 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025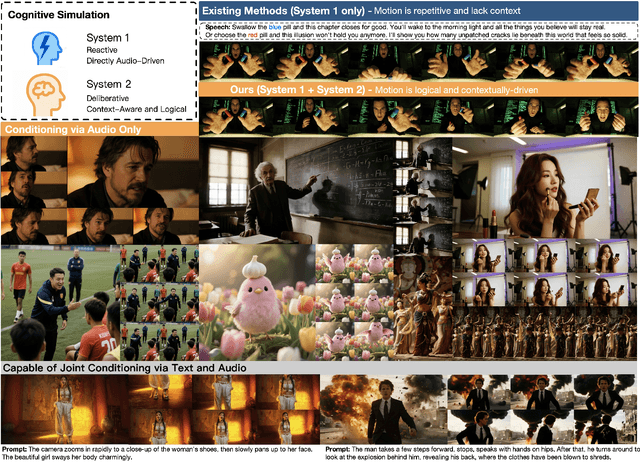
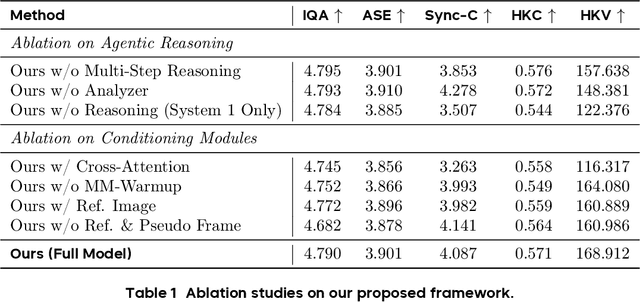
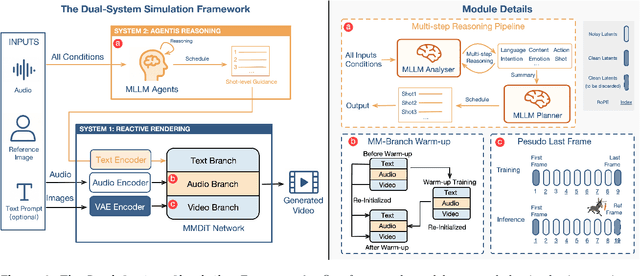

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
SwiftAvatar: Efficient Auto-Creation of Parameterized Stylized Character on Arbitrary Avatar Engines
Jan 19, 2023The creation of a parameterized stylized character involves careful selection of numerous parameters, also known as the "avatar vectors" that can be interpreted by the avatar engine. Existing unsupervised avatar vector estimation methods that auto-create avatars for users, however, often fail to work because of the domain gap between realistic faces and stylized avatar images. To this end, we propose SwiftAvatar, a novel avatar auto-creation framework that is evidently superior to previous works. SwiftAvatar introduces dual-domain generators to create pairs of realistic faces and avatar images using shared latent codes. The latent codes can then be bridged with the avatar vectors as pairs, by performing GAN inversion on the avatar images rendered from the engine using avatar vectors. Through this way, we are able to synthesize paired data in high-quality as many as possible, consisting of avatar vectors and their corresponding realistic faces. We also propose semantic augmentation to improve the diversity of synthesis. Finally, a light-weight avatar vector estimator is trained on the synthetic pairs to implement efficient auto-creation. Our experiments demonstrate the effectiveness and efficiency of SwiftAvatar on two different avatar engines. The superiority and advantageous flexibility of SwiftAvatar are also verified in both subjective and objective evaluations.
Learning Rate Dropout
Dec 05, 2019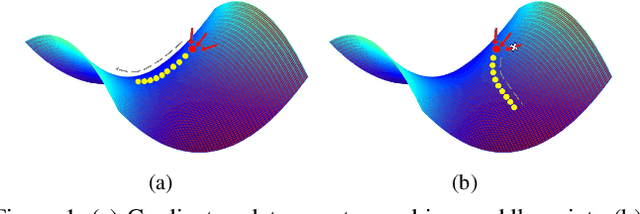

