 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionEngine: Diffusion Model is Scalable Data Engine for Object Detection
Sep 07, 2023



Data is the cornerstone of deep learning. This paper reveals that the recently developed Diffusion Model is a scalable data engine for object detection. Existing methods for scaling up detection-oriented data often require manual collection or generative models to obtain target images, followed by data augmentation and labeling to produce training pairs, which are costly, complex, or lacking diversity. To address these issues, we presentDiffusionEngine (DE), a data scaling-up engine that provides high-quality detection-oriented training pairs in a single stage. DE consists of a pre-trained diffusion model and an effective Detection-Adapter, contributing to generating scalable, diverse and generalizable detection data in a plug-and-play manner. Detection-Adapter is learned to align the implicit semantic and location knowledge in off-the-shelf diffusion models with detection-aware signals to make better bounding-box predictions. Additionally, we contribute two datasets, i.e., COCO-DE and VOC-DE, to scale up existing detection benchmarks for facilitating follow-up research. Extensive experiments demonstrate that data scaling-up via DE can achieve significant improvements in diverse scenarios, such as various detection algorithms, self-supervised pre-training, data-sparse, label-scarce, cross-domain, and semi-supervised learning. For example, when using DE with a DINO-based adapter to scale up data, mAP is improved by 3.1% on COCO, 7.6% on VOC, and 11.5% on Clipart.
DLIP: Distilling Language-Image Pre-training
Aug 24, 2023



Vision-Language Pre-training (VLP) shows remarkable progress with the assistance of extremely heavy parameters, which challenges deployment in real applications. Knowledge distillation is well recognized as the essential procedure in model compression. However, existing knowledge distillation techniques lack an in-depth investigation and analysis of VLP, and practical guidelines for VLP-oriented distillation are still not yet explored. In this paper, we present DLIP, a simple yet efficient Distilling Language-Image Pre-training framework, through which we investigate how to distill a light VLP model. Specifically, we dissect the model distillation from multiple dimensions, such as the architecture characteristics of different modules and the information transfer of different modalities. We conduct comprehensive experiments and provide insights on distilling a light but performant VLP model. Experimental results reveal that DLIP can achieve a state-of-the-art accuracy/efficiency trade-off across diverse cross-modal tasks, e.g., image-text retrieval, image captioning and visual question answering. For example, DLIP compresses BLIP by 1.9x, from 213M to 108M parameters, while achieving comparable or better performance. Furthermore, DLIP succeeds in retaining more than 95% of the performance with 22.4% parameters and 24.8% FLOPs compared to the teacher model and accelerates inference speed by 2.7x.
AvatarVerse: High-quality & Stable 3D Avatar Creation from Text and Pose
Aug 07, 2023



Creating expressive, diverse and high-quality 3D avatars from highly customized text descriptions and pose guidance is a challenging task, due to the intricacy of modeling and texturing in 3D that ensure details and various styles (realistic, fictional, etc). We present AvatarVerse, a stable pipeline for generating expressive high-quality 3D avatars from nothing but text descriptions and pose guidance. In specific, we introduce a 2D diffusion model conditioned on DensePose signal to establish 3D pose control of avatars through 2D images, which enhances view consistency from partially observed scenarios. It addresses the infamous Janus Problem and significantly stablizes the generation process. Moreover, we propose a progressive high-resolution 3D synthesis strategy, which obtains substantial improvement over the quality of the created 3D avatars. To this end, the proposed AvatarVerse pipeline achieves zero-shot 3D modeling of 3D avatars that are not only more expressive, but also in higher quality and fidelity than previous works. Rigorous qualitative evaluations and user studies showcase AvatarVerse's superiority in synthesizing high-fidelity 3D avatars, leading to a new standard in high-quality and stable 3D avatar creation. Our project page is: https://avatarverse3d.github.io
HandMIM: Pose-Aware Self-Supervised Learning for 3D Hand Mesh Estimation
Jul 29, 2023With an enormous number of hand images generated over time, unleashing pose knowledge from unlabeled images for supervised hand mesh estimation is an emerging yet challenging topic. To alleviate this issue, semi-supervised and self-supervised approaches have been proposed, but they are limited by the reliance on detection models or conventional ResNet backbones. In this paper, inspired by the rapid progress of Masked Image Modeling (MIM) in visual classification tasks, we propose a novel self-supervised pre-training strategy for regressing 3D hand mesh parameters. Our approach involves a unified and multi-granularity strategy that includes a pseudo keypoint alignment module in the teacher-student framework for learning pose-aware semantic class tokens. For patch tokens with detailed locality, we adopt a self-distillation manner between teacher and student network based on MIM pre-training. To better fit low-level regression tasks, we incorporate pixel reconstruction tasks for multi-level representation learning. Additionally, we design a strong pose estimation baseline using a simple vanilla vision Transformer (ViT) as the backbone and attach a PyMAF head after tokens for regression. Extensive experiments demonstrate that our proposed approach, named HandMIM, achieves strong performance on various hand mesh estimation tasks. Notably, HandMIM outperforms specially optimized architectures, achieving 6.29mm and 8.00mm PAVPE (Vertex-Point-Error) on challenging FreiHAND and HO3Dv2 test sets, respectively, establishing new state-of-the-art records on 3D hand mesh estimation.
