correct answer.
Text Morphing
Sep 30, 2018
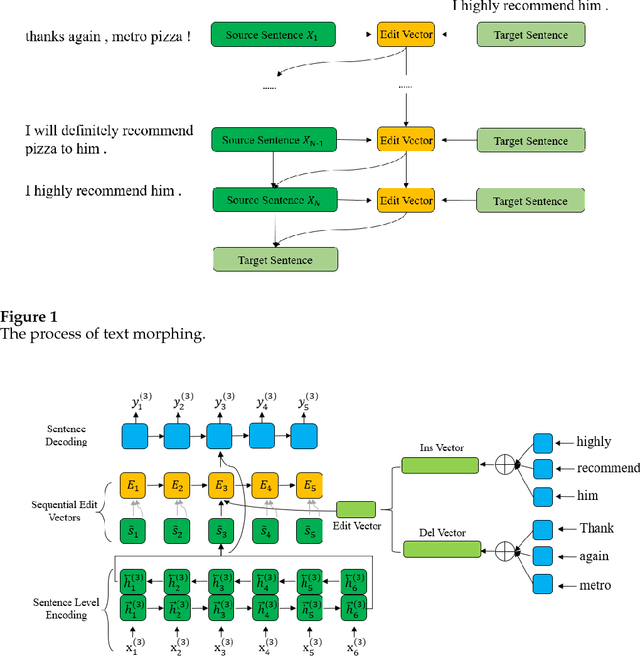
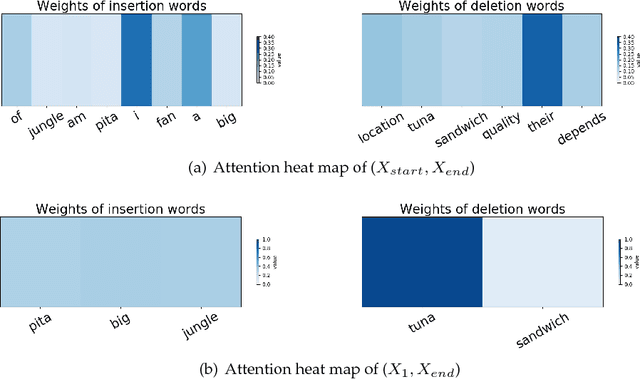

In this paper, we introduce a novel natural language generation task, termed as text morphing, which targets at generating the intermediate sentences that are fluency and smooth with the two input sentences. We propose the Morphing Networks consisting of the editing vector generation networks and the sentence editing networks which are trained jointly. Specifically, the editing vectors are generated with a recurrent neural networks model from the lexical gap between the source sentence and the target sentence. Then the sentence editing networks iteratively generate new sentences with the current editing vector and the sentence generated in the previous step. We conduct experiments with 10 million text morphing sequences which are extracted from the Yelp review dataset. Experiment results show that the proposed method outperforms baselines on the text morphing task. We also discuss directions and opportunities for future research of text morphing.