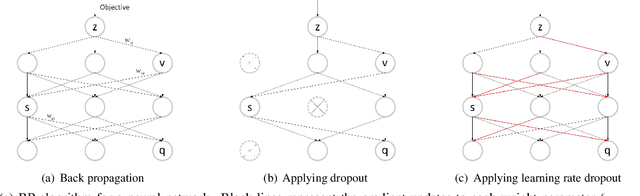
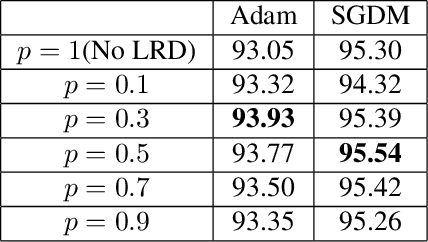
The performance of a deep neural network is highly dependent on its training, and finding better local optimal solutions is the goal of many optimization algorithms. However, existing optimization algorithms show a preference for descent paths that converge slowly and do not seek to avoid bad local optima. In this work, we propose Learning Rate Dropout (LRD), a simple gradient descent technique for training related to coordinate descent. LRD empirically aids the optimizer to actively explore in the parameter space by randomly setting some learning rates to zero; at each iteration, only parameters whose learning rate is not 0 are updated. As the learning rate of different parameters is dropped, the optimizer will sample a new loss descent path for the current update. The uncertainty of the descent path helps the model avoid saddle points and bad local minima. Experiments show that LRD is surprisingly effective in accelerating training while preventing overfitting.
Noise2Blur: Online Noise Extraction and Denoising
Dec 03, 2019
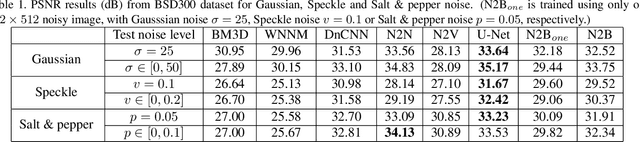
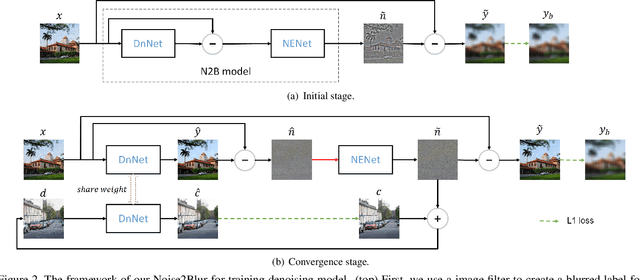
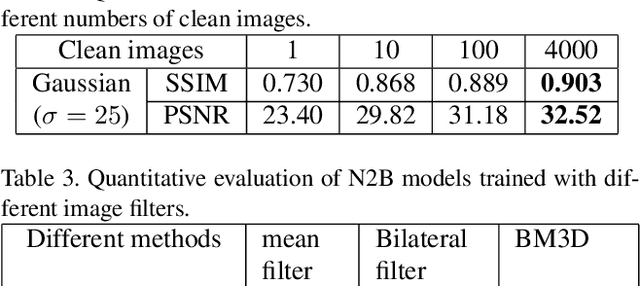
We propose a new framework called Noise2Blur (N2B) for training robust image denoising models without pre-collected paired noisy/clean images. The training of the model requires only some (or even one) noisy images, some random unpaired clean images, and noise-free but blurred labels obtained by predefined filtering of the noisy images. The N2B model consists of two parts: a denoising network and a noise extraction network. First, the noise extraction network learns to output a noise map using the noise information from the denoising network under the guidence of the blurred labels. Then, the noise map is added to a clean image to generate a new ``noisy/clean'' image pair. Using the new image pair, the denoising network learns to generate clean and high-quality images from noisy observations. These two networks are trained simultaneously and mutually aid each other to learn the mappings of noise to clean/blur. Experiments on several denoising tasks show that the denoising performance of N2B is close to that of other denoising CNNs trained with pre-collected paired data.
Rain O'er Me: Synthesizing real rain to derain with data distillation
Apr 10, 2019

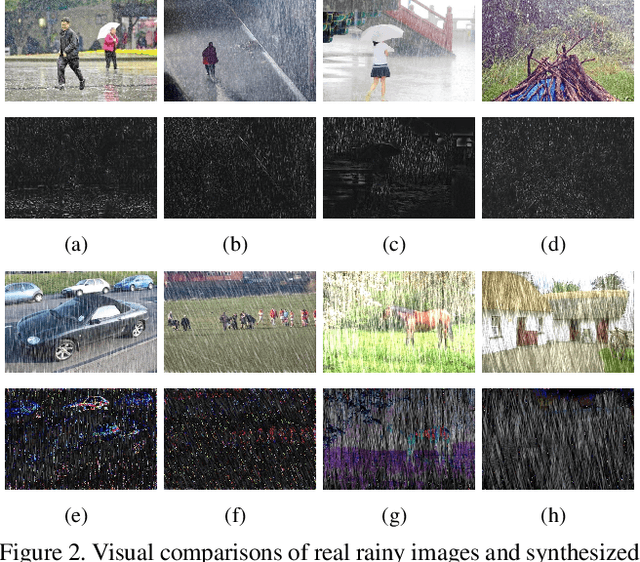
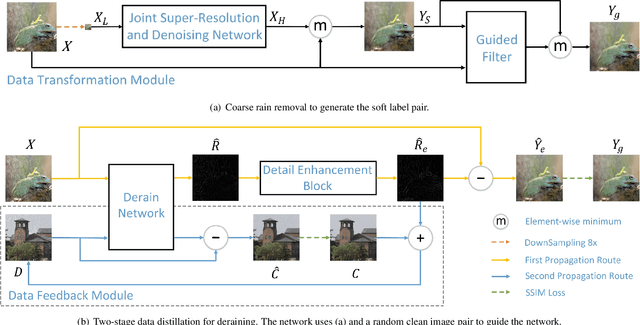
We present a supervised technique for learning to remove rain from images without using synthetic rain software. The method is based on a two-stage data distillation approach: 1) A rainy image is first paired with a coarsely derained version using on a simple filtering technique ("rain-to-clean"). 2) Then a clean image is randomly matched with the rainy soft-labeled pair. Through a shared deep neural network, the rain that is removed from the first image is then added to the clean image to generate a second pair ("clean-to-rain"). The neural network simultaneously learns to map both images such that high resolution structure in the clean images can inform the deraining of the rainy images. Demonstrations show that this approach can address those visual characteristics of rain not easily synthesized by software in the usual way.