AlignDet: Aligning Pre-training and Fine-tuning in Object Detection
Jul 20, 2023The paradigm of large-scale pre-training followed by downstream fine-tuning has been widely employed in various object detection algorithms. In this paper, we reveal discrepancies in data, model, and task between the pre-training and fine-tuning procedure in existing practices, which implicitly limit the detector's performance, generalization ability, and convergence speed. To this end, we propose AlignDet, a unified pre-training framework that can be adapted to various existing detectors to alleviate the discrepancies. AlignDet decouples the pre-training process into two stages, i.e., image-domain and box-domain pre-training. The image-domain pre-training optimizes the detection backbone to capture holistic visual abstraction, and box-domain pre-training learns instance-level semantics and task-aware concepts to initialize the parts out of the backbone. By incorporating the self-supervised pre-trained backbones, we can pre-train all modules for various detectors in an unsupervised paradigm. As depicted in Figure 1, extensive experiments demonstrate that AlignDet can achieve significant improvements across diverse protocols, such as detection algorithm, model backbone, data setting, and training schedule. For example, AlignDet improves FCOS by 5.3 mAP, RetinaNet by 2.1 mAP, Faster R-CNN by 3.3 mAP, and DETR by 2.3 mAP under fewer epochs.
SwiftAvatar: Efficient Auto-Creation of Parameterized Stylized Character on Arbitrary Avatar Engines
Jan 19, 2023The creation of a parameterized stylized character involves careful selection of numerous parameters, also known as the "avatar vectors" that can be interpreted by the avatar engine. Existing unsupervised avatar vector estimation methods that auto-create avatars for users, however, often fail to work because of the domain gap between realistic faces and stylized avatar images. To this end, we propose SwiftAvatar, a novel avatar auto-creation framework that is evidently superior to previous works. SwiftAvatar introduces dual-domain generators to create pairs of realistic faces and avatar images using shared latent codes. The latent codes can then be bridged with the avatar vectors as pairs, by performing GAN inversion on the avatar images rendered from the engine using avatar vectors. Through this way, we are able to synthesize paired data in high-quality as many as possible, consisting of avatar vectors and their corresponding realistic faces. We also propose semantic augmentation to improve the diversity of synthesis. Finally, a light-weight avatar vector estimator is trained on the synthetic pairs to implement efficient auto-creation. Our experiments demonstrate the effectiveness and efficiency of SwiftAvatar on two different avatar engines. The superiority and advantageous flexibility of SwiftAvatar are also verified in both subjective and objective evaluations.