Close to Human Quality TTS with Transformer
Sep 19, 2018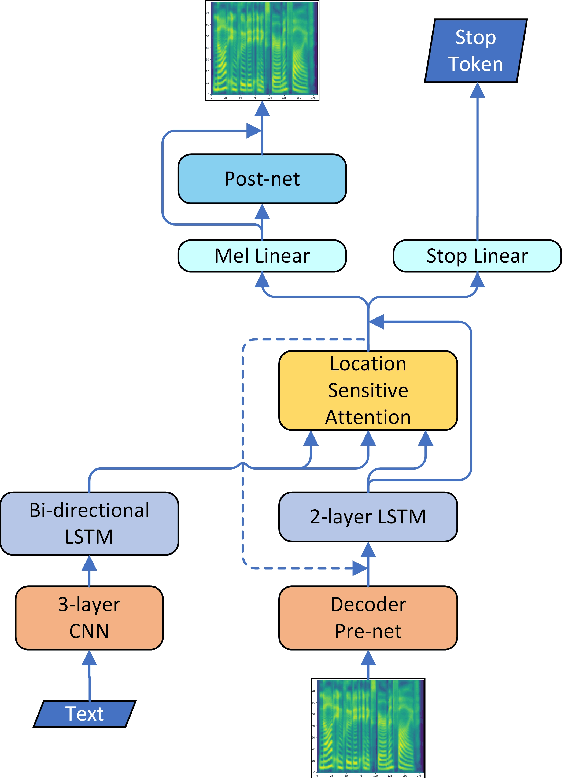
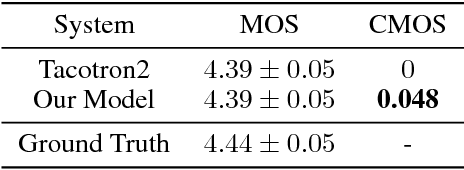
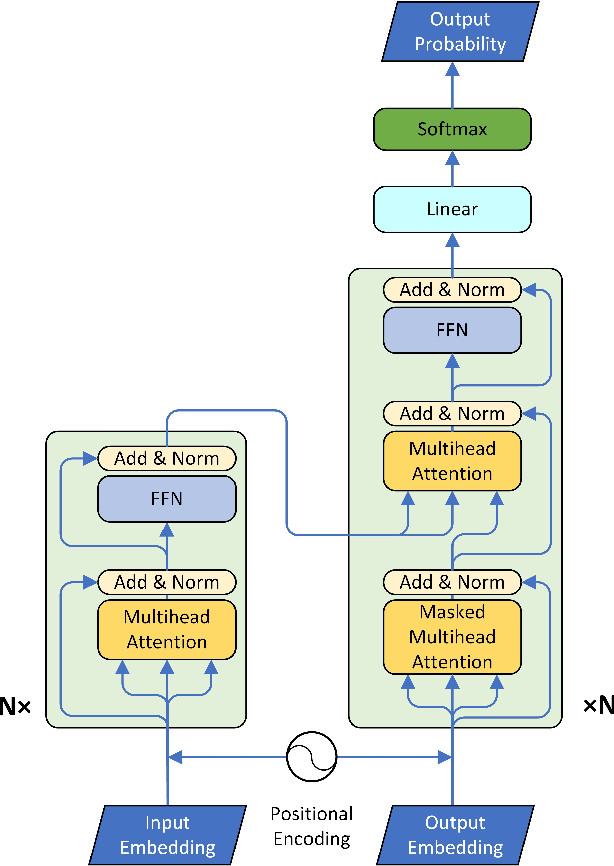
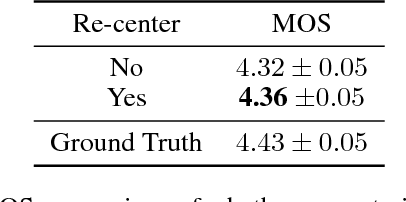
Although end-to-end neural text-to-speech (TTS) methods (such as Tacotron2) are proposed and achieve state-of-the-art performance, they still suffer from two problems: 1) low efficiency during training and inference; 2) hard to model long dependency using current recurrent neural networks (RNNs). Inspired by the success of Transformer network in neural machine translation (NMT), in this paper, we introduce and adapt the multi-head attention mechanism to replace the RNN structures and also the original attention mechanism in Tacotron2. With the help of multi-head self-attention, the hidden states in the encoder and decoder are constructed in parallel, which improves training efficiency. Meanwhile, any two inputs at different times are connected directly by a self-attention mechanism, which solves the long range dependency problem effectively. Using phoneme sequences as input, our Transformer TTS network generates mel spectrograms, followed by a WaveNet vocoder to output the final audio results. Experiments are conducted to test the efficiency and performance of our new network. For the efficiency, our Transformer TTS network can speed up the training about 4.25 times faster compared with Tacotron2. For the performance, rigorous human tests show that our proposed model achieves state-of-the-art performance (outperforms Tacotron2 with a gap of 0.048) and is very close to human quality (4.39 vs 4.44 in MOS).
