 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025



This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
Feb 28, 2024



Diffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of the pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available at https://github.com/YanzuoLu/CFLD.
UGC: Unified GAN Compression for Efficient Image-to-Image Translation
Sep 17, 2023



Recent years have witnessed the prevailing progress of Generative Adversarial Networks (GANs) in image-to-image translation. However, the success of these GAN models hinges on ponderous computational costs and labor-expensive training data. Current efficient GAN learning techniques often fall into two orthogonal aspects: i) model slimming via reduced calculation costs; ii)data/label-efficient learning with fewer training data/labels. To combine the best of both worlds, we propose a new learning paradigm, Unified GAN Compression (UGC), with a unified optimization objective to seamlessly prompt the synergy of model-efficient and label-efficient learning. UGC sets up semi-supervised-driven network architecture search and adaptive online semi-supervised distillation stages sequentially, which formulates a heterogeneous mutual learning scheme to obtain an architecture-flexible, label-efficient, and performance-excellent model.
DiffusionEngine: Diffusion Model is Scalable Data Engine for Object Detection
Sep 07, 2023



Data is the cornerstone of deep learning. This paper reveals that the recently developed Diffusion Model is a scalable data engine for object detection. Existing methods for scaling up detection-oriented data often require manual collection or generative models to obtain target images, followed by data augmentation and labeling to produce training pairs, which are costly, complex, or lacking diversity. To address these issues, we presentDiffusionEngine (DE), a data scaling-up engine that provides high-quality detection-oriented training pairs in a single stage. DE consists of a pre-trained diffusion model and an effective Detection-Adapter, contributing to generating scalable, diverse and generalizable detection data in a plug-and-play manner. Detection-Adapter is learned to align the implicit semantic and location knowledge in off-the-shelf diffusion models with detection-aware signals to make better bounding-box predictions. Additionally, we contribute two datasets, i.e., COCO-DE and VOC-DE, to scale up existing detection benchmarks for facilitating follow-up research. Extensive experiments demonstrate that data scaling-up via DE can achieve significant improvements in diverse scenarios, such as various detection algorithms, self-supervised pre-training, data-sparse, label-scarce, cross-domain, and semi-supervised learning. For example, when using DE with a DINO-based adapter to scale up data, mAP is improved by 3.1% on COCO, 7.6% on VOC, and 11.5% on Clipart.
Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning
Dec 08, 2021
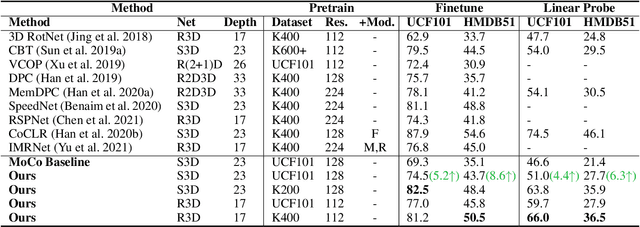

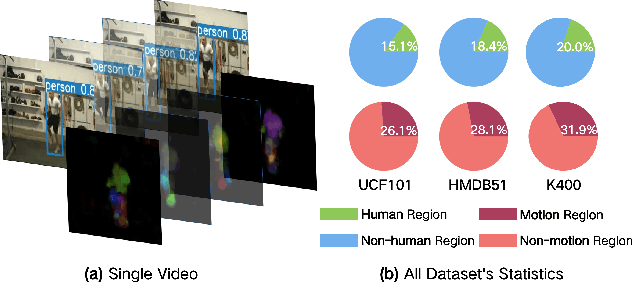
Despite the great progress in video understanding made by deep convolutional neural networks, feature representation learned by existing methods may be biased to static visual cues. To address this issue, we propose a novel method to suppress static visual cues (SSVC) based on probabilistic analysis for self-supervised video representation learning. In our method, video frames are first encoded to obtain latent variables under standard normal distribution via normalizing flows. By modelling static factors in a video as a random variable, the conditional distribution of each latent variable becomes shifted and scaled normal. Then, the less-varying latent variables along time are selected as static cues and suppressed to generate motion-preserved videos. Finally, positive pairs are constructed by motion-preserved videos for contrastive learning to alleviate the problem of representation bias to static cues. The less-biased video representation can be better generalized to various downstream tasks. Extensive experiments on publicly available benchmarks demonstrate that the proposed method outperforms the state of the art when only single RGB modality is used for pre-training.