Multi-Granularity Distillation Scheme Towards Lightweight Semi-Supervised Semantic Segmentation
Aug 22, 2022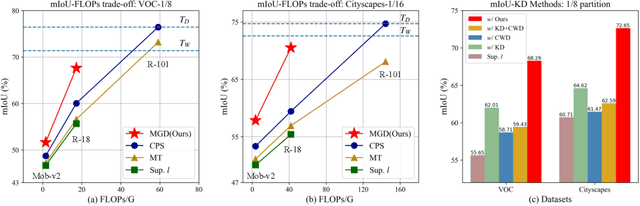
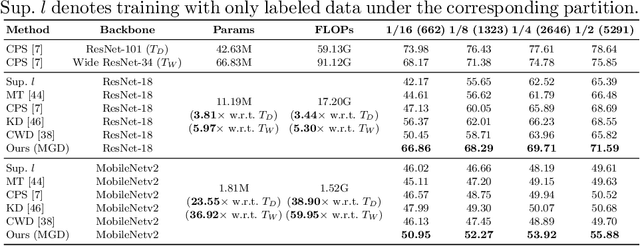
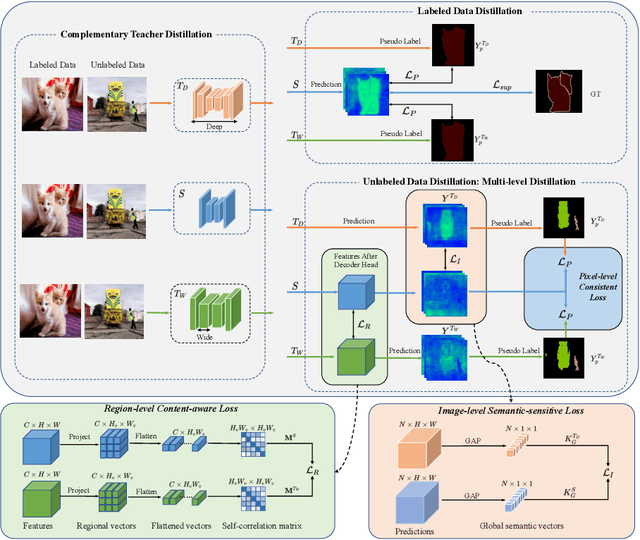
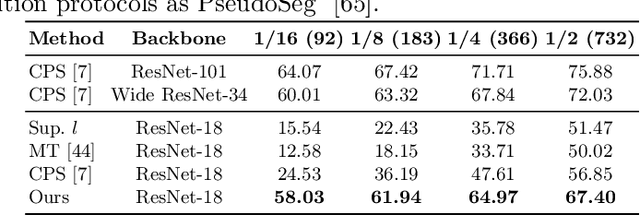
Albeit with varying degrees of progress in the field of Semi-Supervised Semantic Segmentation, most of its recent successes are involved in unwieldy models and the lightweight solution is still not yet explored. We find that existing knowledge distillation techniques pay more attention to pixel-level concepts from labeled data, which fails to take more informative cues within unlabeled data into account. Consequently, we offer the first attempt to provide lightweight SSSS models via a novel multi-granularity distillation (MGD) scheme, where multi-granularity is captured from three aspects: i) complementary teacher structure; ii) labeled-unlabeled data cooperative distillation; iii) hierarchical and multi-levels loss setting. Specifically, MGD is formulated as a labeled-unlabeled data cooperative distillation scheme, which helps to take full advantage of diverse data characteristics that are essential in the semi-supervised setting. Image-level semantic-sensitive loss, region-level content-aware loss, and pixel-level consistency loss are set up to enrich hierarchical distillation abstraction via structurally complementary teachers. Experimental results on PASCAL VOC2012 and Cityscapes reveal that MGD can outperform the competitive approaches by a large margin under diverse partition protocols. For example, the performance of ResNet-18 and MobileNet-v2 backbone is boosted by 11.5% and 4.6% respectively under 1/16 partition protocol on Cityscapes. Although the FLOPs of the model backbone is compressed by 3.4-5.3x (ResNet-18) and 38.7-59.6x (MobileNetv2), the model manages to achieve satisfactory segmentation results.