Attention-Guided Answer Distillation for Machine Reading Comprehension
Sep 17, 2018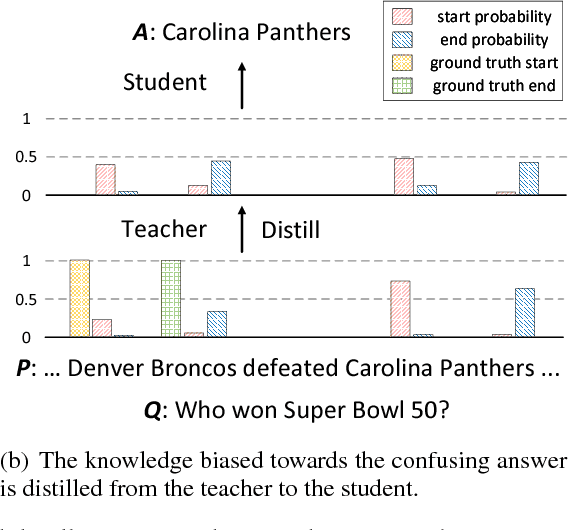
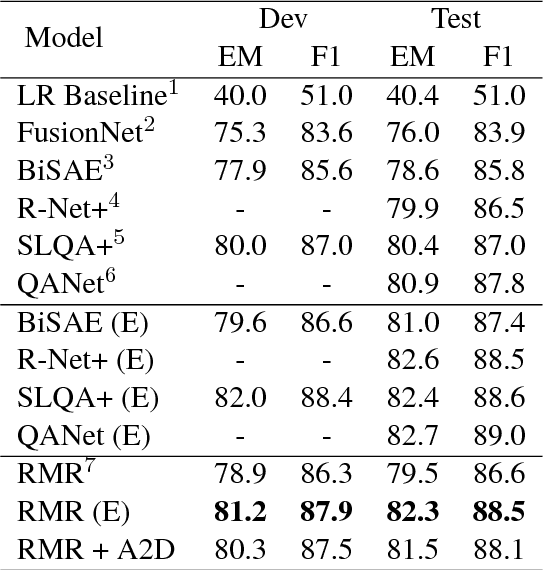
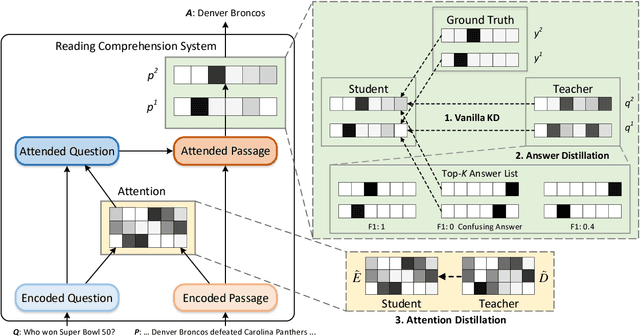
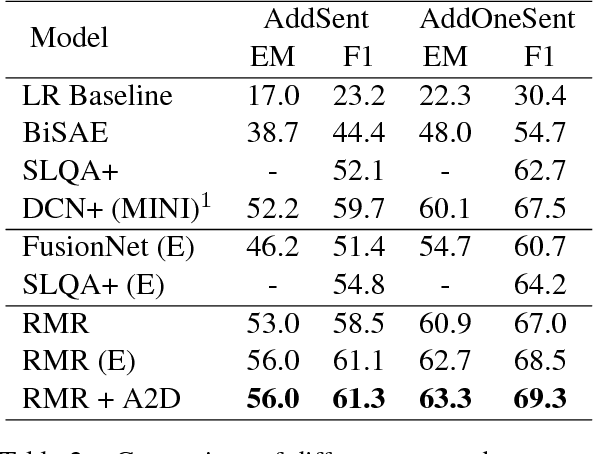
Despite that current reading comprehension systems have achieved significant advancements, their promising performances are often obtained at the cost of making an ensemble of numerous models. Besides, existing approaches are also vulnerable to adversarial attacks. This paper tackles these problems by leveraging knowledge distillation, which aims to transfer knowledge from an ensemble model to a single model. We first demonstrate that vanilla knowledge distillation applied to answer span prediction is effective for reading comprehension systems. We then propose two novel approaches that not only penalize the prediction on confusing answers but also guide the training with alignment information distilled from the ensemble. Experiments show that our best student model has only a slight drop of 0.4% F1 on the SQuAD test set compared to the ensemble teacher, while running 12x faster during inference. It even outperforms the teacher on adversarial SQuAD datasets and NarrativeQA benchmark.