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
Jul 13, 2022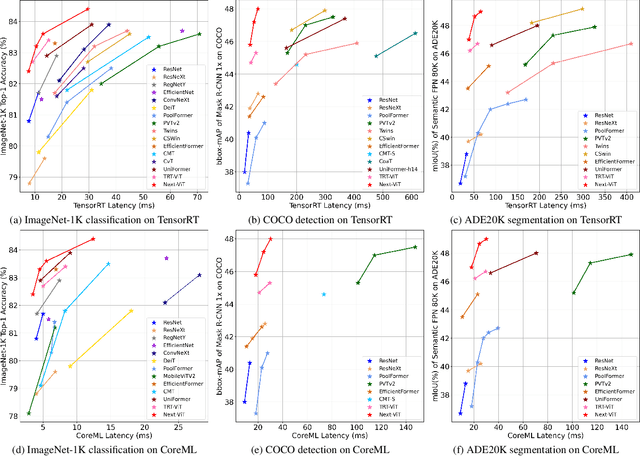
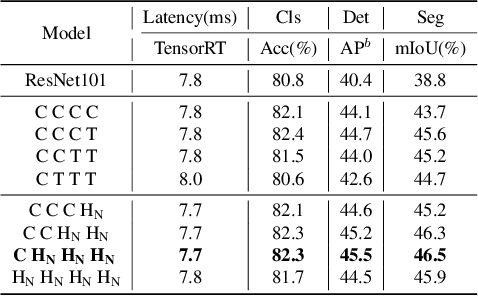
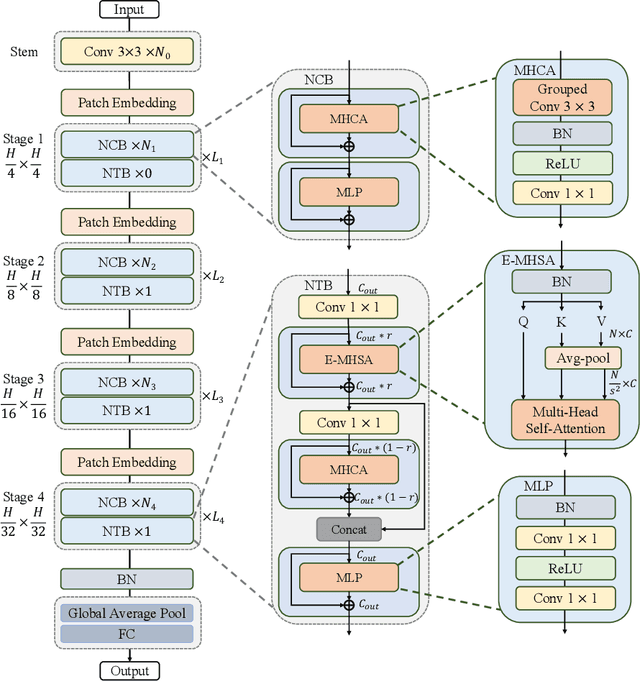
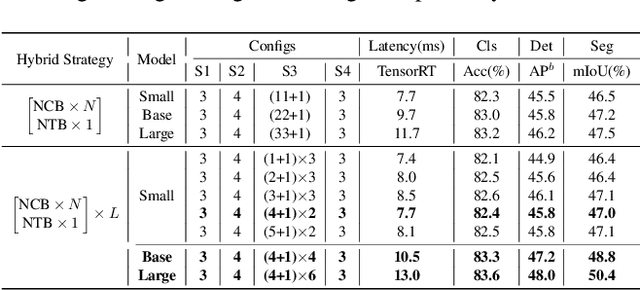
Due to the complex attention mechanisms and model design, most existing vision Transformers (ViTs) can not perform as efficiently as convolutional neural networks (CNNs) in realistic industrial deployment scenarios, e.g. TensorRT and CoreML. This poses a distinct challenge: Can a visual neural network be designed to infer as fast as CNNs and perform as powerful as ViTs? Recent works have tried to design CNN-Transformer hybrid architectures to address this issue, yet the overall performance of these works is far away from satisfactory. To end these, we propose a next generation vision Transformer for efficient deployment in realistic industrial scenarios, namely Next-ViT, which dominates both CNNs and ViTs from the perspective of latency/accuracy trade-off. In this work, the Next Convolution Block (NCB) and Next Transformer Block (NTB) are respectively developed to capture local and global information with deployment-friendly mechanisms. Then, Next Hybrid Strategy (NHS) is designed to stack NCB and NTB in an efficient hybrid paradigm, which boosts performance in various downstream tasks. Extensive experiments show that Next-ViT significantly outperforms existing CNNs, ViTs and CNN-Transformer hybrid architectures with respect to the latency/accuracy trade-off across various vision tasks. On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation under similar latency. Meanwhile, it achieves comparable performance with CSWin, while the inference speed is accelerated by 3.6x. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency. Code will be released recently.