Neural Melody Composition from Lyrics
Sep 12, 2018



In this paper, we study a novel task that learns to compose music from natural language. Given the lyrics as input, we propose a melody composition model that generates lyrics-conditional melody as well as the exact alignment between the generated melody and the given lyrics simultaneously. More specifically, we develop the melody composition model based on the sequence-to-sequence framework. It consists of two neural encoders to encode the current lyrics and the context melody respectively, and a hierarchical decoder to jointly produce musical notes and the corresponding alignment. Experimental results on lyrics-melody pairs of 18,451 pop songs demonstrate the effectiveness of our proposed methods. In addition, we apply a singing voice synthesizer software to synthesize the "singing" of the lyrics and melodies for human evaluation. Results indicate that our generated melodies are more melodious and tuneful compared with the baseline method.
Read + Verify: Machine Reading Comprehension with Unanswerable Questions
Sep 05, 2018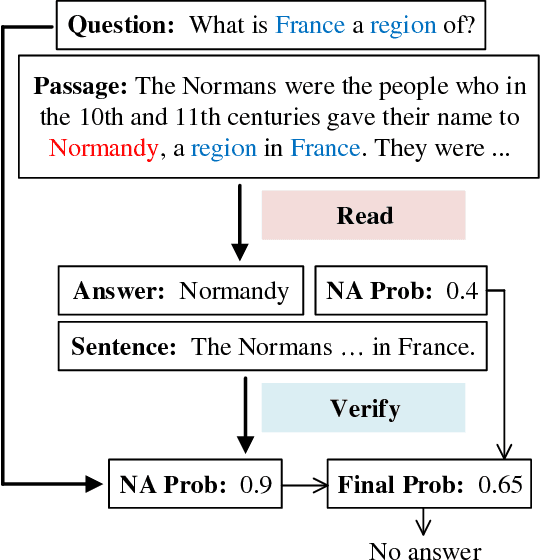
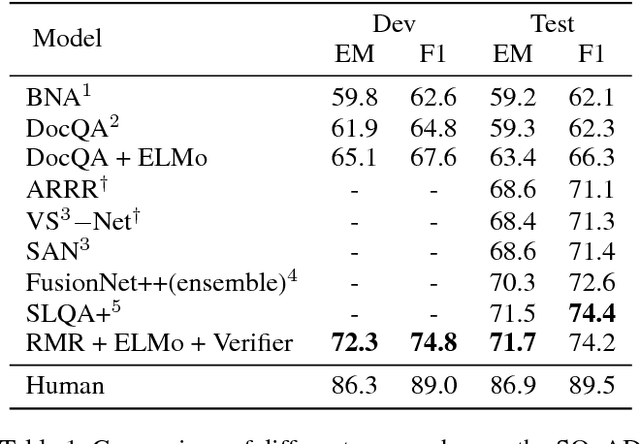
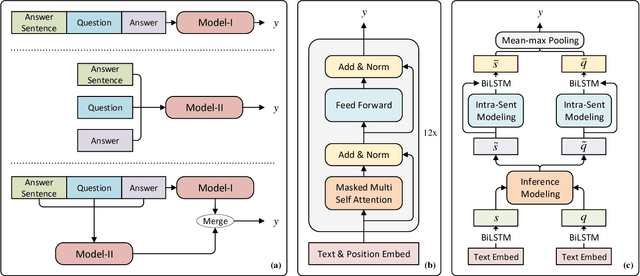
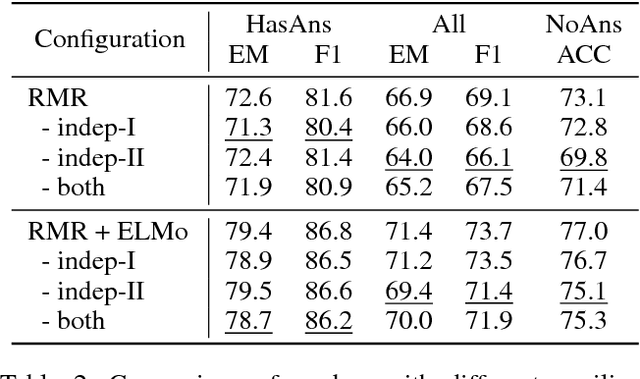
Machine reading comprehension with unanswerable questions aims to abstain from answering when no answer can be inferred. In addition to extract answers, previous works usually predict an additional "no-answer" probability to detect unanswerable cases. However, they fail to validate the answerability of the question by verifying the legitimacy of the predicted answer. To address this problem, we propose a novel read-then-verify system, which not only utilizes a neural reader to extract candidate answers and produce no-answer probabilities, but also leverages an answer verifier to decide whether the predicted answer is entailed by the input snippets. Moreover, we introduce two auxiliary losses to help the reader better handle answer extraction as well as no-answer detection, and investigate three different architectures for the answer verifier. Our experiments on the SQuAD 2.0 dataset show that our system achieves a score of 74.2 F1 on the test set, outperforming all previous approaches at the time of submission (Aug. 23th, 2018).
Approximate Distribution Matching for Sequence-to-Sequence Learning
Sep 02, 2018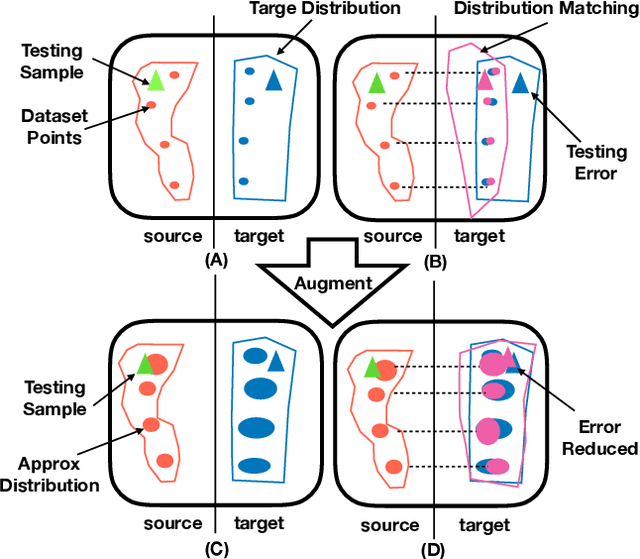
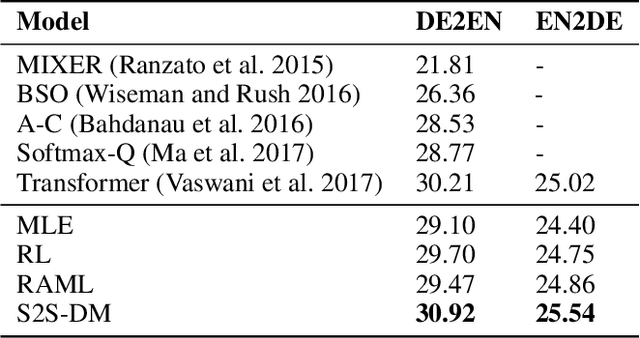
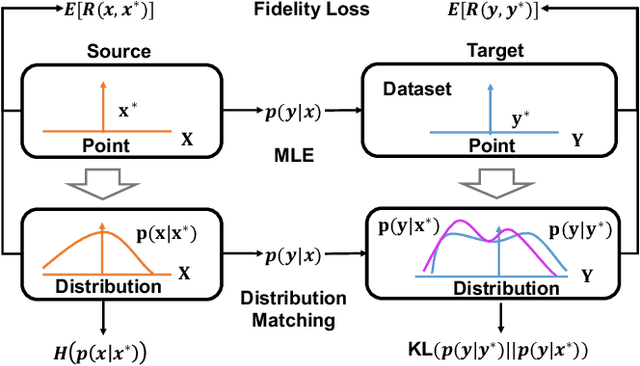
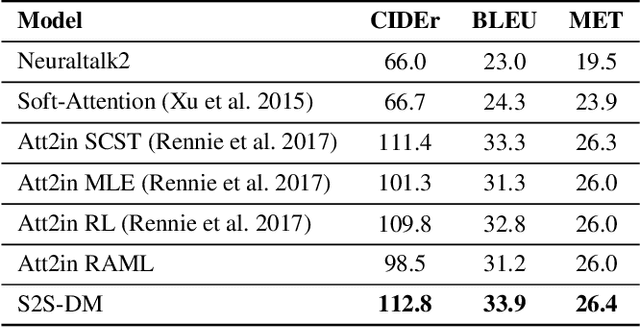
Sequence-to-Sequence models were introduced to tackle many real-life problems like machine translation, summarization, image captioning, etc. The standard optimization algorithms are mainly based on example-to-example matching like maximum likelihood estimation, which is known to suffer from data sparsity problem. Here we present an alternate view to explain sequence-to-sequence learning as a distribution matching problem, where each source or target example is viewed to represent a local latent distribution in the source or target domain. Then, we interpret sequence-to-sequence learning as learning a transductive model to transform the source local latent distributions to match their corresponding target distributions. In our framework, we approximate both the source and target latent distributions with recurrent neural networks (augmenter). During training, the parallel augmenters learn to better approximate the local latent distributions, while the sequence prediction model learns to minimize the