Parallel Pre-trained Transformers (PPT) for Synthetic Data-based Instance Segmentation
Jun 22, 2022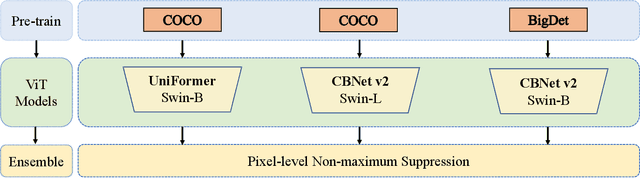
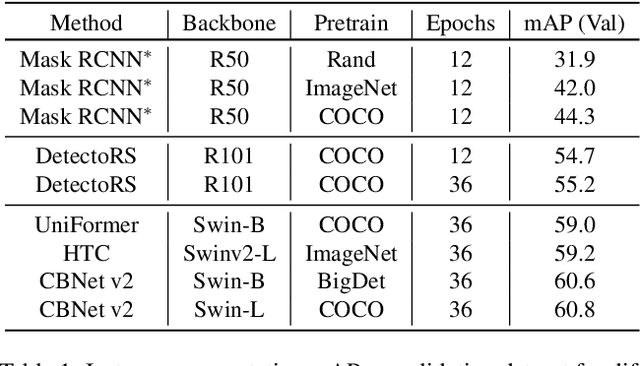
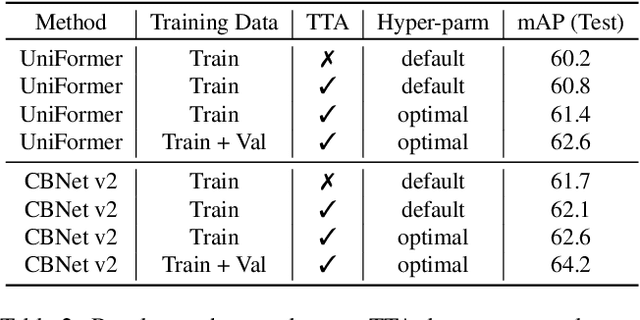
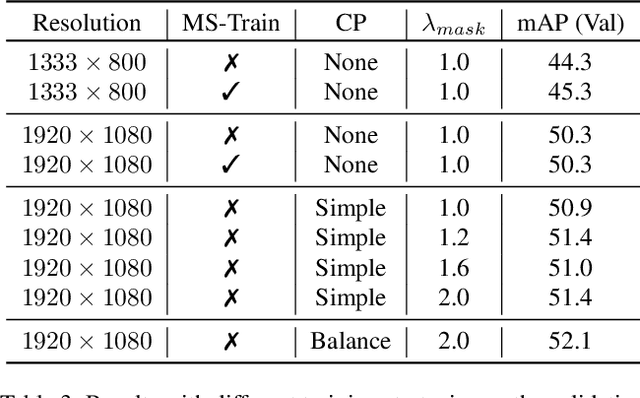
Recently, Synthetic data-based Instance Segmentation has become an exceedingly favorable optimization paradigm since it leverages simulation rendering and physics to generate high-quality image-annotation pairs. In this paper, we propose a Parallel Pre-trained Transformers (PPT) framework to accomplish the synthetic data-based Instance Segmentation task. Specifically, we leverage the off-the-shelf pre-trained vision Transformers to alleviate the gap between natural and synthetic data, which helps to provide good generalization in the downstream synthetic data scene with few samples. Swin-B-based CBNet V2, SwinL-based CBNet V2 and Swin-L-based Uniformer are employed for parallel feature learning, and the results of these three models are fused by pixel-level Non-maximum Suppression (NMS) algorithm to obtain more robust results. The experimental results reveal that PPT ranks first in the CVPR2022 AVA Accessibility Vision and Autonomy Challenge, with a 65.155% mAP.