KL-divergence of the transformed source distributions and the approximated target distributions. This algorithm can alleviate the data sparsity issues in sequence learning by locally augmenting more unseen data pairs and increasing the model's robustness. Experiments conducted on machine translation and image captioning consistently demonstrate the superiority of our proposed algorithm over the other competing algorithms.
Neural Latent Extractive Document Summarization
Aug 28, 2018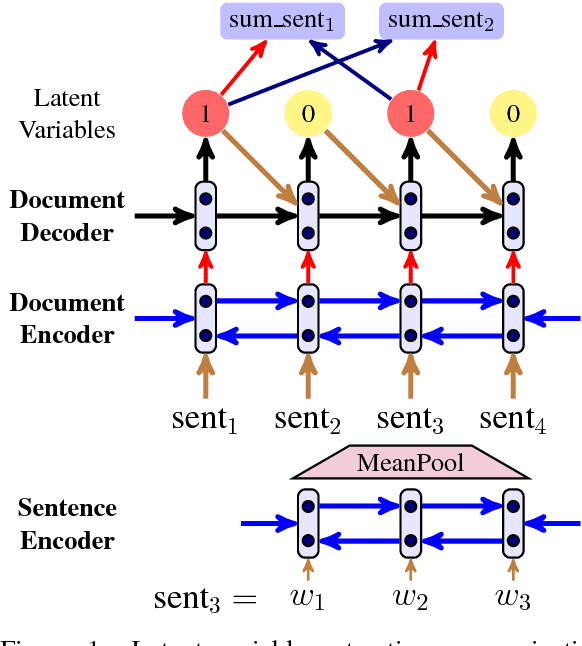
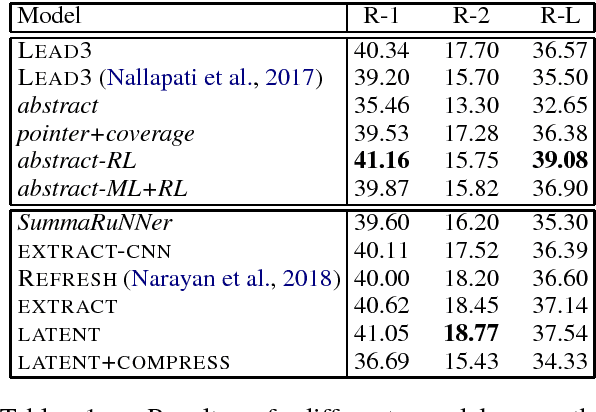
Extractive summarization models require sentence-level labels, which are usually created heuristically (e.g., with rule-based methods) given that most summarization datasets only have document-summary pairs. Since these labels might be suboptimal, we propose a latent variable extractive model where sentences are viewed as latent variables and sentences with activated variables are used to infer gold summaries. During training the loss comes \emph{directly} from gold summaries. Experiments on the CNN/Dailymail dataset show that our model improves over a strong extractive baseline trained on heuristically approximated labels and also performs competitively to several recent models.