MoCoViT: Mobile Convolutional Vision Transformer
May 26, 2022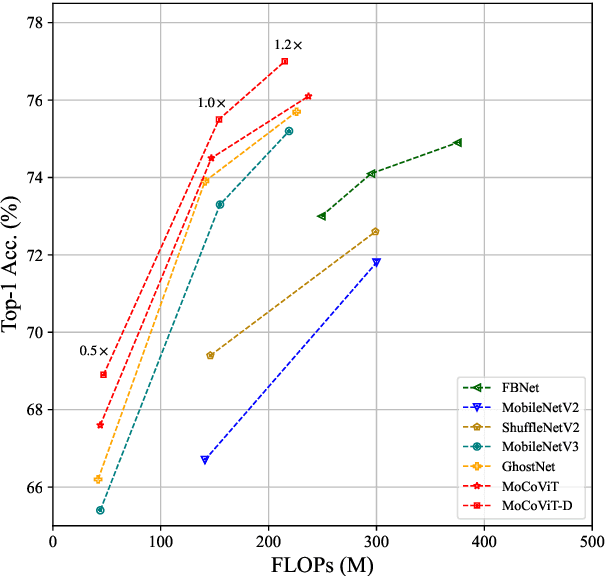
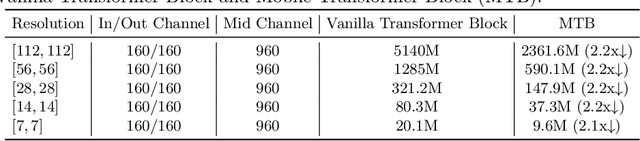
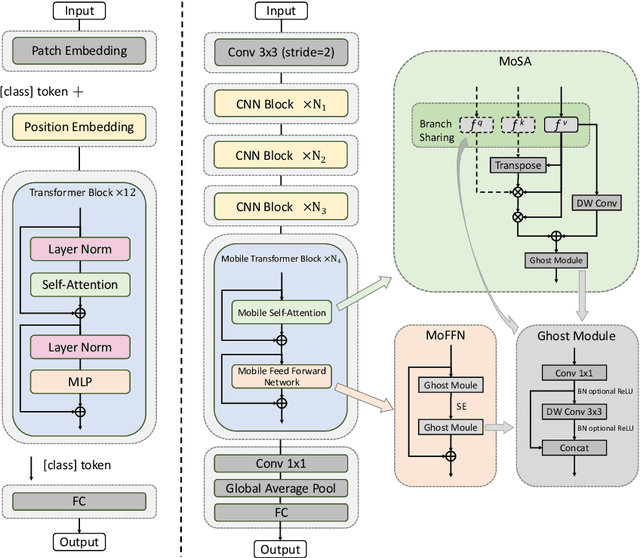
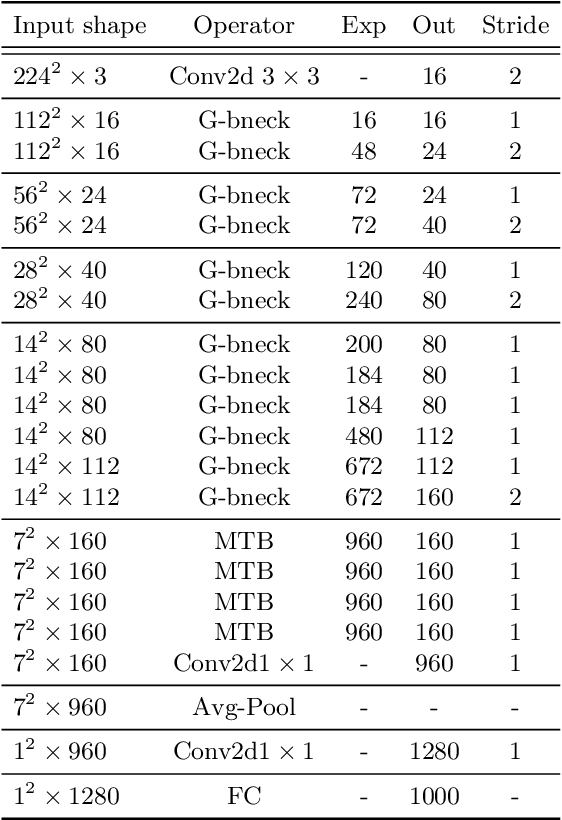
Recently, Transformer networks have achieved impressive results on a variety of vision tasks. However, most of them are computationally expensive and not suitable for real-world mobile applications. In this work, we present Mobile Convolutional Vision Transformer (MoCoViT), which improves in performance and efficiency by introducing transformer into mobile convolutional networks to leverage the benefits of both architectures. Different from recent works on vision transformer, the mobile transformer block in MoCoViT is carefully designed for mobile devices and is very lightweight, accomplished through two primary modifications: the Mobile Self-Attention (MoSA) module and the Mobile Feed Forward Network (MoFFN). MoSA simplifies the calculation of the attention map through Branch Sharing scheme while MoFFN serves as a mobile version of MLP in the transformer, further reducing the computation by a large margin. Comprehensive experiments verify that our proposed MoCoViT family outperform state-of-the-art portable CNNs and transformer neural architectures on various vision tasks. On ImageNet classification, it achieves 74.5% top-1 accuracy at 147M FLOPs, gaining 1.2% over MobileNetV3 with less computations. And on the COCO object detection task, MoCoViT outperforms GhostNet by 2.1 AP in RetinaNet framework.