Question Generation from SQL Queries Improves Neural Semantic Parsing
Aug 27, 2018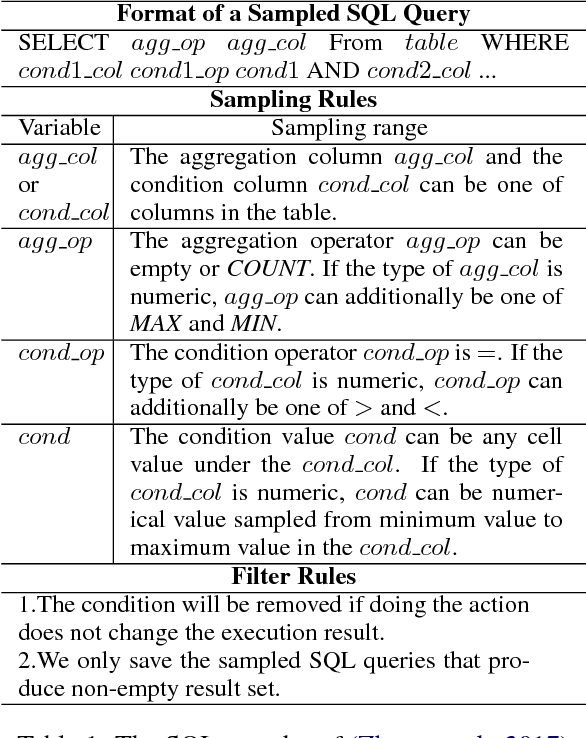
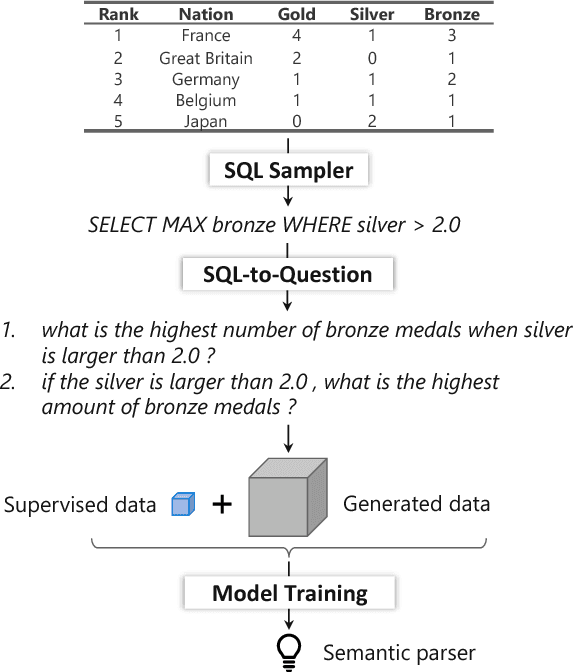
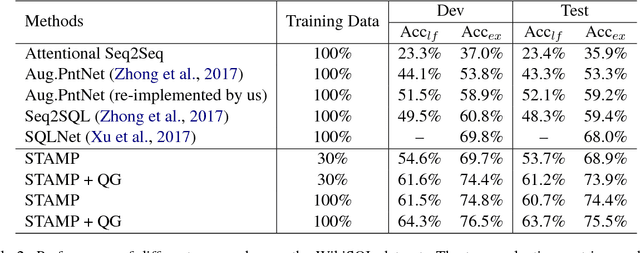
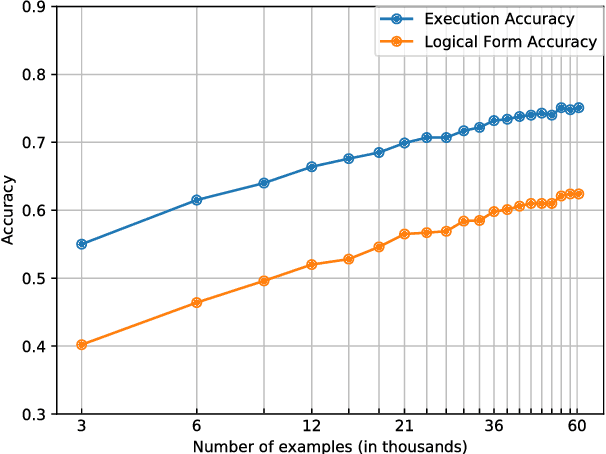
We study how to learn a semantic parser of state-of-the-art accuracy with less supervised training data. We conduct our study on WikiSQL, the largest hand-annotated semantic parsing dataset to date. First, we demonstrate that question generation is an effective method that empowers us to learn a state-of-the-art neural network based semantic parser with thirty percent of the supervised training data. Second, we show that applying question generation to the full supervised training data further improves the state-of-the-art model. In addition, we observe that there is a logarithmic relationship between the accuracy of a semantic parser and the amount of training data.
Style Transfer as Unsupervised Machine Translation
Aug 23, 2018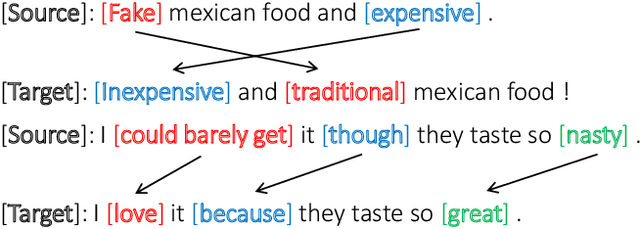
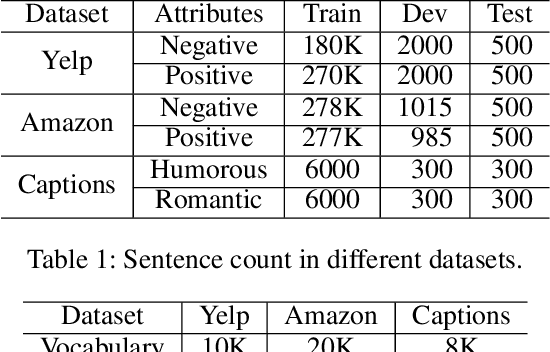
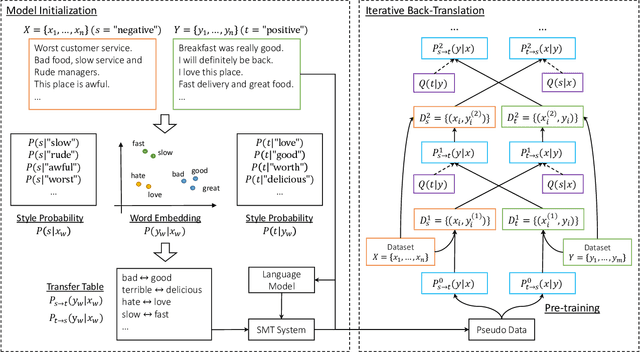
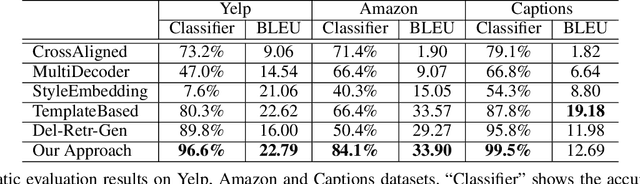
Language style transferring rephrases text with specific stylistic attributes while preserving the original attribute-independent content. One main challenge in learning a style transfer system is a lack of parallel data where the source sentence is in one style and the target sentence in another style. With this constraint, in this paper, we adapt unsupervised machine translation methods for the task of automatic style transfer. We first take advantage of style-preference information and word embedding similarity to produce pseudo-parallel data with a statistical machine translation (SMT) framework. Then the iterative back-translation approach is employed to jointly train two neural machine translation (NMT) based transfer systems. To control the noise generated during joint training, a style classifier is introduced to guarantee the accuracy of style transfer and penalize bad candidates in the generated pseudo data. Experiments on benchmark datasets show that our proposed method outperforms previous state-of-the-art models in terms of both accuracy of style transfer and quality of input-output correspondence.